


 in Python : Advanced Concepts")
Regular Expressions (RegEx) in Python : Advanced Concepts
Last Updated on June 13, 2022 by Editorial Team
Author(s): Hrishikesh Patel
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Regular Expressions (RegEx) in Python: Advanced Concepts
Add advanced skills to your RegEx skillset
Motivation
Many websites ask for a password with at least eight characters and special requirements. But have you ever wondered how websites validate your passwords against these requirements? The answer is Regular Expression or RegEx. The regex is a crucial skill to learn for any programmers and data scientists to deal with text (strings). You can also use it to clean text data in natural language processing!
In this story, I will cover some advanced regex skills on top of basic regex, which I introduced in my following story. I highly recommend brushing up on your basics before delving deep into advanced regex.
Regular Expression (RegEx) in Python : The Basics
Summary of Regex Metacharacters
I introduced metacharacters for words, digits, and space characters in the above-mentioned story covering basic regex. The following table introduces other important metacharacters.

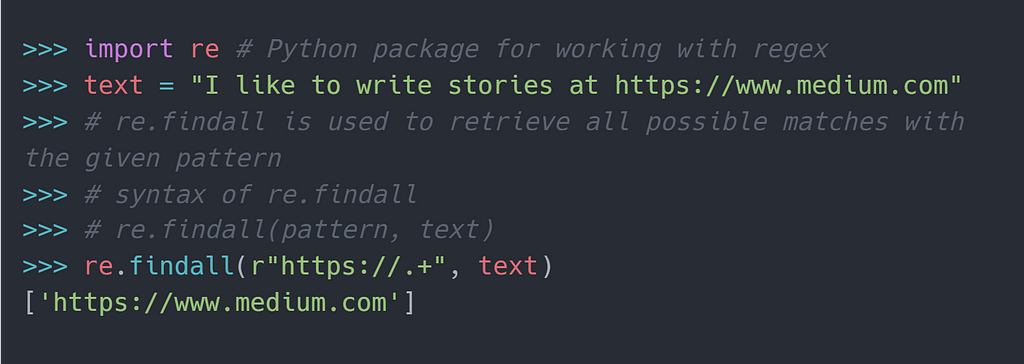
1. Match any character with. (period)
The period . in the regex pattern can be used to match any character except for a new line character \n . As shown in the following figure, . has been used along with a quantifier + to match anything after the https:// .
2. Specify the location of search using ^ (caret) and $ (dollar)
In the following image, we extract sequels of Spiderman movies. However, it gives results from the entire text. What if we want the pattern to be matched only at the beginning or at the end of the text?

Specifying ^ before the pattern will look for a potential match at the beginning of the text as indicated in the figure below.

Similarly, specifying $ at the end of the pattern will look for a potential match at the end of the text as shown below.

3. OR operator | (pipe)
Let’s consider we have two patterns — A and B; we want to match either of the patterns. This can be done by using A|B. In other words, A|B means to match anything from A or B. This can also be extended to more than two patterns e.g. A|B|C|D|E

4. Specify character range using [ ] (rectangular brackets)
To extract a word character, we can use \w . But what if we want to match only uppercase letters? We can specify such character range inside [] . e.g., [A-Z] means match any single uppercase letter. By quantifying using plus sign like [A-Z]+ , more than one uppercase letter can be matched.

A few examples of character ranges
1. [A-Z]: Match any uppercase letter
2. [A-Za-z]: Match any uppercase or lowercase letter
3. [0–9]: Match any digit
4. [!@#]: Match any character from !, @, or #
Read more about the character range here.
Note: Inside the [], metacharacters such as .*+? etc. have no special meanings. They will be treated literally. Though the special character ^ has a different meaning inside [].
5. Use ^ (caret) inside [ ] to specify opposite character range
We saw using [A-Z] , any uppercase character can be matched. But what if we want to match anything but an uppercase letter? Here, we can use ^ inside the character, range to specify the opposite of the range, e.g. [^A-Z] will match anything except an uppercase letter.

Motivation for Grouping
Let’s extract a website from the given text using a regex pattern. It is straightforward as depicted below.

But sometimes, we might want to extract individual pieces from the matched pattern, e.g., individual website components such as website name, website domain, etc. To achieve that, we can specify groups inside the regex pattern.
1. Grouping using ( ) (parentheses)
Groups can be specified using () . In the following example, we extract pieces of the website using grouping. Sounds very useful, isn’t it?

2. Specify non-capturing groups using (?:)
However, sometimes we want to match specific groups but don’t want to include them in the results. In the below example, we want to match a group (www) but don’t want it in the output. By adding ?: before the grouped pattern, e.g. (?:www) , we can make it a non-capturing group.

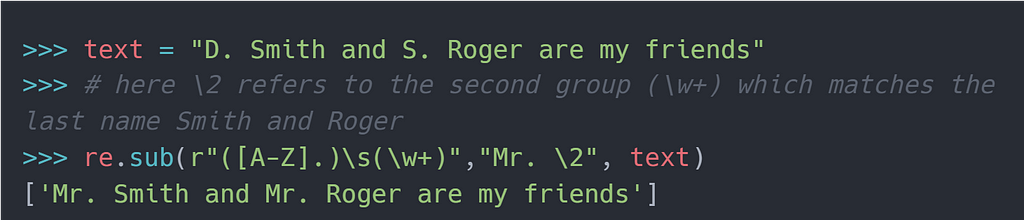
3. Backreferencing the groups
You matched a group using regex. Now you want to reuse the matched portion again in the same pattern. How can we do so? Backreferencing allows reusing matched portions from capturing groups. As shown in the figure below, \1 can refer to the group-1 match and \2 the group-2 match.
Let’s see backreferencing in action. In the following example, we’ll reuse the result from the second group by using \2 .
4. Lookarounds assertions
The exciting part of regex begins! Let’s consider you only want to match a pattern if it’s succeeded or preceded by a specific pattern. In other words, we want to match a pattern only if its left or right part matches a specific sub-pattern. Too much theory! Time for the examples.
4.1 Positive lookahead using (?=)
Consider you have got five tests with their outcomes as shown in the image. You want to only retrieve those tests which passed. In other words, we need to look ahead of Test\d to check if it’s succeeded by the text Passed , then only match the text Test\d .
This is called positive lookahead as we want to get the match only if it is followed by a given sub-pattern. By adding ?= before the sub-pattern, it can be converted to a positive lookahead assertion.

Positive lookahead can be used to check if any prospective password meets the conditions such as minimum characters, special characters, etc.
4.2 Negative lookahead using (?!)
Now we want to retrieve those tests not followed by the text Passed . This is an example of negative lookahead as we don’t want a specific sub-pattern (here Passed) to be followed by something (here Test\d ).
The construct for negative lookahead includes ?! before the sub-pattern.

4.3 Positive lookbehind using (?<=)
This is the flip side of positive lookahead. Here we want to match something only if it is preceded by a specific sub-pattern. In the following example, we only want to retrieve a number if it starts with the pound (£).
The positive lookahead construct includes ?<= before the sub-pattern.

4.4 Negative lookbehind using (?<!)
This is the complete opposite of negative lookahead. Here we want to match something only if it is NOT preceded by a specific sub-pattern. In the following example, we want to retrieve a number only if it DOES NOT start with the pound (£).
The negative lookahead construct includes ?<! before the sub-pattern.

Closing remarks
Thanks for reading the story! I hope it has strengthened your regex muscles. Let me close with an exercise question.
Question: How do you validate a password with the following conditions using regex?
Condition1 — It must have at least 8 characters
Condition2— It must have at least one uppercase and one lowercase letter
Condition3— It must have at least one digit
An example of a password matching the above conditions is q1w2eR3T.
Feel free to share your answers in the comments. Follow me on Medium if you’d like more stories like this.
Regular Expressions (RegEx) in Python : Advanced Concepts was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


