


No Language Left Behind
Last Updated on July 26, 2023 by Editorial Team
Author(s): Salvatore Raieli
Originally published on Towards AI.
Meta’s new model is able to translate between 200 different languages making the internet more accessible
Introduction
The limits of my language mean the limits of my world.
I always loved this quote from Wittgenstein, which really explained the importance of language in our life. Without the right words, we cannot express ourselves, and maybe with the development of the magnificent ability of language the human cognitive revolution would never have happened. Thus, we would not be here writing and reading these words. No longer after civilization was born, did writing come up. Moreover, in the dystopian novel Nineteen Eighty-Four, Orwell imagines the government using “Newspeak” as a form of censorship but also in a way to restrict people’s thinking.
I want to indulge in a few examples to represent the importance of language and translation. One of the funniest is how the erroneous translation of the Bible leads Michelangelo to believe Moses had horns. A more tragic error during the second world ward leads the ally to bomb the Monecassino monastery: an intercepted German message stated that there was an ‘abbot in the monastery (“abt”) and the Americans translated it as short for battalion (“Abteilung”). Or an error in translating from Japanese influenced Americans in the decision of using the atomic bomb. The translation was and is a political weapon, In ancient times, it was the practice to draft international treaties in multiple languages and try to include different clauses in each version to one’s advantage.
As language is so important, it has been an active field of research in AI. The new language models such as GPT3 are promising a revolution and a richness of new tools. They can be used to summarize text, create captions, transcript videos, and create text-to-speech applications. However, all these possibilities are restricted only to speaking English. “No Language Left Behind” is meant for to who was left behind, handling 200 languages.

Translation from science fiction to reality
In The Hitchhiker’s Guide to the Galaxy, Douglas Adams described the babel’s fish, a small fish that can be inserted in the ear and allows one to understand every language of the universe. Indeed, universal translation has once been deemed to be part of the domain of sci-fi.
When world war two started the cold war, interpreting the Russian messages was considered a priority task. the Allies had gotten a taste of the power of computers, thanks to Touring’s work in cracking the Enigma codes. Unfortunately, by the 1960s they realized that still, our knowledge of linguistics and computers was limited. Machine translation took off again in the early 1990s when statistical machine learning demonstrated decent results. It was only with the advent of neural networks that sophisticated translations were possible, and the arrival of large language models promised a new revolution.
Classical neural machine translation systems rely on a large dataset composed of pair of sentences (a sentence in one language and its translation in another). In general, these large corpora are collected and annotated by humans. While a large corpus is available for different widespread languages (for example, English, German, and French) which received institutional funding many other languages have been overlooked.
Meta new model, a clever way to construct the dataset
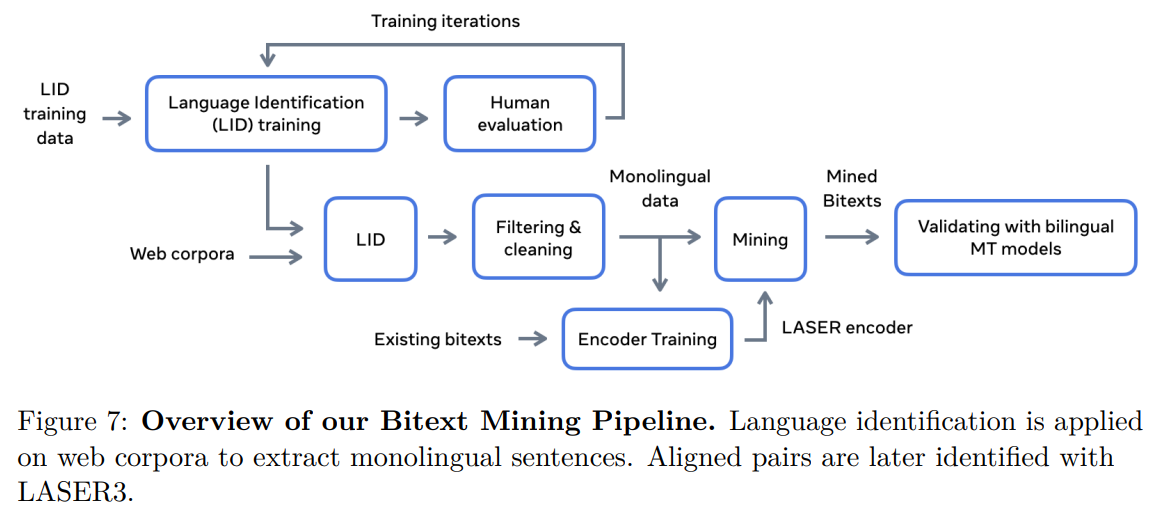
The classical system is hard to generalize and it is difficult and pricy to collect so many examples for smaller languages. Moreover, classical languages are trained to translate from one language to another and not to handle so many languages. Meta solved the dataset problem, using an initial dataset to detect language automatically (called in the paper Language Identification system). Another transformer-based model was used to find a sentence pair for the identified data. In this way, they constructed the dataset of examples for the final model
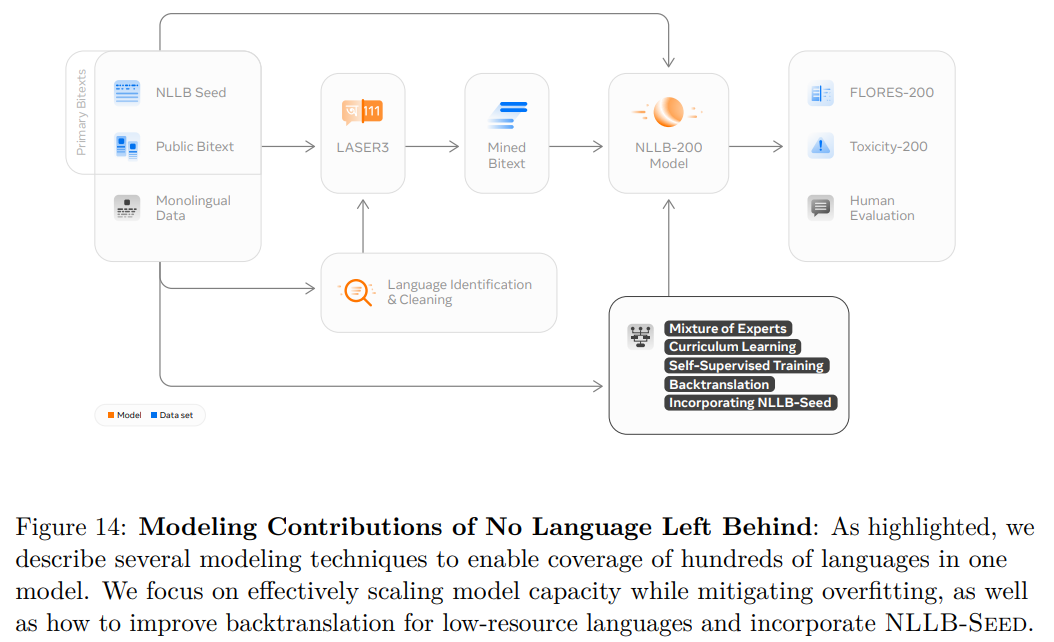
The final model is called NLLB200 (No Language Left Behind 200). The final model is actually a transformer-based model composed of an encoder and a decoder (like many other language models). In concrete, an input sequence is provided to the encoder and this part of the model is learning a representation of the content of the sentence. The encoder is providing this representation to guide the decoder in translating the sentence. The model used the translation to verify it was able to translate correctly.
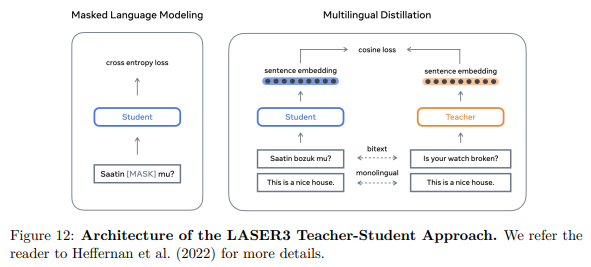
The model has also other tricks to improve the translation as Sparsely Gated Mixture of Experts but essentially the model is similar to others already published while the dataset assembly is the core idea.
Why prioritize low-resource language communities?
Research showed that only roughly 25% of internet user speaks English while 65% of internet website are in English. This staggering difference leads to the fact that many important resources (educational, working, or institutional) are not accessible to everyone, and who entire group of people is silenced on the web. In concrete, this lack of attention to low-resource communities is leading to additional marginalization of poor communities.
Moreover, during the last decades, we have seen a decline in native language and culture, which are caused by cultural (lack of books, media in a language) and economical reasons. Coverage and quality of existing automatic translation have overlooked these languages, increasing the gap between whom can access certain resources and who not.
The first step of the work was motivated to understand the impact of high-quality translation for hundreds of languages. In fact, the authors conducted interviews with 44 low-resource language speakers. This was conducted with the aim to direct emphasis on ethical and social considerations. They write in the paper:
Overall, our recruitment effort led us to 44 native speakers of low-resource languages from diverse backgrounds, with ages ranging from 23 to 58. Covering a total of 36 languages, the distribution is as follows: 5 languages are spoken predominantly in North America, 8 in South America, 4 in Europe, 12 in Africa, and 7 in Asia.
However, as pointed out in the paper, the limitation was:
Although our sample has breadth in terms of race, education, and location, the majority of our participants are immigrants living in the U.S. and Europe, and about a third of them (n = 17) identify as tech workers
In addition, research dedicated part of the work to detecting toxic items in the corpora and filtering them.
Conclusions
Not everyone speaks English (inside or outside the internet) and this should be considered when designing a language model. The importance of a language goes beyond researcher interest, a language is also an expression of culture, society, and belief.
The translation is necessary for the spread of information, knowledge, and ideas. In addition, the quality of translation has major social and economic downfalls. In fact, poor translation is a barrier that is harmful to too many communities. NLLB200 is just the first step in reducing this gap.
Resources
Here are some of the resources consulted for this article and additional resources that can be useful.
- The official research paper, which you can consult for additional technical details (it is 190 pages in length, too long to include in this short article all details).
- Meta’s blog posts: here and here
- Official video presenting the model
- The code (always nice to check it!)
if you have found it interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn. Thanks for your support!
Here, is the link to my Github repository where I am planning to collect code, and many resources related to machine learning, artificial intelligence, and more.
GitHub – SalvatoreRa/tutorial: Tutorials on machine learning, artificial intelligence, data science…
Tutorials on machine learning, artificial intelligence, data science with math explanation and reusable code (in python…
github.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

