



Small -> Big -> Massive — VM to BM to Serverless Spark-based Data Science
Last Updated on July 20, 2023 by Editorial Team
Author(s): Deepak Sekar
Originally published on Towards AI.
Cloud Computing
We have heard about big data platforms supporting ML workloads with distributed computing. But do you always need a big data platform for your data science workloads?
How about the flexibility to build small, scale big and span to every byte of your data?
What does it mean?
Let us understand this with a step by step flow.
Where is the data stored?
Mostly on the following two
- Data Lakes and
- Data Warehouses
Where is the Data Engineering done?
- On-prem servers
- Virtual machines in the cloud
- Bare metal machines in the cloud
- On-prem big data clusters
- Cloud-based big data clusters
Where is Data Science done?
- On-prem servers
- Virtual machines in the cloud w/o GPU
- Bare metal machines in the cloud w/o GPU
- On-prem big data clusters
- Cloud-based big data clusters
- On-prem data science environment
- Cloud-based data science environment
So it looks like there are cases where a small environment meets the needs and some instances where big clusters are required.
Open-source methods to analyze/ manipulate data
Small Data -> Moderately big Data -> Big Data
is achieved using
Pandas -> Dask -> PySpark
Why can’t the same logic be possible for scaling compute for Data Engineering/ Data Science workloads?
VM -> BM -> Spark/ Serverless Spark
How difficult is it building/ maintaining a Spark Cluster? Take a guess? Serverless/ Managed Spark Cluster is the answer
Oracle’s Cloud Infrastructure Data Science and Data Flow provides the flexibility to move from VM -> BM -> Serverless Spark (Oracle Cloud Infrastructure Data Flow)
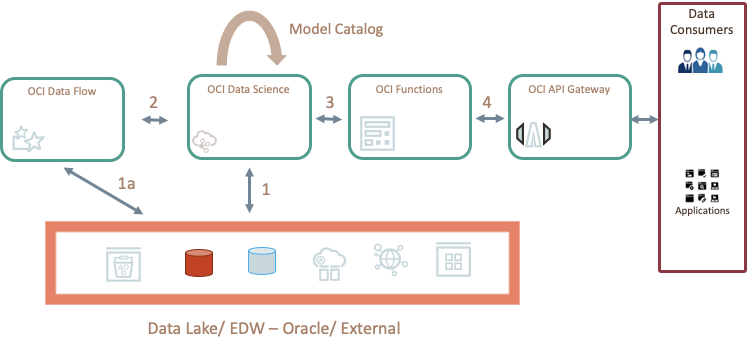
How is this achieved?
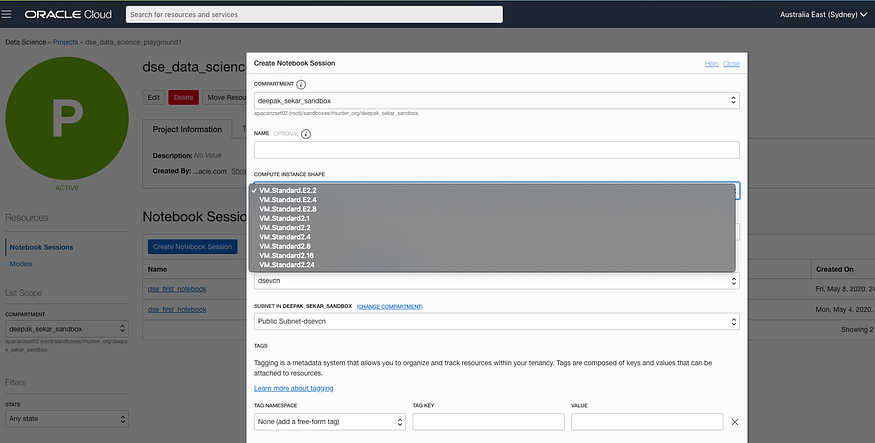
- You can select the shape of computing when you start
- Model/ analyze data using the VM/ BM and access the data from the data lake (OCI Object Storage), Oracle databases or External Data Sources
- Hand-off to a serverless spark cluster (OCI Data Flow) from within OCI Data Science to run a spark application
- Access the results/ model back in the Data Science Environment
- Deploy the model using OCI Functions and API Gateway (if required)
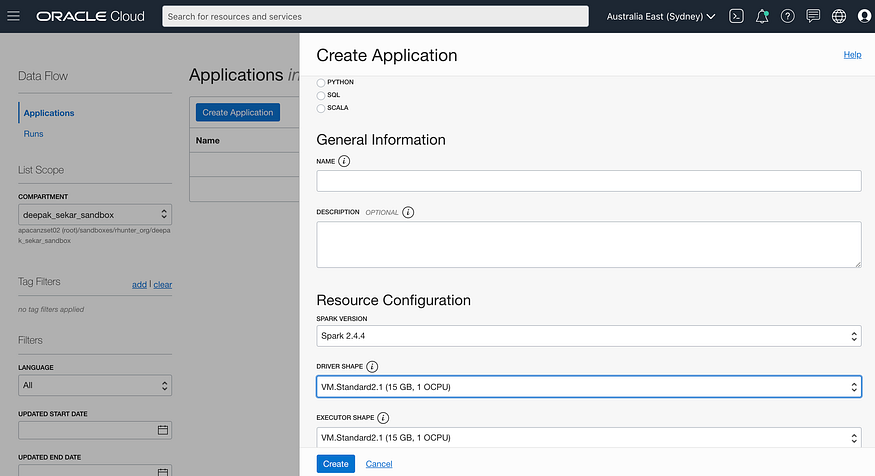
OCI Data Flow supports
two types of templates:
- The
standard_pysparktemplate, which is for standard PySpark job - The
sparksqltemplate which is for the spark SQL job
Hand-off to OCI Data Flow from OCI Data Science
from ads.dataflow.dataflow import DataFlowdata_flow = DataFlow()import uuidpyspark_file_path = f"/home/datascience/dataflow/example-{str(uuid.uuid4())[-6:]}.py"# Object Storage bucketdisplay_name = "<>"
bucket_name = "<>"# Create app config (can choose driver and executor size & num)app_config = data_flow.prepare_app(display_name,bucket_name,pyspark_file_path)app = data_flow.create_app(app_config)app.oci_linkrun_display_name = "sample new run"log_bucket_name = "dataflow-log"#Create run config and run the spark applicationrun_config = app.prepare_run(run_display_name, log_bucket_name)runrun.stats# Run - clickable linkrun.oci_link
If the PySpark script writes the output back to the object storage/ database, then you can access the same after the run.
Welcome to the world of data science done right!
Please don’t forget to clap if you liked this article 🙂
The views expressed are those of the author and not necessarily those of Oracle. You can find me on Medium as Deepak Sekar.
Resources:
5 Different Ways to Build ML Models!
We have come across data science platforms and ML offerings targeted for expert audiences who have Python/ R/…
medium.com
What? How? Why? — In the World of Data Science!
In this article, we will see the three things that matter the most in the Data Science Process
medium.com
- Oracle Cloud Infrastructure Data Flow — https://www.oracle.com/big-data/data-flow/
- Oracle Analytics Cloud (OAC) — https://www.oracle.com/au/business-analytics/analytics-cloud.html
- Oracle Machine Learning (OML)-https://www.oracle.com/database/technologies/datawarehouse-bigdata/machine-learning.html
- Oracle Autonomous Database — https://www.oracle.com/au/database/autonomous-database.html
- Oracle Cloud Infrastructure Data Science — https://www.oracle.com/data-science/cloud-infrastructure-data-science-product.html
- Oracle Cloud Object Storage — https://www.oracle.com/au/cloud/storage/object-storage.html
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

