



Sentiment Analysis performed on Turkey Earthquake Tweets
Last Updated on November 6, 2023 by Editorial Team
Author(s): Claudio Giorgio Giancaterino
Originally published on Towards AI.
Sentiment analysis is a Natural Language Process technique used in order to tag a given text to its sentiment like positive, negative or neutral.
Usually, sentiment analysis is used in Marketing to better consider customer needs, monitor risk insight on what people are thinking about a particular product, and extract information about expected trends in order to improve marketing strategy. In Marketing Insurance, sentiment analysis is used, but not only, it is also useful in risk assessment, because by modelling the sentiment from tweets there is the opportunity to build a risk factor that can be used in premium risk modeling. The following job gives an example of sentiment analysis applied to the Turkey Earthquake Tweets with the use of the TextBlob benchmark tool compared with fine-tuned pre-trained models retrieved from Hugging Face Hub. You can follow the code in this notebook.
What is Hugging Face?
Hugging Face is a platform built in order to democratize artificial intelligence, where data scientists and machine learning engineers can collaborate on models, and datasets, with the opportunity to deploy applications.
Going directly on the job, I’ve retrieved a tweets dataset from Kaggle about the Turkey earthquakes that happened in February 2023.
In the following picture, there are many features except the sentiment labels.

Sentiment analysis with polarity labels can be linked with the text classification task fitting a model on the train set and evaluating its performance on the test set, in order to use it also on other unseen data with the same structure. In this dataset, instead, there aren’t labels to train models, and the idea is to use a tool to generate polarity labels in an automated way, because when the dataset has thousands and thousands of rows a manual labeling activity becomes time-consuming.
There are several packages available to perform sentiment analysis, and the well-known are TextBlob, VADER and Flair. For this job, I’ve selected TextBlob as a benchmark. Then I compared it with results coming from fine-tuned pre-trained Large Language Models (LLMs) retrieved from Hugging Face: cardiffnlp/twitter-roberta-base-sentiment-latest, cardiffnlp/bert-base-multilingual-cased-sentiment-multilingual, philschmid/distilbert-base-multilingual-cased-sentiment-2.
Before going ahead with the models, I come back to the dataset that is composed of 16 variables (including id uploaded as index) and 28844 rows, with some features presenting n/a data and tweets recorded from 07/02/2023 to 26/02/2023. Actually, I’m interested in the following columns “date”, “text” and “user_location” that I used to filter data.
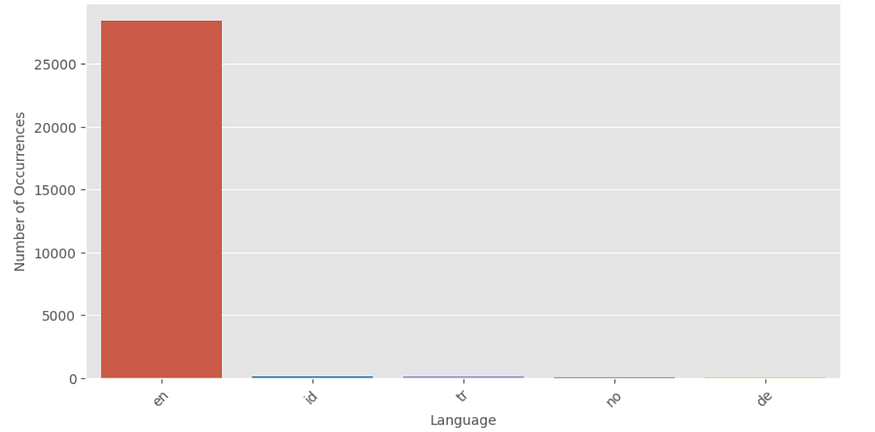
In the next picture, it is possible to see, from the language detection, that tweets are written in English.
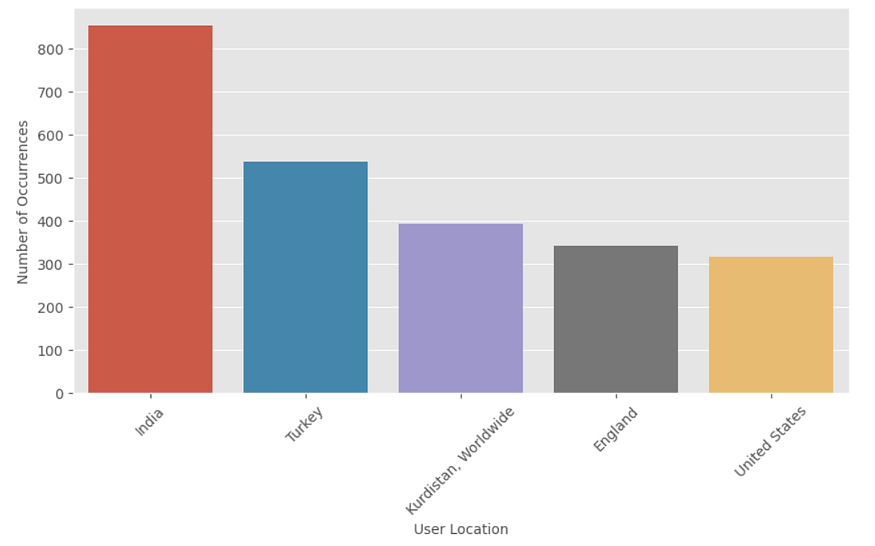
In the following picture is possible to understand the top five provenience of messages by the feature “user_location”, and Turkey covers the second place after India.
At this step, I filtered data df_.query(‘user_location==”Turkey”’) on Turkey, reducing at 538 rows, and after a little cleaning, the dataset was ready to start with sentiment analysis.
The first approach was based on applying TexTBlob as a benchmark tool.
How does TextBlob work?
TextBlob is a Python library with API access for several NLP tasks. TextBlob sentiment analyzer can be used for polarity or for subjectivity. The first one provides a float result that lies in a range [-1,1], with -1 indicating negative sentiment and +1 indicating positive sentiments. In my job, I also used 0 values for neutral sentiments. Subjectivity also provides a float result that lies in a range [0,1]. Subjectivity is generally used for personal opinion, emotion, or judgment. The issue is that TextBlob ignores the words that aren’t in its vocabulary, it takes care about words and phrases that it can apply polarity to and averages to get the final score.
At this point, because I’m not confident about the reliability of using only one tool and without understanding the goodness of results I’ve decided to use advanced tools: Large Language Models (BERT, RoBERTa and DistillBERT) fine-tuned and pre-trained on sentiment analysis and text classification tasks and retrieved from Hugging Face platform.
What is the difference between BERT, RoBERTa and DistillBERT?
BERT stands for Bidirectional Encoder Representation from Transformer and it is a Natural Language Processing model launched by Google researchers in 2018. It is basically an encoder stack of transformer architecture. A transformer architecture is an encoder-decoder network that uses self-attention on the encoder side and attention on the decoder side. The encoder of the transformer is bidirectional which means that it can read a sentence in both directions, from left and right. Given a sentence as an input to the transformer’s encoder, it gets the contextual representation (embedding) of each word in the sentence as an output. The encoder is able to understand the context of each word in the sentence using the multi-head attention mechanism (the way to look at the relation between a word with its neighbours) and returns the contextual representation of each word in the sentence as an output. For this reason, BERT is a context-based embedding model. During the pre-training process, BERT uses two unsupervised learning tasks: Masked Language Modelling (MLM) and Next Sentence Prediction (NSP). The first one randomly masks some words in a sentence and trains the model to predict the masked words based on the context of the surrounding words. The second one trains the model to predict whether two sentences are consecutive or not. BERT used in this job is the fine-tuned version of bert-base-multilingual-cased, on tweets. Instead, the BERT multilingual base model is pre-trained on the largest Wikipedia corpus of multilingual data.
RoBERTa stands for Robustly Optimized BERT Pre-training Approach, developed by researchers at Facebook AI. As well as BERT, it is based on transformer architecture that uses a self-attention mechanism to process input sequences and generate contextualized representations of words in a sentence. Despite BERT, it has been trained on a much larger dataset and uses a dynamic masking technique during training that helps the model learn more robust representations of words. RoBERTa used in this job is the fine-tuned version of twitter-roberta-base-2021–124m, trained on ~124M tweets from January 2018 to December 2021.
DistillBERT is a distilled version of BERT, which means its target is to reduce the large size and enhance the speed of BERT, so it is the smaller and faster version of BERT. DistilBERT uses a similar general architecture as BERT, but with fewer encoder blocks and it uses the knowledge distillation technique during pre-training, which involves training a smaller model to mimic the behavior of a larger model. DistillBERT used in this job is the fine-tuned version of distilbert-base-multilingual-cased, trained on the amazon_reviews_multi dataset.
Let’s have a look at the results
I’ve used 3 polarities: positive, negative and neutral.
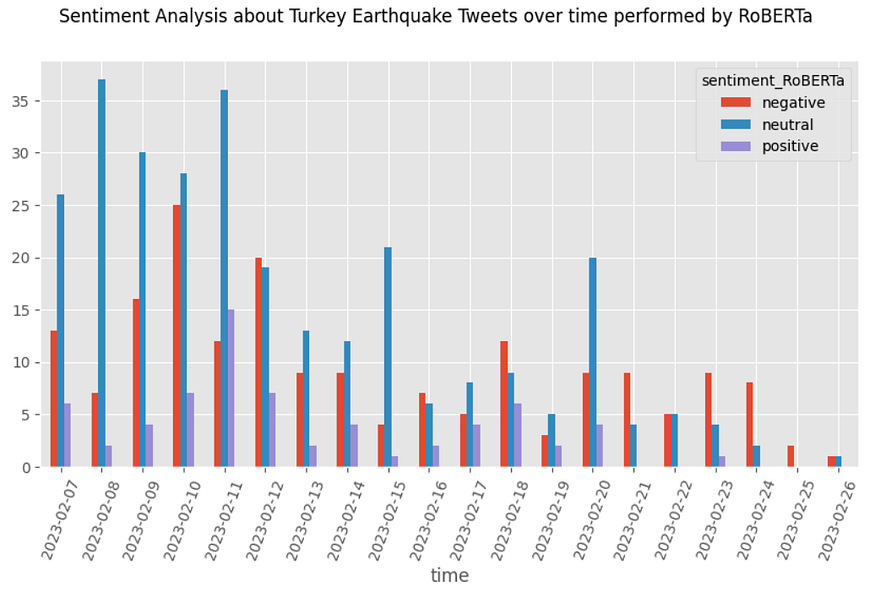
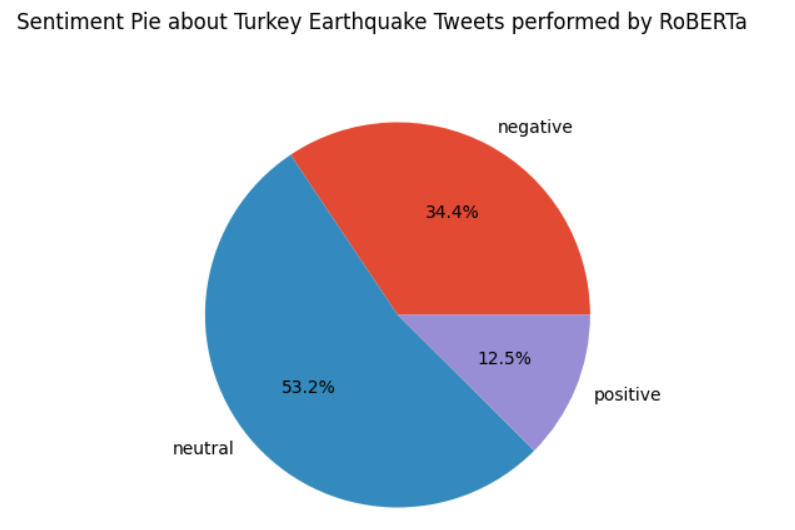
Looking at the first chart with TextBlob results, neutral sentiment is dominant over time from 07/02/2023 to 21/02/2023. Neutral sentiment decreased using RoBERTa, but anyway, it is relevant with 53,2 % on total tweets, despite 55 % using TextBlob.
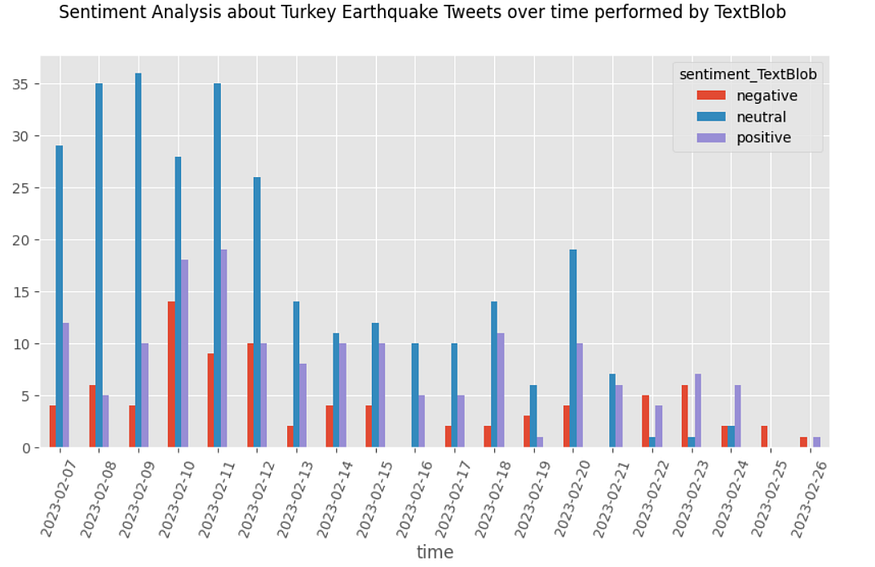

Excluding the neutral sentiment, one issue that catches the eye with TextBlob is that the negative sentiment fills only 15.6% against the positive sentiment, equal to 29.4%, while with the LLMs, the negative sentiment wins over the positive feeling. Which tools can we trust? We are certainly dealing with an event that generates fear, agitation…typical negative emotions, therefore, the results provided by the LLMS are more plausible than the benchmark.
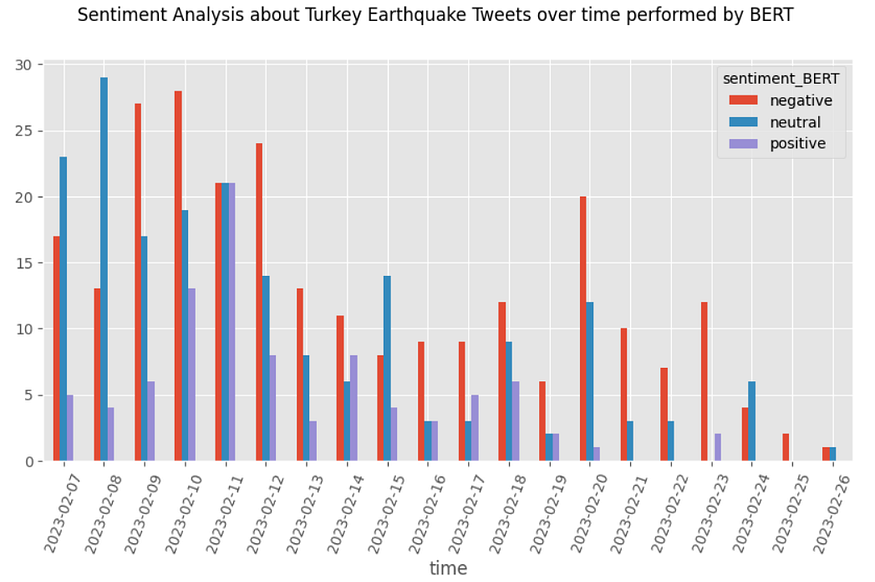
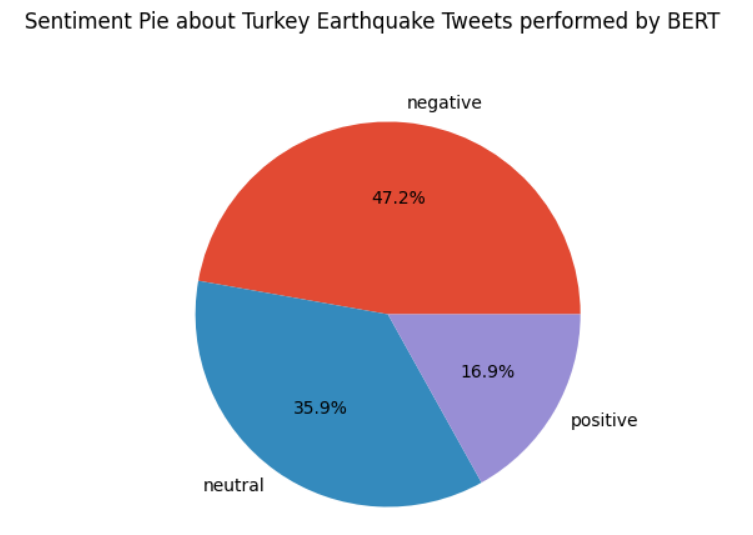
Looking at the results from BERT, neutral sentiment decreases, filling 35,9%. It seems able to allocate much more extreme polarities than RoBERTa, with 47,2% negative and 16,9% positive. Negative sentiment wins over time with BERT. Instead, neutral sentiment wins only on 07/02/2023, 08/02/2023, and 15/02/2023. Meanwhile, on 11/02/2023, there is an equal distribution of sentiments between tweets.
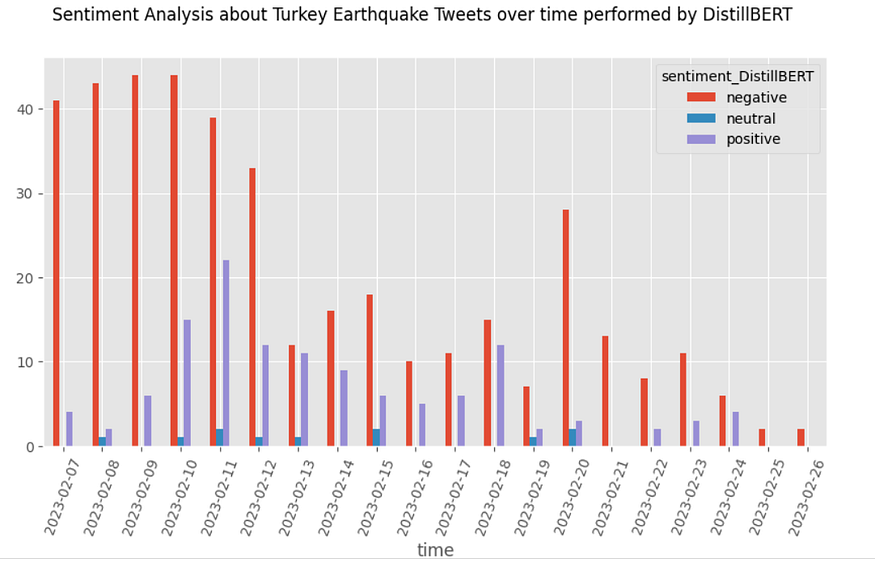
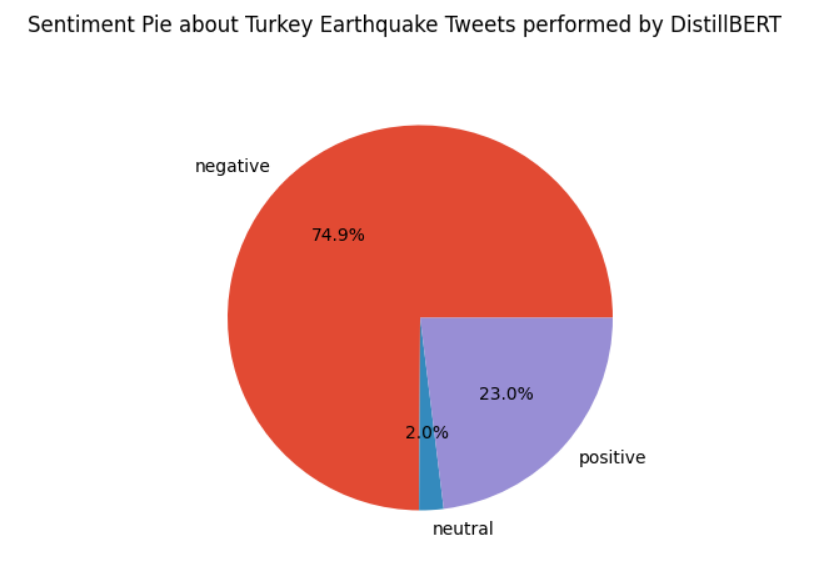
DistillBERT is the last tool used to perform sentiment analysis, and in this situation, neutral sentiment has practically disappeared with only 2%. The negative polarity is huge over time, with 74.9%. Also, in this situation, I’m not confident in the results because, on one side, the biggest negative polarity is coherent with the event; on the other side, tweets are difficult in the allocation of positive/negative, and the presence of a lot of neutral sentiment can be plausible.
Final remarks
With the advent of big data, it has become a normal practice for companies to use social networks for purposes related to sentiment analysis, always with respect to privacy, in order to take into account market trends. In this case, I used a dataset relating to an extreme event and, therefore, with little amount of data available.
Fine-tuned pre-trained models show interesting results, overcoming traditional approaches and, on one side, saving computational time employed in the manual labeled activity, on the other hand, they give good results that can be trusted much more fine-tuning pre-trained models on their own custom data. I want to remark on this aspect because surely Companies can follow this way in their strategy.
References
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

