



References
Last Updated on July 25, 2023 by Editorial Team
Author(s): Joseph Reddy
Originally published on Towards AI.
Machine Learning, Python
End to End Model of Data Analysis & Prediction Using Python on SAP HANA Table Data
This blog helps to connect with SAP HANA DB (Version 1.0 SPS12) then extracts the data from HANA table/View and analyzes the data using the Python Pandas library. Then you can clean and select independent variables/features data to feed the Machine learning algorithms to predict dependent variables or find insights.
In today’s digital economy, businesses cannot take action on stale insights, thus a true in-memory data platform should support real-time processing for transactions and analytics for all of a company’s data. SAP HANA helps to manage data in a single in-memory platform, so you can take action at the moment. Accelerate the pace of innovation and run live in this new digital economy. SAP HANA Capabilities include database services, advanced analytics processing, app development, data access, administration, and openness.
Python is becoming popular in analytics and data science. It is also portable, free, and easy. Python lets you work quickly and integrate systems more effectively. Python has a large library base that you can use so you don’t have to write your own code for every single thing. There are libraries for regular expressions, documentation-generation, unit-testing, web browsers, threading, databases, CGI, email, image manipulation, and a lot of other functionality.
Scenario: I am taking the state wise startup company’s expenditure (R&D Spend, Administration Spend, and Marketing Spend) and profit data.
The goal is to predict the Profit for the given set of expenditure values. I am not explaining details about the ML Algorithm and the parameter tuning here. I would like to show the end to end process of Data extraction from SAP HANA DB, analyzing, cleaning, feature selection, and applying machine learning model and finally write back the results and ML algorithm performance metrics to the HANA tables.
The linear regression is the most commonly used model in research and business and is the simplest to understand, so using the random forest regression method we will predict the Profit.
The below diagram shows the ML Prediction life cycle and steps followed in the use case.
The basic steps involved in this process are:
1. Check the HANA Table data and analyze it using SQL in HANA Studio/WEB IDE.
(Make sure you have required privileges to do DML operations on the tables in SAP HANA Database.)
2. Import Pyodbc, Pandas, Sklearn, Matplotlib, seaborn libraries in python.
3. Create a connection to the HANA database and execute the required SQL.
4. Extract all the historical data into the data frame object and start analyzing it in Python using pandas.
5. Do the feature engineering, data cleaning and then feed the final set of independent variables to Machine learning algorithm (Random Forest) to predict the dependent variable (Profit).
6. Analyze the Machine learning algorithm metrics and fine-tune for better accuracy by repeating step 5. Store the Machine learning algorithm metrics in log table and also update the predicted value of historical data into the HANA Table.
7. For the new data set, create the python program which reads the new data using the Pyodbc connection and predicts the dependent variable (Profit) and updates the actual transactional table for reporting.
8. Schedule this program and keep monitoring the model metrics and predicted value.
1. Check the HANA Table data and analyze it using SQL
I have created two tables, one contains the actual company wise data which is used to store the transactional data. The second one to store the metrics of the Machine learning algorithm (Ex: MAE, R Squared, MAPE, RMSE, Accuracy, etc.)
Please find the structures of both tables below.
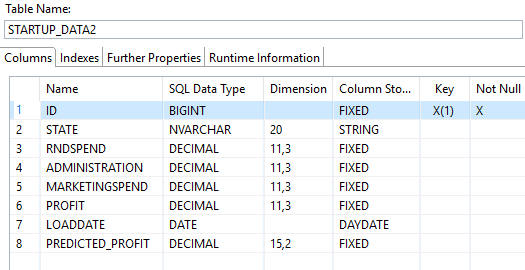
Main transactional data table structure.
ML Metrics table to store the evaluation parameters.

The historical data (which is lesser than the current month) before prediction with state wise expenditure and profit shown below. I added the predicted profit column as well, to store the predicted value by ML Algorithm using python and it is updated as NULL now.
SELECT * FROM “SCHEMA”.”STARTUP_DATA2"

Let us analyze the data using SQL in HANA Studio with available functions, we can find mean, standard deviation, median, max, min and count of nulls using below SQL. (You can try for all the measures)
Select State, sum(Profit), avg(Profit), count(Profit), max(Profit), count( distinct profit) as “unique”, stddev(Profit), min(Profit), median(Profit),
sum(case when Profit IS NULL THEN 1 ELSE 0 END) AS “NO OF NULLS”from “SCHEMA”.”STARTUP_DATA2" group by State order by State;

2. Import Pyodbc, pandas, Sklearn libraries in python
Now I am coming to Python scripting interface (Jupyter or spyder).
Import the required libraries.
PYODBC is an open source Python module that makes accessing ODBC databases simple. It implements the DB API 2.0 specification but is packed with even more Pythonic convenience. Using Pyodbc, you can easily connect Python applications to data sources with an ODBC driver.
Typically, Pyodbc is installed like any other Python package by running:
pip install Pyodbc
from a Windows DOS prompt or Unix shell.
To install this package with Conda run:
conda install -c anaconda pyodbc
For more information on Pyodbc, see the Github Pyodbc Wiki.
Seaborn: Seaborn is a graphics library built on top of Matplotlib. It allows to make your charts prettier and facilitates some of the common data visualization needs
Pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
Numpy: NumPy is the fundamental package for scientific computing with Python. Besides its obvious scientific uses, NumPy can also be used as an efficient multi-dimensional container of generic data
Sklearn: Scikit-learn provides a range of supervised and unsupervised learning algorithms via a consistent interface in Python. It features various classification, regression and clustering algorithms including support vector machines, random forests, gradient boosting, k-means and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy
3. Create a connection to the HANA database and execute the required SQL.
Establish the connection and once a connection has been established, your application can execute selects, inserts, or other ODBC operations supported by your driver and database.
conn = pyodbc.connect(‘DRIVER={HDBODBC};SERVERNODE=10.xx.xxx.xx:30115;SERVERDB=ED1;UID=USERID;PWD=PASSWORD’)#Open connection to SAP HANA and check for count of records.# check if table has entriescursor = conn.cursor()sql_query1 = ‘SELECT count(*) FROM SCHEMA.STARTUP_DATA2’dcount = pd.read_sql(sql_query1, conn)dcountprint (‘Table exists and contains’, dcount.head(1), ‘records’ )
4. Extract the data into a data frame object and start analyzing it in Python using pandas
Execute the Select SQL and read the data and save it to the data frame. Once you get the data into the data frame, you can apply all statistical functions to analyze the data as shown below.
#querying the sap hana db data and store in dataframesql_query2 = ‘SELECT * FROM SCHEMA.STARTUP_DATA2’df = pd.read_sql(sql_query2, conn)df.head()#USING GROUP BY CLAUSE TO ANALYZE THE DATAdf1.groupby(‘STATE’).agg({‘PROFIT’:[‘sum’,’mean’,’count’,’max’,’std’,’min’,’median’]}).round(0)

5. Do the feature engineering, data cleaning, feed the final set of independent variables to Machine learning algorithm (Random Forest) to predict a dependent variable
Check for the missing values or nulls using the functions and replace the values with mean/mode accordingly.
For example, I have two empty values in the Rnd Spend column, so replacing with Mean/Median value. If the column is having more null values, then you can drop the column form the analysis.
Encode the nominal values, for example, State has 3 unique values (‘New York’,’California’,’Florida’) replacing them with 0,1,2 codes using the map function
Map ({‘New York’:0,’California’:1,’Florida’:2})
Now find the correlation between the dependent variable and independent variables to finalize the final independent variables/features for prediction. After observing the data choosing (R&D Spend, Administration Spend, and Marketing Spend) as independent variables and profit as a dependent variable.
Now I am using random forest regression to predict the profit.
Random forests or random decision forests are an ensemble learning method for classification and regression (and other tasks) which operates by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees. Random forests are bagged decision tree models that train on a subset of features on each split (in each iteration).


6.Store the Machine learning algorithm metrics in log table and also update the predicted value into the HANA Table
Using the insert and update statements you can send the data back to the database tables (Ex: ML Metrics and Predicted values). Take care of the primary key while doing insertions.

Check the data in the SAP HANA table to see the updated values in the predicted profit column.
7. For the new data set, create the python program which reads the new data using Pyodbc connection and predicts the dependent variable (Profit) and updates the actual transactional table for reporting
In business, new transactional data will be flowing into the Tables/data warehouse. (In my case SAP HANA SQL data warehouse). For the new data set, suppose you want to know what could be the profit if I spend “X” expenditure for next month.
Analyze whether this cost increase/decrease gives you a return on investment/profit. Then,
Create the Python script in which you perform the following tasks
· fetch the new dataset and process it through the predictor/model
· Update predicted value back to the DB.
· Schedule this python script using Windows Scheduler/ python scheduler
8. Schedule this program and keep monitoring the model metrics and predicted value using HANA Models/reports
You can schedule the Python script using Windows Scheduler/ using the scheduler as shown below.
# sample piece of code$ pip install scheduleimport scheduleimport timedef predict_job(x,y,z):Y_pred = rf.predict([[x,y,z]])print(“Predicted Value is”, Y_pred)#@daily scheduleschedule.every().day.at(“10:30”).do(predict_job)schedule.every().monday.do(predict_job)while True:schedule.run_pending()time.sleep(1)
Now in SAP HANA Client tools WEB IDE/ HANA Studio, Create the HANA model to join the main transactional data with dimension tables like (Time, Location) for reporting purposes.
State wise Actual Vs Predicted Profit Comparison Chart.
When using Python IDE’s such as Jupyter, the data is persisted to the client with the above approach and this means more processing time when you have large data set, which leads to drop the productivity of Data Scientists.
This is where the SAP HANA Data Frame can add real value to a Data Scientist’s work. More features and capabilities are included in SAP HANA 2.0 SPS03 Version to analyze/address the data science use cases with Python driver (hdbcli) and then the Python Client API for machine learning algorithms.
Please find the python code in GitHub for reference
https://github.com/JOSEPHREDDY07/Linear-regression-with-SAP-HANA-DB-Integration
https://blogs.sap.com/2018/04/06/whats-new-in-sap-hana-2.0-sps-03-by-the-sap-hana-academy/
https://datatofish.com/python-script-windows-scheduler/
https://github.com/dbader/schedule
https://blogs.sap.com/2018/04/20/enhancements-to-external-machine-learning-in-sap-hana-2.0-sps-03/
https://towardsdatascience.com/why-random-forest-is-my-favorite-machine-learning-model-b97651fa3706
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

