



Pyspark Kafka Structured Streaming Data Pipeline
Last Updated on July 21, 2023 by Editorial Team
Author(s): Vivek Chaudhary
Originally published on Towards AI.
Programming
The objective of this article is to build an understanding to create a data pipeline to process data using Apache Structured Streaming and Apache Kafka.
Business Case Explanation:
Let us consider a store that generates Customer Invoices and those Invoices come to an integrated platform in a real-time fashion to inform the customer how much “Edge Reward” points they have earned on their shopping.
Invoices from various stores across the City New Delhi travel to Kafka Topic in a real-time fashion and based on total shopping amount, our Kafka consumer calculates the Edge Points and sends a notification message to the customer.
- Invoice Dataset
Invoice Data is generated in JSON format. For the ease of understanding, I have not created a nested dataset.
{“BillNo”:”93647513",”CreatedTime”:1595688902254,”StoreID”:”STR8510",”PaymentMode”:”CARD”,”CustomerCardNo”:”5241-xxxx-xxxx-1142",”ItemID”:”258",”ItemDescription”:”Almirah”,”ItemPrice”:1687.0,”ItemQty”:1,”TotalValue”:1687.0}
{“BillNo”:”93647514",”CreatedTime”:1595688901055,”StoreID”:”STR8511",”PaymentMode”:”CARD”,”CustomerCardNo”:”5413-xxxx-xxxx-1142",”ItemID”:”259",”ItemDescription”:”LED”,”ItemPrice”:1800.0,”ItemQty”:2,”TotalValue”:3900.0}
{“BillNo”:”93647515",”CreatedTime”:1595688902258,”StoreID”:”STR8512",”PaymentMode”:”CARD”,”CustomerCardNo”:”5346-xxxx-xxxx-1142",”ItemID”:”257",”ItemDescription”:”AC”,”ItemPrice”:2290.0,”ItemQty”:2,”TotalValue”:4580.0}
2. Data Producer:
Invoice Data is sent to Kafka topic: ADVICE

3. Data Consumer:
import findspark
findspark.init(‘’)
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col, expr
from pyspark.sql.types import StructType, StructField, StringType, LongType, DoubleType, IntegerType, ArrayTypeprint(‘modules imported’)spark= SparkSession \
.builder.appName(‘Kafka_read_mongo’) \
.master(“local”) \
.config(“spark.streaming.stopGracefullyOnShutdown”, “true”) \
.config(“spark.jars.packages”,”org.apache.spark:spark-sql-kafka-0–10_2.11:2.3.3") \
.getOrCreate()schema = StructType([
StructField(“BillNo”, StringType()),
StructField(“CreatedTime”, LongType()),
StructField(“StoreID”,StringType()),
StructField(“PaymentMode”, StringType()),
StructField(“CustomerCardNo”, StringType()),
StructField(“ItemID”, StringType()),
StructField(“ItemDescription”, StringType()),
StructField(“ItemPrice”, DoubleType()),
StructField(“ItemQty”, IntegerType()),
StructField(“TotalValue”, DoubleType())])print(‘Now time to connect to Kafka broker to read Invoice Data’)kafka_df = spark.readStream.format(“kafka”) \
.option(“kafka.bootstrap.servers”, “localhost:9092”) \
.option(“subscribe”, “advice”) \
.option(‘startingOffsets’,’earliest’) \
.load()print(‘Create Invoice DataFrames’)
invoice_df=kafka_df.select(from_json(col(“value”).cast(“string”), schema).alias(“value”))print(‘Create Notification DF’)notification_df = invoice_df.select(“value.BillNo”, “value.CustomerCardNo”,“value.TotalValue”).
withColumn(“EarnedLoyaltyPoints”, expr(“TotalValue * 0.2”))print(‘Create Final Dataframe’)#Kafka accepts data in key-value format, below piece of code caters the samekafka_target_df = notification_df.selectExpr(“BillNo as key”,
“””to_json(named_struct(
‘CustomerCardNo’, CustomerCardNo,
‘TotalValue’, TotalValue,
‘EarnedLoyaltyPoints’, TotalValue * 0.2)) as value”””)################tbc##################
readStream()– Spark create Streaming Data Frame through the DataStreamReader interface returned by SparkSession.readStream()
outputMode():
The “Output” is defined as what gets written out to the external storage. The output can be defined in a different mode:
- Complete Mode — The entire updated Result Table will be written to the external storage. It is up to the storage connector to decide how to handle the writing of the entire table.
- Append Mode — Only the new rows appended in the Result Table since the last trigger will be written to the external storage. This is applicable only to the queries where existing rows in the Result Table are not expected to change.
- Update Mode — Only the rows that were updated in the Result Table since the last trigger will be written to the external storage. Note that this is different from the Complete Mode in that this mode only outputs the rows that have changed since the last trigger. If the query doesn’t contain aggregations, it will be equivalent to Append mode.
#Note: In our use case we are using Append Mode, as the requirement of the use case is such.
4. Sending Notification:
As we do not have the infrastructure to send text messages to customers, so this particular functionality is catered by sending a JSON message to another Kafka topic: NOTIFICATION , assuming that another downstream pipeline reads the messages from the topic and notify customers regarding the Earned Loyalty Points.
#################continuing#################print(‘writing to notification topic’)#At this particular moment we are able to generate the notification message to be sent to consumer with necessary details such as CardNo, Total Shopping Amount and Reward points earned.#notification_writer_query = kafka_target_df \
.writeStream \
.queryName(“Notification Writer”) \
.format(“kafka”) \
.option(“kafka.bootstrap.servers”, “localhost:9092”) \
.option(“topic”, “notification”) \
.outputMode(“append”) \
.start()notification_writer_query.awaitTermination()
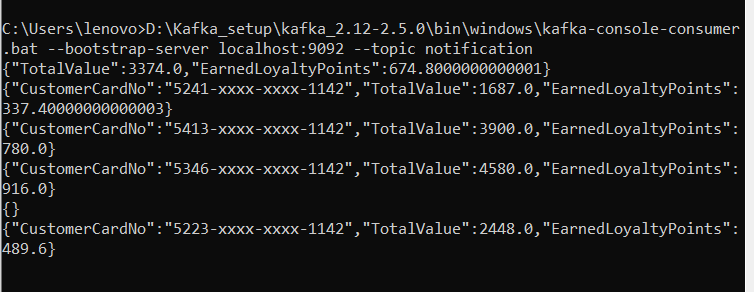
Notification messages are available on the topic.
Here we are done with the approach to design a basic application to process Invoice received from stores, calculate Reward Points, and sending Notification to customers. I hope I can share my knowledge.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

