



PySpark For Beginners
Last Updated on September 22, 2022 by Editorial Team
Author(s): Muttineni Sai Rohith
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
PySpark is a Python API for Apache Spark. Using PySpark, we can run applications parallelly on the distributed cluster (multiple nodes).
So we will start the theory part first as to why we need the Pyspark and the background of Apache Spark, features and cluster manager types, and Pyspark modules and packages.
Apache Spark is an analytical processing engine for large-scale, powerful distributed data processing and machine learning applications. Generally, Spark is written in Scala, but for industrial adaption, Python API — PySpark is released to use spark with Python. In real-time, PySpark is used a lot in the machine learning & Data scientists community; Spark runs operations on billions and trillions of data on distributed clusters 100 times faster than the traditional python applications.
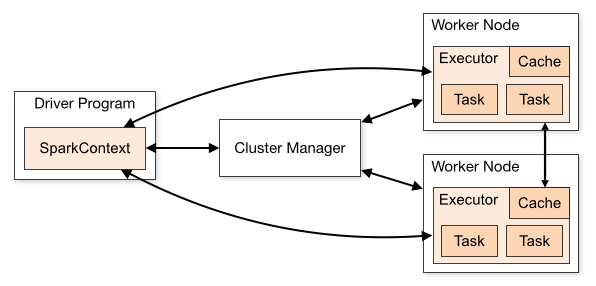
Pyspark Architecture
Apache Spark works in a master-slave architecture where the master is called “Driver” and slaves are called “Workers”. Spark Driver creates a spark context that serves as an entry point to the application, and all operations run on the worker nodes, and resources are managed by the cluster manager.
Cluster Manager Types
The system currently supports several cluster managers besides, we can also run spark locally on our desktop/system:
- Standalone — a simple cluster manager included with Spark that makes it easy to set up a cluster.
- Apache Mesos — a general cluster manager that can also run Hadoop MapReduce and service applications. (Deprecated)
- Hadoop YARN — the resource manager in Hadoop 2 and 3. Mostly used cluster Manager
- Kubernetes — an open-source system for automating deployment, scaling, and management of containerized applications.
Pyspark conf, Pyspark context, and Pyspark session:
Pyspark conf: The SparkConf offers configuration for any Spark application. To start any Spark application on a local Cluster or a dataset, we need to set some configuration and parameters, and it can be done using SparkConf.
Features of Pyspark conf:
- set(key, value) — Set a configuration property.
- setMaster(value) — Set master URL to connect to.
- setAppName(value) — Set application name.
- get(key,defaultValue=None) — Get the configured value for some key, or return a default otherwise.
- setSparkHome(value) — Set path where Spark is installed on worker nodes.
Pyspark context: SparkContext is the entry point to any spark functionality. When we run any Spark application, a driver program starts, which has the main function and your SparkContext gets initiated here. The driver program then runs the operations inside the executors on worker nodes.
The Spark driver program creates and uses SparkContext to connect to the cluster manager to submit PySpark jobs and know what resource manager to communicate to. It is the heart of the PySpark application.
We can create only one SparkContext per JVM. In order to create another first, you need to stop the existing one by using stop() method. SparkContext is available in default as ‘sc’. So creating the other variable instead of sc will give an error.
Pyspark session: Since Spark 2.0 SparkSession has become an entry point to PySpark to work with RDD, and DataFrame. Prior to 2.0, SparkContext used to be an entry point. SparkSession is a combined class for all different contexts we used to have prior to 2.0 release (SQLContext and HiveContext e.t.c). Since 2.0 SparkSession can be used in replace with SQLContext, HiveContext, and other contexts defined prior to 2.0.
Though SparkContext used to be an entry point prior to 2.0, It is not completely replaced with SparkSession; many features of SparkContext are still available and used in Spark 2.0 and later. SparkSession internally creates SparkConfig and SparkContext with the configuration provided with it.
We can create as many SparkSession as you want in a PySpark application using either SparkSession.builder() or SparkSession.newSession(). Many Spark session objects are required when you want to keep PySpark tables (relational entities) logically separated.
Creating a SparkSession
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Practice").getOrCreate()
spark

Pyspark Modules and Packages
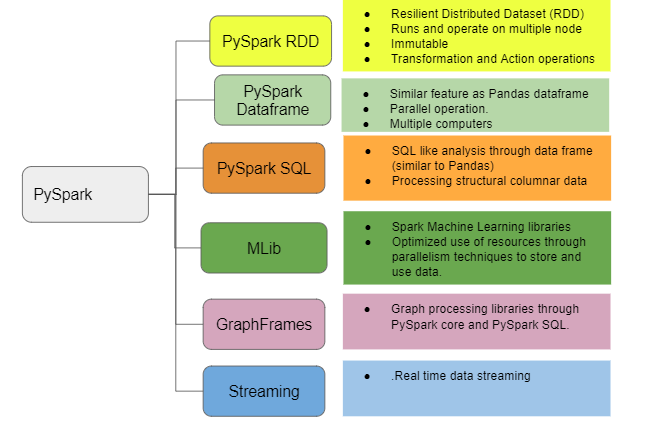
PySpark RDD — Resilient Distributed Dataset:
“Resilient Distributed Datasets (RDD) is a distributed memory abstraction that helps a programmer to perform in-memory computations on a large cluster.” One of the important advantages of RDD is fault tolerance, which means if any failure occurs it recovers automatically. RDD becomes immutable when it is created i.e., it cannot be changed once it is created.
RDD divides data into smaller parts based on a key. The benefit of dividing data into smaller chunks is that if one executor node fails, another node will still process the data. So it is able to recover quickly from any issues as the same data chunks are replicated across multiple executor nodes. RDD provides the functionality to perform functional calculations against the dataset very quickly by binding the multiple nodes.
Pyspark For Beginners| Part-4: Pyspark RDD
Pyspark DataFrame:
DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as structured data files, tables in Hive, external databases, or existing RDDs.
Due to parallel execution on all cores on multiple machines, PySpark runs operations faster than pandas. In other words, pandas DataFrames run operations on a single node, whereas PySpark runs on multiple machines.
Pyspark For Begineers| Part-2: Pyspark DataFrame
Pyspark SQL:
PySpark SQL is a module in Spark which integrates relational processing with Spark’s functional programming API. We can extract the data by using an SQL query language. We can use the queries same as the SQL language.
In other words, Spark SQL brings native RAW SQL queries on Spark, meaning you can run traditional ANSI SQL’s on Spark Dataframe, in the above section of this PySpark tutorial, you will learn in detail about using SQL select, where, group by, join, union e.t.c
PySpark SQL will be easy to use, where you can extend the limitation of traditional relational data processing. Spark also supports the Hive Query Language, but there are limitations of the Hive database. Spark SQL was developed to remove the drawbacks of the Hive database.
Pyspark MLlib:
Apache Spark offers a Machine Learning API called MLlib. PySpark has this machine learning API in Python as well.
It supports different kinds of algorithms, which are mentioned below
— mllib.clustering
— mllib.classification
— mllib.fpm
— mllib.linalg
— mllib.recommendation
— mllib.regression
Pyspark MLlib | Classification using Pyspark ML
Pyspark GraphFrames:
PySpark GraphFrames are introduced in Spark 3.0 version to support Graphs on DataFrame’s. Prior to 3.0, Spark has GraphX library, which ideally runs on RDD and loses all Data Frame capabilities.
GraphFrames is a package for Apache Spark which provides DataFrame-based Graphs. It provides high-level APIs in Scala, Java, and Python. It aims to provide both the functionality of GraphX and extended functionality taking advantage of Spark DataFrames. This extended functionality includes motif finding, DataFrame-based serialization, and highly expressive graph queries.
Pyspark Streaming:
PySpark Streaming is a scalable, high-throughput, fault-tolerant streaming processing system that supports both batch and streaming workloads. It is used to process real-time data from sources like file system folder, TCP socket, S3, Kafka, Flume, Twitter, and Amazon Kinesis to name a few. The processed data can be pushed to databases, Kafka, live dashboards etc.

This is the theoretical part for Pyspark
Go through the content links provided above to understand and implement Pyspark.
Happy Coding…
PySpark For Beginners was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

