



Natural Language Processing: What, Why, and How?
Last Updated on January 6, 2023 by Editorial Team
Author(s): Daksh Trehan
Machine Learning, Natural Language Processing
A complete beginner’s handbook to NLP
Table of Content:
- What is Natural Language Processing(NLP)?
- How does Natural Language Processing works?
- Tokenization
- Stemming & Lemmatization
- Stop Words
- Regex
- Bag of Words
- N-grams
- TF-IDF
Ever wondered how Google search shows exactly what you want to see? “Puma” can be both an animal or shoe company, but for you, it is mostly the shoe company and google know it!
How does it happen? How do search engines understand what you want to say?
How do chatbots reply to the question you asked them and are never deviated? How Siri, Alexa, Cortana, Bixby works?

These are all wonders of Natural Language Processing(NLP).
What is Natural Language Processing?
Computers are too good to work with tabular/structured data, they can easily retrieve features, learn them and produce the desired output. But, to create a robust virtual world, we need some techniques through which we can let the machine understand and communicate the way human does i.e. through natural language.
Natural Language Processing is the subfield of Artificial Intelligence that deals with machine and human languages. It is used to understand the logical meaning of human language by keeping into account different aspects like morphology, syntax, semantics, and pragmatics.
Some of the applications of NLP are:
- Machine Transliteration.
- Speech Recognition.
- Sentiment Analysis.
- Text Summarization.
- Chatbot.
- Text Classifications.
- Character Recognition.
- Spell Checking.
- Spam Detection.
- Autocomplete.
- Named Entity Recognition.
How does Natural Language Processing work?
Human languages don’t follow a certain set of clear rules, we communicate ambiguously. “Okay” can be used several times and still impart different meanings in different sentences.
If we want our machines to be accurate with natural languages, we need to provide them a certain set of rules and must take into account various other factors such as grammatical structure, semantics, sentiments, the influence of past and future words.
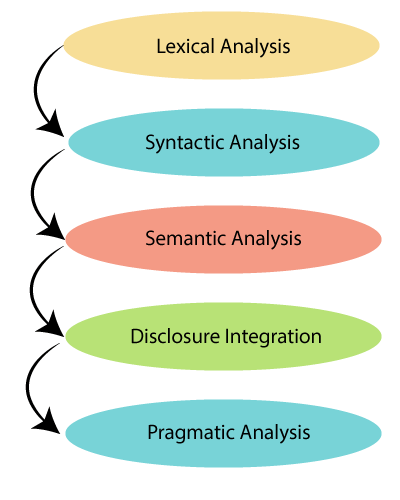
Lexical Analysis: This is responsible to check the structure of words, it is done by breaking sentences and paragraphs into a chunk of texts.
Syntactical Analysis: It comes into play when we try to understand the grammatical relationship between words. This also takes the help of arrangement of words to generate true and logical meaning.
e.g. “going to school he”, this is logically correct but grammatically, a better arrangement of words would’ve helped a lot.
Semantic Analysis: We can’t truly get the meaning of a sentence by just joining the meaning of words in it. We need to take into account other factors such as the influence of past and future words. Here’s how Semantic analysis helps.
e.g. “cold fire” may seem grammatically correct but logically it is irrelevant, so it will be discarded by Semantic Analyzer.
Disclosure Integration: It follows a well-defined approach to take into account the influence of past statements to generate the meaning of the next statement.
e.g. “Tom suffers food poisoning because he ate junk”. Now using this sentence we can conclude that Tom has met with a tragedy and it was his fault but if we remove some phrases or take only a few phrases into account the meaning could be altered.
Pragmatic Analysis: It helps to find hidden meaning in the text for which we need a deeper understanding of knowledge along with context.
e.g. “Tom can’t buy a car because he doesn’t have money.”
“Tom won’t get a car because he doesn’t need it.”
The meaning of “he” in the 2 sentences is completely different and to figure out the difference, we require world knowledge and the context in which sentences are made.
Tokenization
Tokenization can be defined as breaking sentences or words in further shorter forms. The idea followed could be, if we observe any punctuation mark in sentences break it right away, and for words if we see any space characters split the sentence.
Sentence Tokenization
As an output, we get two separate sentences.
Google is a great search engine that outperforms Yahoo and Bing.
It was found in 1998
Word Tokenization
Output:
['Google', 'is', 'a', 'great', 'search', 'engine', 'that', 'outperforms', 'Yahoo', 'and', 'Bing', '.']
['It', 'was', 'found', 'in', '1998']
Stemming & Lemmatization
Grammatically, different forms of root words mean the same with the variation of tense, use cases. For illustration, drive, driving, drives, drove all means same logically but used in different scenarios.
To convert the word into its generic forms, we use Stemming and Lemmatization.
Stemming:
This technique tends to generate the root words by formatting them to stem words using machine-generated algorithms.
e.g. “studies”, “studying”, “study”, “studied” will all be converted to “studi” and not “study”(which is an accurate root word).
The output of Stemming may not always be in line with grammatical logics and semantics and that is because it is completely powered by an algorithm.
Different types of Stemmer are:
- Porter Stemmer
- Snowball Stemmer
- Lovin Stemmer
- Dawson Stemmer
Lemmatization:
Lemmatization tries to achieve the motive of Stemming but rather than computer-generated algorithms it is based on a human-generated word dictionary and tries to produce dictionary-based words.
This is often more accurate.
e.g. “studies”, “studying”, “study”, “studied” will all be converted to “study”(which is an accurate root word).
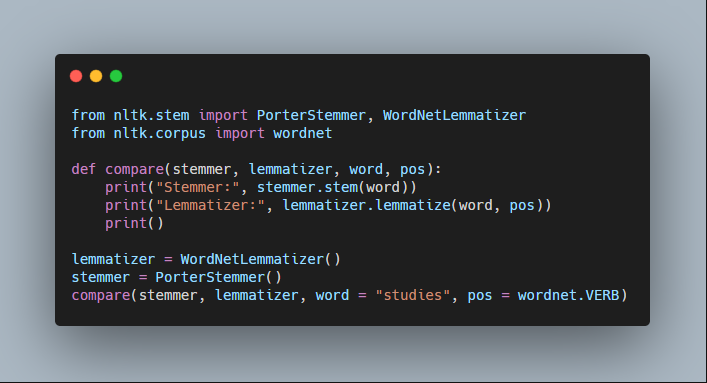
Output:
Stemmer: studi
Lemmatizer: study
Stemming vs Lemmatization
Both Stemming and Lemmatization are useful for their centric use-cases but generally, if the goal of our model is to achieve higher accuracy without any deadline, we prefer lemmatization. But if our motive is quick output, Stemming is preferred.
Stop Words
Stop words are those words that needed to be censored by our document. These are irrelevant words that usually don’t contribute to the logical meaning of the text but helps in grammatical structuring. While applying our mathematical models to text, these words could add a lot of noise thus altering the output.
Stop words usually includes most usual words such as “a”, “the”, “in”, “he”, “i”, “me”, “myself”.
Output:
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
Regex
Regex is short for Regular Expression, which can be defined as a group of strings defining a search pattern.
- w – match all word
- d – match all digit
- W – match not word
- D – match not digit
- S – match not whitespace
- [abc] – match any of a, b, or c
- [^abc] – match neither of a, b, or c
- [a–z] – match a character between a & z i.e. alphabets
- [1-100] – match a character between 1 & 100
Output:
Google is a great search engine that outperforms Yahoo and Bing. It was found in .
Bag of Words
Machine Learning algorithms are mostly based on mathematical computation, they can’t directly work with textual data. To make our algorithms compatible with the natural language, we need to convert our raw textual data to numbers. This technique is known as Feature Extraction.
BoW (Bag of Words) is an example of the Feature Extraction technique, which is used to define the occurrence of each word in the text.
The technique works as it is named, the words are stored in the bag with no orders. The motive is to check whether the input word fed to our model is present in our corpus or not.
e.g.
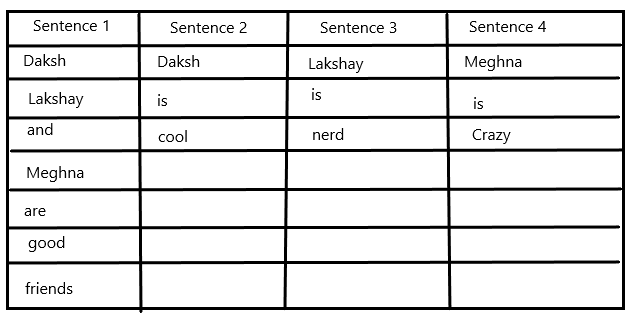
- Daksh, Lakshay, and Meghna are good friends.
- Daksh is cool.
- Lakshay is nerd.
- Meghna is crazy.
- Creating a basic structure:
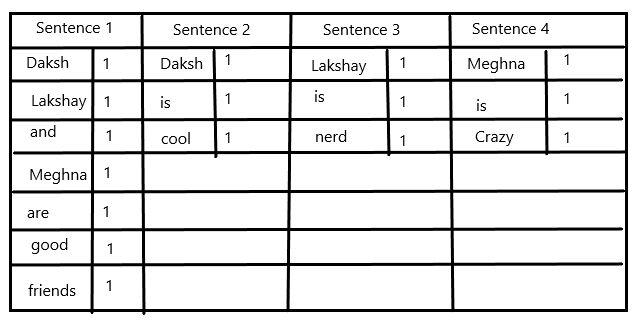
- Finding frequency of each word:
- Combining the output of previous step:
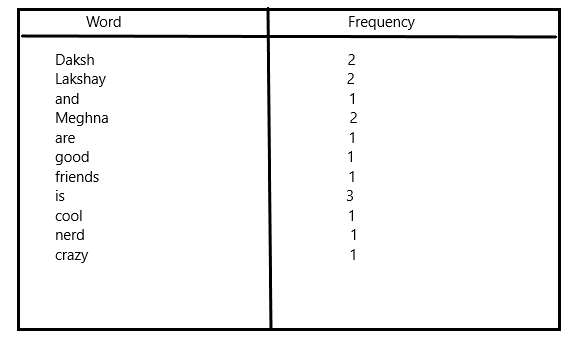
d. Final output:
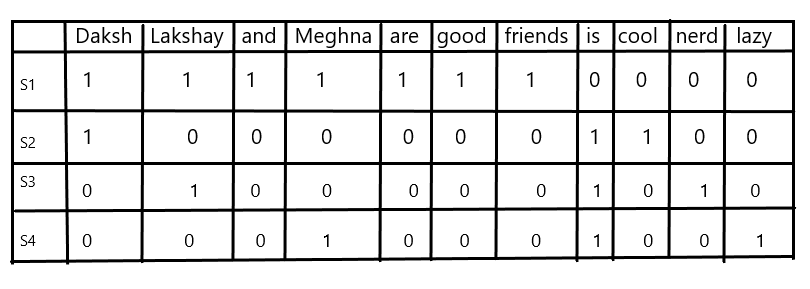
When our input corpus increases, the vocabulary size increase thus increasing vector representation which leads to a lot of zeros in our vectors, these vectors are known as sparse vectors and are more complex to solve.
To limit the size of vector representation, we can use several text-cleaning techniques:
- Ignore punctuations.
- Remove Stop words.
- Convert words to their generic form( Stemming and Lemmatization)
- Convert the input text to a lower case for uniformity.
N-grams
N-grams is a powerful technique to create vocabulary thus providing more power to the BoW model. An n-gram is a collection of “n” items grouped.
A unigram is a collection of one word, a bigram is a collection of two words, a trigram comes with three items, and so on. They only contain the already available sequence and not all possible sequences thus limiting the size of the corpus.
Example
He will go to school tomorrow.

TF-IDF
Term Frequency-Inverse Document Frequency (TF-IDF) is a measure to generate a score to define the relevancy of each term in the document.
TF-IDF is based on the idea of Term Frequency(TF) and Inverse Document Frequency(IDF).
TF states that if a word is repeated multiple times that means it is of high importance as compared to other words.
According to IDF, if the same more occurring word is even present in other documents then it is of no high relevance.
The combination of TF and IDF generates a score for each word, helping our machine learning models to get an exact high relevant text from the document.
TF-IDF score is directly proportional to the frequency of the word, but it is inversely proportional to a high frequency of the word in other documents.
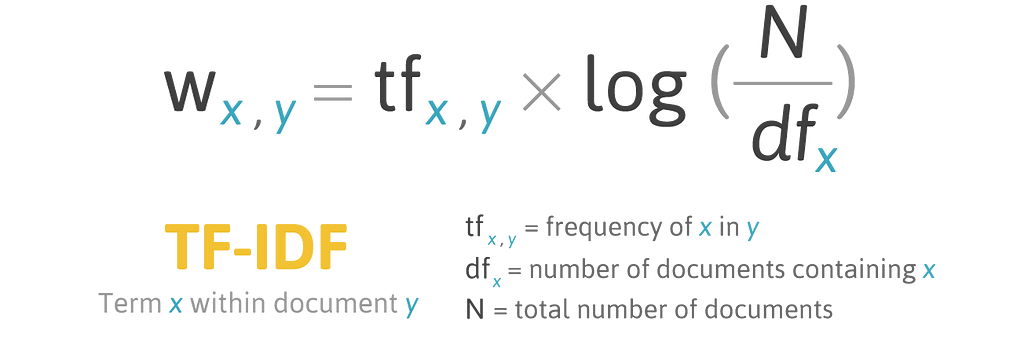
- Term Frequency (TF): Checks the frequency of words.
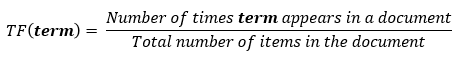
- Inverse Term Frequency (ITF): Checks rareness of words.
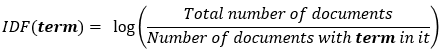
Combining above formulas, we can conclude:
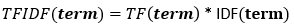
Conclusion
The article helped us to throw a light on Natural Language Processing and all its basic terminologies and techniques. If you wish to dig deeper in NLP using Neural Networks you can read more about Recurrent Neural Networks, LSTMs & GRUs.
References:
[2] Natural Language Processing (NLP): What Is It & How Does it Work? (monkeylearn.com)
[3] Introduction to Natural Language Processing for Text | by Ventsislav Yordanov | Towards Data Science
[4] Natural Language Processing (NLP) with Python — Tutorial | by Towards AI Team | Towards AI
Feel free to connect:
Portfolio ~ https://www.dakshtrehan.com
LinkedIn ~ https://www.linkedin.com/in/dakshtrehan
Follow for further Machine Learning/ Deep Learning blogs.
Medium ~ https://medium.com/@dakshtrehan
Want to learn more?
Are You Ready to Worship AI Gods?
Detecting COVID-19 Using Deep Learning
The Inescapable AI Algorithm: TikTok
GPT-3 Explained to a 5-year old.
Tinder+AI: A perfect Matchmaking?
An insider’s guide to Cartoonization using Machine Learning
Reinforcing the Science Behind Reinforcement Learning
Decoding science behind Generative Adversarial Networks
Understanding LSTM’s and GRU’s
Recurrent Neural Network for Dummies
Convolution Neural Network for Dummies
Cheers
Natural Language Processing: What, Why, and How? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts





")
