



Optimizing Object Avoidance With Genetic Algorithm in Python
Last Updated on June 6, 2023 by Editorial Team
Author(s): Kong You Liow
Originally published on Towards AI.
Nature has long served as a source of inspiration for optimization and problem-solving techniques. One such approach that emulates natural evolution is the genetic algorithm.
A genetic algorithm is a metaheuristic that leverages the principles of natural selection and genetic inheritance to uncover near-optimal or optimal solutions. At the core of every genetic algorithm lies the concept of a chromosome. Through processes that simulate genetic evolution, such as selection, crossover, and mutation, a set of chromosomes undergoes continuous refinement. Underperforming chromosomes are gradually eliminated, while those exhibiting better performance are retained. The fitness of the chromosomes serves as a measure of their effectiveness. Over several iterations, known as generations, a single or a group of chromosomes eventually emerges as the optimal or near-optimal solution to the given problem.
While the efficiency of the genetic algorithm may be a subject of debate, its straightforward implementation has made it a popular choice among modelers. This algorithm has found applications in various domains, including engineering, computer science, and finance, where it tackles optimization problems that are typically computationally challenging or difficult to solve.
This article demonstrates the principles of the genetic algorithm on a 2-dimensional obstacle avoidance problem. Our setup consists of a moving object (referred to as the car) that travels horizontally from left to right. Additionally, there are moving obstacles that traverse vertically, potentially obstructing the car’s path. The primary focus of our discussion centers around the algorithm itself, specifically its fundamental operators: selection, crossover, and mutation. The detailed explanation of the simulation setup will be addressed separately in future discussions.
Defining chromosome and fitness
In every genetic algorithm, the concepts of chromosomes and fitness play crucial roles. A chromosome is essentially an array of values, commonly expressed in bits (0s and 1s), although it can also be represented as integers depending on the specific problem. The chromosome represents the solution domain for the given problem.
On the other hand, fitness serves as a metric or function that evaluates the performance of a solution. It determines how well a particular chromosome or solution addresses the problem at hand. The fitness function provides a quantitative measure of the chromosome’s suitability or effectiveness within the context of the optimization problem.
In our simplified setup, we define a chromosome as the representation of the car’s acceleration throughout the simulation. Each value within the chromosome corresponds to the acceleration at a specific time. Let us consider an example chromosome:
>>> acceleration = [1, 2, -1, 2, 3]
In this scenario, our simulation spans five-time frames. The acceleration values within the chromosome are as follows: 1 for the first frame, 2 for the second frame, -1 for the third frame, and so on. We have chosen acceleration as the chromosome because it is the second derivative of the distance traveled, and integrating acceleration twice yields a smooth movement for the car.

Next, we define fitness as the normalized distance traveled by the car. The simulation terminates either when the car collides with an obstacle or when it reaches the maximum number of time frames. The purpose of this fitness definition is to encourage the algorithm to prioritize chromosomes (acceleration sequences) which produce cars that can successfully navigate around obstacles. Ideally, a successful scenario occurs when the car completes the entire course within the given time frame, successfully avoiding all obstacles without any collisions.
Structure of genetic algorithm
We can summarise the steps of our genetic algorithm as follows:
- Initialization: begin by randomly generating a set of chromosomes.
- Fitness calculation: evaluate the fitness of each individual chromosome and identify the best-performing chromosome.
- Fitness probability calculation: determine the fitness probability for each chromosome.
- Selection: Choose a subset of stronger chromosomes based on their fitness probability and remove weaker chromosomes. Replace the removed chromosomes with newly generated random chromosomes.
- Crossover: Select pairs of chromosomes and exchange segments at corresponding array locations (alleles).
- Mutation: Randomly modify values within the set of chromosomes.
- Repeat Steps 2 to 6 until one of the termination conditions is met: either the car associated with the best-performing chromosome completes the course without collision and within the given time, or the maximum number of generations is reached.

In our setup, we work with a fixed number of chromosomes, specifically 50 chromosomes in each set. Additionally, we set the maximum number of generations to 50 to prevent the simulation from running indefinitely without finding a solution. The maximum duration of the simulation is set to 400-time frames.
Fitness
The figure below illustrates the trajectory of the best-performing car, derived from the best-performing chromosome out of the initial set of 50 chromosomes in the 0th generation. The acceleration values in this chromosome are randomly generated. However, in this specific case, the car collides with the 9th obstacle, leading to the termination of the simulation. The total distance traveled by car in this scenario is 18 (in arbitrary distance units). As a result, the fitness score for this best-performing chromosome is approximately 7.5/18 = 0.417.
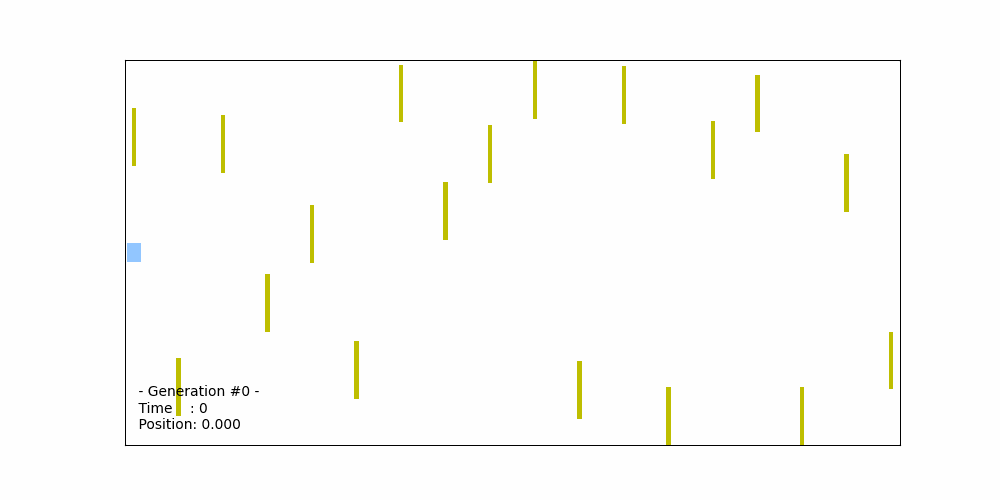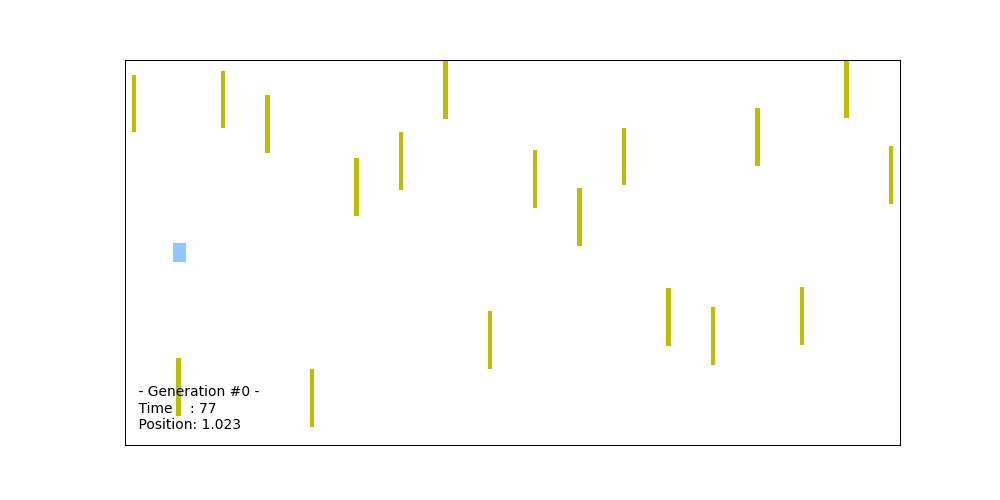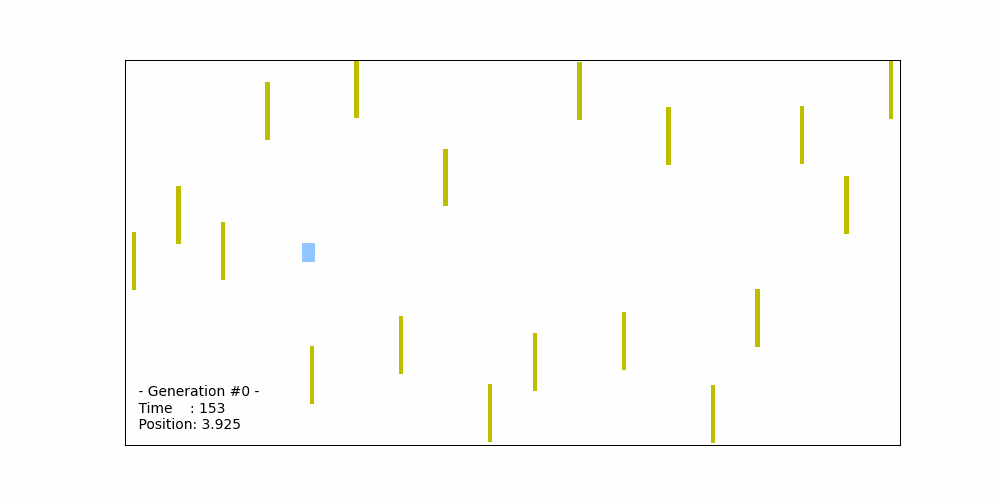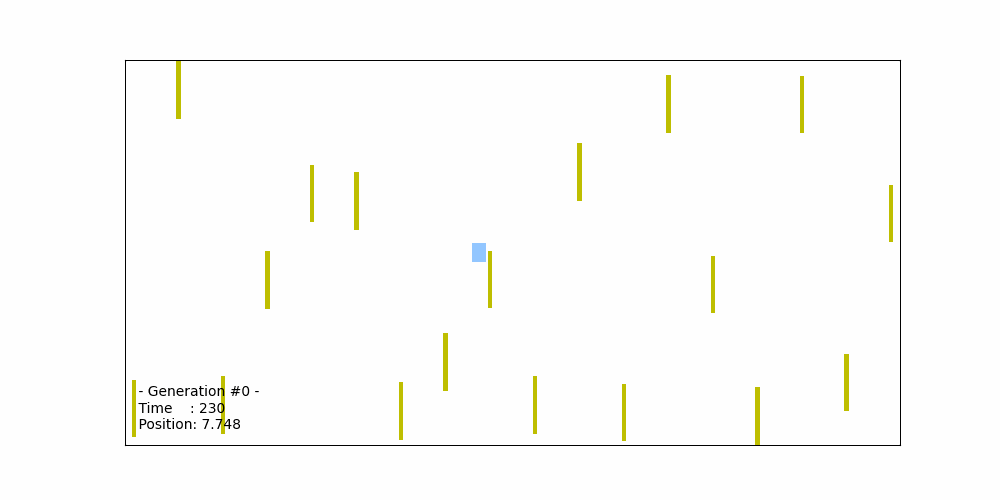
Fitness probability
Before proceeding to the core of the algorithm, we must calculate the fitness probability for each chromosome. The fitness probability is determined by normalizing the fitness values, providing an indication of how well each chromosome performs relative to others within the set. These probabilities are then utilized in the selection phase of the algorithm.
Consider the following example, which illustrates the fitness values and respective fitness probabilities for three chromosomes. In this scenario, Chromosome 1 demonstrates twice the performance of both Chromosome 2 and Chromosome 3.

Below is a code snippet demonstrating a Fitness class that includes methods to calculate the fitness values (normalized distances) and fitness probabilities for a given set of chromosomes:
class Fitness:
def __init__(
self,
distances: numpy.ndarray,
):
"""
:param distances: The distance travelled by the car for each
chromosome.
"""
self.distances = distances
def normalised_distance(self) -> numpy.ndarray:
"""
Use travel distances over maximum distance as fitnesses.
Shape of `fitnesses` is (N_chromosome,). `c.max_distance` = 18.
"""
return self.distances / c.max_distance
@staticmethod
def fitness_probabilities(fitnesses: numpy.ndarray) -> numpy.ndarray:
"""
Compute fitness probability.
"""
p_fitness = numpy.asarray(fitnesses) / numpy.sum(fitnesses)
return p_fitness
Selection
The first operator of the genetic algorithm is selection, which involves choosing well-performing chromosomes from the set for further processing. Various selection methods are available, some of which are problem-specific, while others are more general in nature. In our setup, we utilize the roulette wheel selection method, a commonly used approach where the probability of selecting a chromosome is directly proportional to its fitness probability.
The roulette wheel selection process is repeated until the desired number of chromosomes is obtained, maintaining the same quantity as in the original set. By employing this method, chromosomes with higher fitness probabilities have a greater chance of being selected, reflecting their superior performance.
In the previous example with three chromosomes, let us illustrate the selection process using the roulette wheel selection method. In this case, we draw chromosomes from the set with repetition, conducting three draws to obtain a new set of three chromosomes. Given that Chromosome 1 has the highest fitness probability, it has a greater chance of being selected during the roulette wheel selection process.
Let us simulate the draws: after the three draws, we have a new set of three chromosomes: Chromosome 1, Chromosome 1 (repeated selection), and Chromosome 3. The selection process favors chromosomes with higher fitness probabilities, resulting in a higher likelihood of selecting Chromosome 1 multiple times.
Below is a code snippet illustrating a Selection class that implements the roulette wheel selection method using the numpy.random.choice() function:
class Selection:
def __init__(
self,
p_fitness: numpy.ndarray,
accelerations: numpy.ndarray,
):
"""
:param p_fitness: Fitness probabilities.
:param accelerations: Accelerations (a.k.a. chromosomes).
"""
self.p_fitness = p_fitness
self.accelerations = accelerations
def roulette_wheel(self) -> numpy.ndarray:
"""
Selection via roulette wheel. `c.N_chromosome` = 50.
"""
chromosome_to_keep_indices = numpy.random.choice(
c.N_chromosome, c.N_chromosome, True, self.p_fitness
)
return self.accelerations[chromosome_to_keep_indices]
Crossover
Following the selection process, the new set of chromosomes undergoes crossover, which involves generating new solutions that retain similarities to the previously selected chromosomes. In a crossover, alleles between a set of chromosomes are exchanged. Let us revisit our example of three chromosomes to illustrate a possible crossover operation:

In this example, the alleles at specific positions between a pair of chromosomes are swapped, such as the second value of Chromosome 1 and the second value of Chromosome 3, as well as the fifth value of Chromosome 2 and the fifth value of Chromosome 3. Additionally, crossover can also occur between Chromosome 1 and Chromosome 2 at positions where the resulting alleles would be identical. For instance, if the third value of Chromosome 1 and the third value of Chromosome 2 are the same, the crossover can still take place at that position.
To implement crossover, we begin by defining the probability of crossover. Typically, a small value is assigned to this probability to ensure that the previously selected chromosomes remain relatively intact, while still introducing stochasticity in the new set of chromosomes. In our algorithm, we set the probability of crossover to 0.2.
Below is a code snippet illustrating the Crossover class. The simple_crossover method randomly selects a certain number of chromosomes for crossover. For each pair of selected chromosomes, a random allele is chosen to be swapped.
class Crossover:
def __init__(self, accelerations: numpy.ndarray):
self.accelerations = accelerations
def simple_crossover(self) -> numpy.ndarray:
"""
Simple non-binary crossover. `c.p_crossover` = 0.2.
"""
N_crossover = int(c.p_crossover * c.N_chromosome)
if N_crossover % 2 != 0:
N_crossover -= 1
random_indices = numpy.random.choice(
c.N_chromosome, size=N_crossover, replace=False
)
# Crossover front and rear chromosome pairs
for n in range(int(N_crossover / 2)):
a, b = random_indices[n], random_indices[N_crossover - n - 1]
front = self.accelerations[a].copy()
rear = self.accelerations[b].copy()
portion = numpy.random.choice(c.N_frame, size=2, replace=False)
self.accelerations[a][portion[0] : portion[1]] = rear[
portion[0] : portion[1]
]
self.accelerations[b][portion[0] : portion[1]] = front[
portion[0] : portion[1]
]
return self.accelerations
Mutation
The final operator in the genetic algorithm is a mutation, which introduces randomness by altering the values within the chromosomes. Returning to our example of three chromosomes, a mutation operation could lead to the following updated set of chromosomes:

In this example, four mutations occur: the first value of Chromosome 1 mutates from 1 to 4, the third value of Chromosome 2 mutates from -1 to 0, the first value of Chromosome 3 mutates from 1 to 0, and the fourth value of Chromosome 3 mutates from 4 to 3.
To incorporate mutation in the genetic algorithm, we require the mutation probability. It is crucial to strike a balance when applying mutations, as excessive mutation can lead to the loss of valuable information. In our case, we use a mutation probability of 0.05.
Below is the Mutation class, which includes the simple_mutation method. This method determines the number of mutations to be applied and selects the chromosomes and mutation locations accordingly. Randomly generated values are then assigned to the mutation locations.
class Mutation:
"""
Class to handle mutation related algorithm
"""
def __init__(self, accelerations: numpy.ndarray):
self.accelerations = accelerations
def simple_mutation(self):
"""
Simple non-binary mutation. `c.p_mutation` = 0.02, and
`c.max_acceleration` = 5.
"""
N_mutation = int(c.N_chromosome * c.N_frame * c.p_mutation)
# Y (which chromosome) and X (where in chromosome) to be mutated
mutation_x = numpy.random.randint(c.N_frame, size=N_mutation)
mutation_y = numpy.random.randint(c.N_chromosome, size=N_mutation)
for i in range(N_mutation):
x, y = mutation_x[i], mutation_y[i]
self.accelerations[y, x] = (
numpy.random.randint(-c.max_acceleration, c.max_acceleration + 1)
)
return self.accelerations
Result and summary
We continue the iterative process of selection, crossover, and mutation until we reach a (near-) optimal solution, which in our case, is when the car successfully completes the obstacle course. The figure below illustrates the car’s successful completion in the 47th generation:
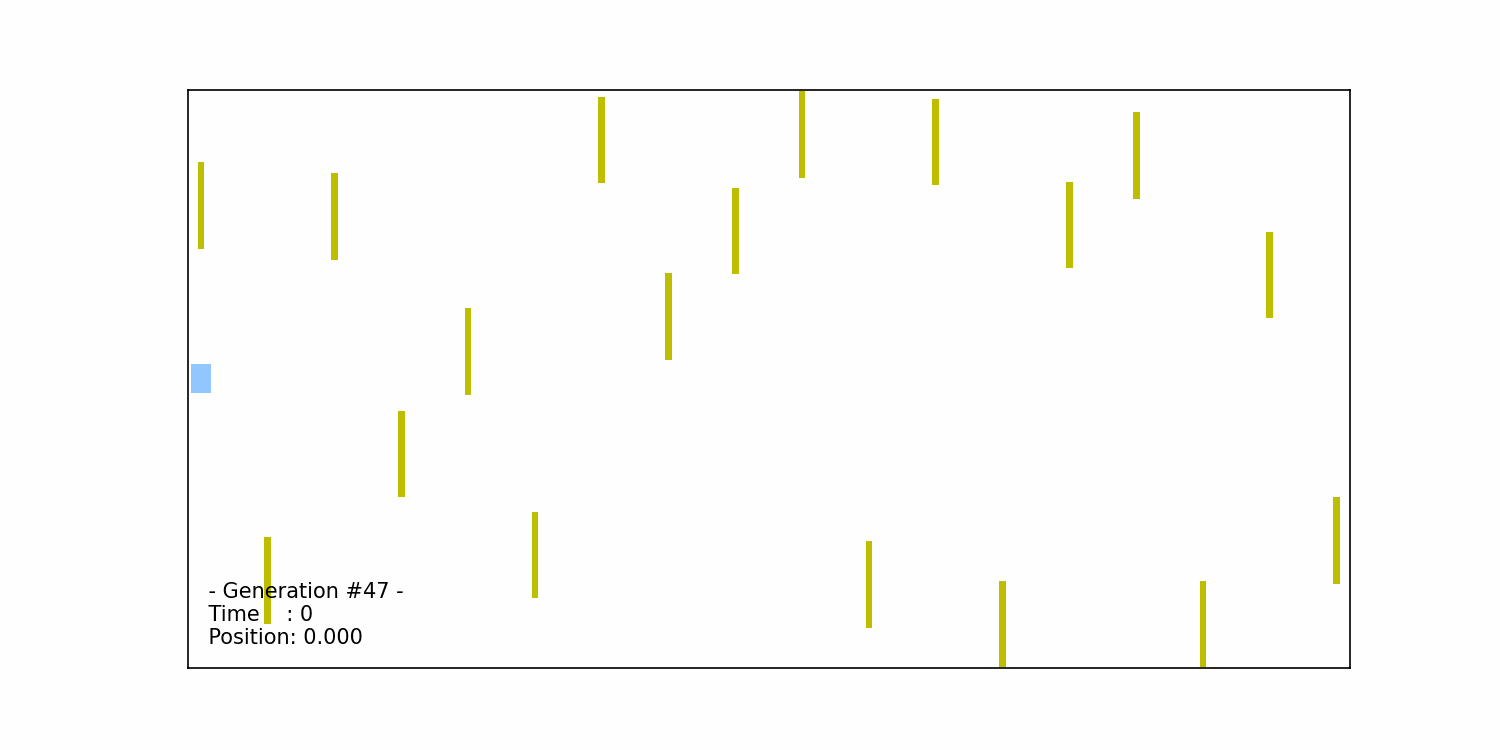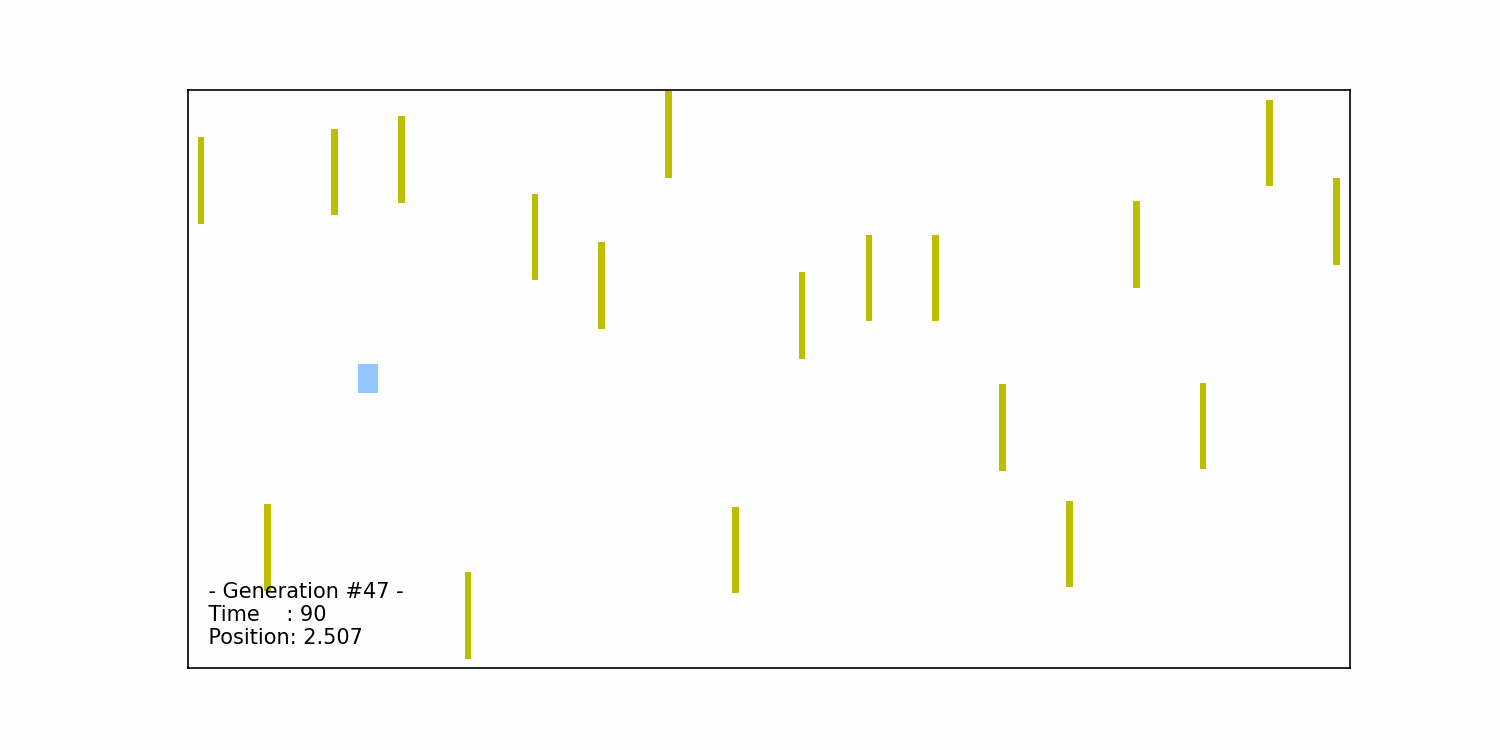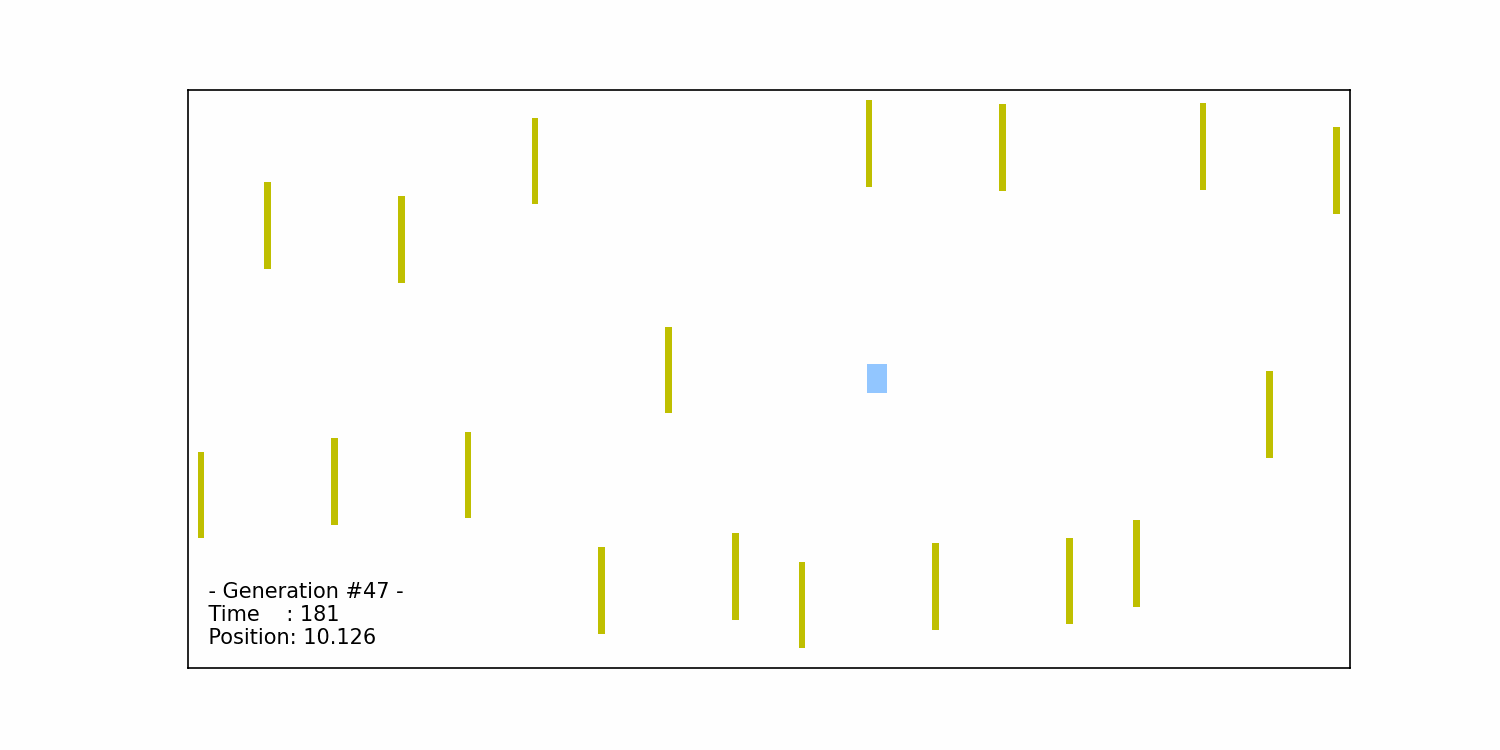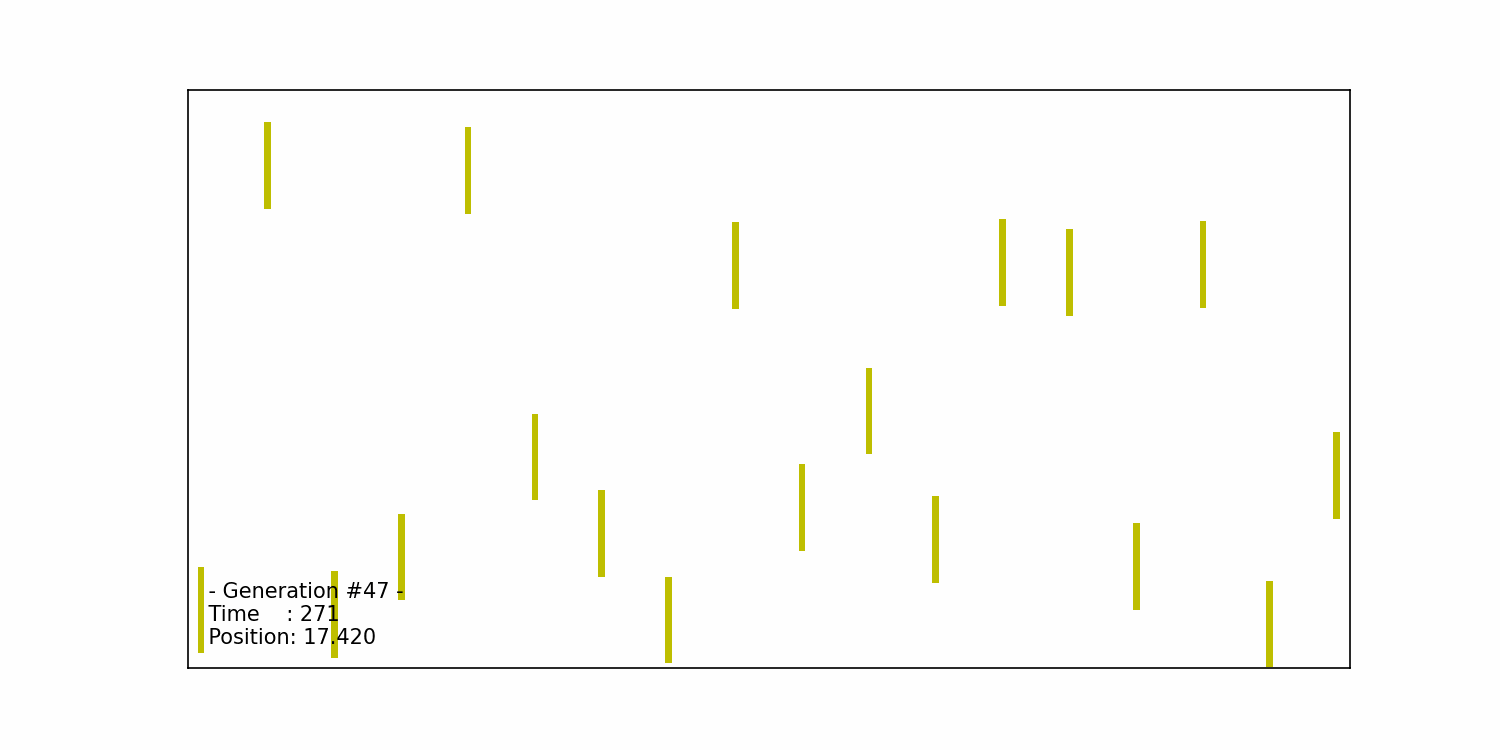
The generations leading up to the 47th iteration involve the algorithm evolving and improving the set of chromosomes to find the best-performing solution. Through the repeated application of selection, crossover, and mutation, the algorithm gradually hones in on chromosomes that enable the car to navigate the course successfully. The specific number of generations required to reach the optimal solution can vary depending on factors such as the complexity of the problem, the population size, and the effectiveness of the selection, crossover, and mutation operators.
In conclusion, we have demonstrated the successful application of a genetic algorithm to solve an object avoidance optimization problem. The genetic algorithm, with its iterative process of selection, crossover, and mutation, has proven effective in improving the car’s ability to navigate through moving obstacles over successive generations.
However, it is important to recognize the limitations of the genetic algorithm. One limitation is its lack of adaptability to changes in the problem setup. The best-performing chromosome obtained from one specific obstacle configuration may not be optimal or even effective when the setup is altered. To address new setups, the simulation would need to be rerun from the beginning to allow the car to learn and adapt to the changes. Furthermore, the effectiveness of the genetic algorithm heavily depends on how chromosomes and fitness are defined. Careful consideration must be given to designing appropriate chromosome representations and fitness metrics to ensure accurate and meaningful optimization results.
Despite these limitations, the genetic algorithm has shown its potential to tackle complex and unstructured problems. It serves as a valuable tool for optimization in various domains, providing insights and solutions that may not be readily achievable through traditional approaches. With proper parameter tuning and problem-specific adaptations, the genetic algorithm can be a powerful tool in finding near-optimal solutions in a wide range of optimization scenarios.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

