



Predicting Churn Rate in a Bank Using Artificial Neural Network with Keras
Last Updated on July 26, 2023 by Editorial Team
Author(s): Shaibu Samuel
Originally published on Towards AI.
Case Study:
A virtual bank has been experiencing challenges with customers excessively leaving the bank. Some customers even exit the bank with unpaid loans, which has been affecting the productivity of the bank.
The board of directors consulted Data Science and Machine Learning professionals to get a lasting solution to the problem. After a series of brainstorming and design thinking processes, they decided to build a model that would predict if a particular customer would leave the bank. This model will help the bank officials make better decisions as regards granting loans and incentives too.
An Artificial Neural Network (ANN) model seems to be a better solution to this problem.
Fortunately, there are available data of customers containing their Credit score, location, Gender, Age, number of years spent in the bank, and amount of money left in their bank account, among other important details.
With this data, it’ll be easy to come up with a workable model. However, there has to be some data preprocessing before proceeding.
Here’s an approach I took to build a suitable model that will solve this problem. A machine learning/deep learning model.
Before building any machine learning model, you have to install some libraries and frameworks that will help you along the way. The frameworks you’ll be downloading are Tensorflow and Keras. Scikit Learn is already pre-installed, so there won’t be a need to download any.
But for this project, we’ll be using the Google Colaboratory platform, which does not require installing any libraries.
Data Preprocessing
To achieve this, libraries like Numpy (for numerical analysis), Matplotlib (for visualization), and Pandas (for importing datasets) will be imported.
You can then go ahead to import the dataset of the bank. For this project, you can have access to this dataset by visiting my Github profile and navigating to the repository. Here’s the link to the repository: https://github.com/samietex/Churn_Modelling_ANN

After importing the libraries, you can then go ahead to import the dataset for the model. For this ANN model, we’ll be importing the columns that will be needed for the prediction model. These columns must have been proven to have an impact on the dependent variable, which is if a customer will leave the bank or not. From the dataset, the first three columns which contain the Row number, Customer Id, and Surname of the Customer won’t be needed for the prediction model, hence the need to use the iloc function.
Before doing that, we’ll have to import the dataset into the Google Colaboratory platform using the lines of code below.

Now that the dataset has been uploaded to the Google Colaboratory platform, we can then go ahead to use pandas to import the data for our ANN model.

With print (dataset), you can have an overview of the data



Independent variables:
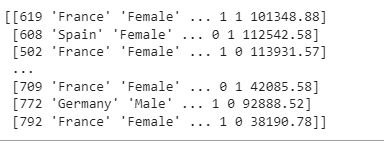
Dependent variables:

The Dependent Variable tells us whether or not the Customer leaves the bank. A value of 1 indicates that the customer left the bank, whereas a value of 0 indicates that the customer did not leave the bank. After we’ve imported the dataset into the model, we’ll need to do some feature engineering. This feature engineering aims to improve the accuracy of the Artificial Neural Network we’ll be building.
We’ll be encoding categorical data at this point. This procedure comprises converting categorical data to numerical data. Because the machine learning model can only read numerical data, not text, this is done. Let’s take a look at the Location column first. There are three categories of data in the location column (France, Spain, and Germany). To convert it to numerical data, we’ll utilize the LabelEncoder from the Sklearn library.

Now that we’ve implemented these lines of code for feature engineering, you’ll notice a change in the independent variables.
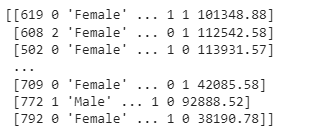
From the fig. above, you’ll observe that France has been converted to 0, Spain to 2 while Germany to 1.
We’ll also do the same for the Gender column, where we use the LabelEncoder to change the Gender categorical data to numerical data.

With these lines of code, you’ll notice that the gender column has been converted to a numerical column.

Females are 0 in the fig above, while males are 1. It’s also worth noting that the categories of the categorical variables have no relationship order. This indicates that France is not Germany, and Spain is not Spain, according to the Location column.
The way forward is to create dummy variables for this categorical variable. This is only necessary for the Location column since it contains 3 categories.

The last line of code is implemented to avoid falling into the dummy variable trap.
Now that we’re done with the Feature Encoding process, we can proceed to split the dataset into the train set and test set. 80% of the dataset will be used for training the model, while 20% of the dataset will be used to test the model.

Another important process we will not want to skip is Feature Scaling. This is applicable in all Deep Learning models because there are a lot of intensive calculations and computations in which Feature Scaling can play a great role in making it easy.
Below is the X_train and X_test output after the feature scaling
X_train:

X_test:

We are successfully done with preprocessing of the dataset. I know…it’s quite hectic…LOL
Let’s build the Artificial Neural Network. Shall we?
At this stage, we’ll be using the Keras library to build our ANN. To start with, we’ll proceed to import the necessary libraries for this project.
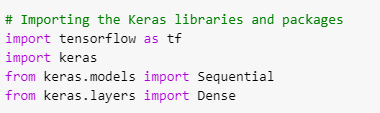
You’ll notice that some modules were also imported. These two models (Sequential module and Dense module) imported are very important in the building of the Artificial Neural Network (ANN) model. The Sequential module is required to initialize the neural network, while the Dense module is required to build the layers of the Artificial Neural Network.
Let’s Build the Artificial Neural Network
We’ll proceed to initialize the Artificial Neural Network now that we’ve completed the data preprocessing and imported the Tensorflow and Keras libraries with the required modules. The ANN can be initialized in two ways: by defining the layer sequence and by defining a graph.
We’ll set up the ANN model for this project by defining the layer sequence. This can be achieved by first constructing a sequential class object. This sequential class object is the neural network that will perform the function of a classifier. This is because the problem we’re attempting to solve is a classifier problem in which we’re attempting to predict a class (if a customer will leave the bank…true or false).

You can use the lines of code above to initialize the Artificial Neural Network. You can now go ahead to start adding different layers. Let’s start with the input layer and the first hidden layer.
Before we proceed, you’ll need to familiarize yourself with how Artificial Neural Networks are being trained with Stochastic Gradient Descent.
The first step is to set the weights to smaller numbers that are close to but not precisely 0 at random. The first observation of the dataset will be entered into the input layer by the Stochastic Gradient Descent, with each feature having its own input node. As a result, forward propagation will occur. Please keep in mind that during forward propagation, the neurons are activated in such a way that the weights restrict the influence of each neuron’s activation. This is repeated until the desired dependent variable is found.
Now, the predicted result and the actual result can then be compared, and some metrics can be used to measure the generated error.
There is still back-propagation to be done. At this stage, the error is back-propagated from right to left at this point. The weights are also adjusted based on how much they contributed to the inaccuracy. Throughout this stage, keep in mind that the learning rate determines how much the weights are updated.
The entire process has to be repeated and, at the same time, update the weights after each observation for reinforcement learning, whereas for batch learning, you must repeat the entire procedure but update the weights after a batch of observations.
We’ll use 10 neurons as a start, 5 hidden layers, and 1 output layer to forecast if a customer will quit the bank because we have 10 dependent factors. For the input and hidden layers, we’ll use the rectifier activation function, also known as’relu,’ and for the output layer, we’ll use the sigmoid activation function.

Now that we have added the input layer, hidden layers, and output layer, we can then go ahead to compile the ANN model. This is done using the Adam optimizer, and also specifying the loss (Root mean squared error, RMSE), and the accuracy.

We can then go ahead to fit the training sets to the classifier (ANN model). For this project, we will be running 10 batch size, and 100 epochs. These parameters can be adjusted till your required accuracy is obtained. The same can be done to the number of neurons and hidden layers.
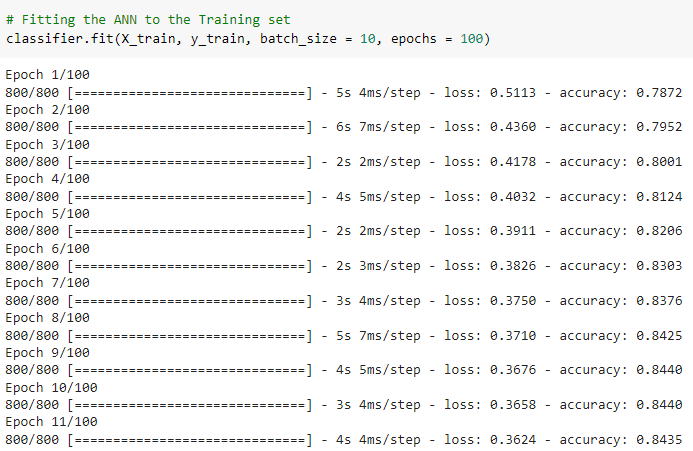
Here’s a summary of the ANN model we just built

In predicting, we will be considering a 50% threshold. For sensitive projects like medical-related ones, we might want to be considered 70% and above.

The code below is basically stating that if y_pred is larger than 0.5, return true, else if y_pred is lesser than 0.5, return false.
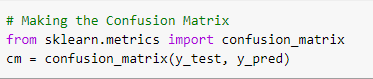

We can then go ahead to execute the code below to get the confusion matrix. The confusion matrix will basically give us an idea of the number of correct and incorrect predictions, and the accuracy of new observations.
We can conclude that out of 2000 observations, 1534 + 193 are correct predictions, while 212 + 61 are incorrect predictions.
We are almost done with this project. Let’s take a look at some visualizations.



With this Artificial Neural Network model, managers and stakeholders in the bank industry can increase their revenue by giving loans to customers that will likely not leave the bank.
You’ve come a long way; thanks for reading this article. For more related posts and articles, follow me on LinkedIn, and Twitter.
For more details on this ANN model: https://github.com/samietex/Churn_Modelling_ANN/blob/main/ChurnRatePred.ipynb
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

