



Natural Language Clustering — Part 1
Last Updated on January 6, 2023 by Editorial Team
Author(s): Francesco Fumagalli
Natural Language Processing
Natural Language Clustering — Part 1
Help chatbots deal with FAQs, with Python code for Tokenization, GloVe, and TF-IDF
Classifying things comes quite natural to us: our books, movies and music all have genres; the things we study are split between different subjects and even the food we eat belongs to different cuisines!
In recent years we’ve been able to develop better and better algorithms to classify text: models like BERT-ITPT-FiT (BERT + withIn-Task Pre-Training + Fine-Tuning) or XL-NET seem to be reigning champions in this category, at least in the 29 benchmark datasets available on PapersWithCode.
In recent years we’ve been able to develop better and better algorithms to classify text: models like BERT-ITPT-FiT (BERT + withIn-Task Pre-Training + Fine-Tuning) or XL-NET seem to be reigning champions in this category, at least in the 29 benchmark datasets available on PapersWithCode.
But what if we don’t know the available categories for the texts we want to analyze? Take for example a corpus of conversations or a collection of books or articles that all belong to different specializations within the same subject: labels aren’t always as clear cut as spam / not spam, we may not have any idea of how many or what kind of labels to expect, or normal pre-trained classification methods wouldn’t have the in-depth domain knowledge required not to classify them as all the same, while not enough material, time or computational power is available to fine-tune a Transformer model.
Perhaps one of the most obvious examples is categorizing incoming messages into FAQs: not every message can be answered via a FAQ, but we’d like to associate as many as possible to the right answer, to minimize the amount we leave unanswered or address manually, and dynamically improve our FAQs adding new questions that become relevant.
Let’s see how!
From words to numerical values: Tokenization and Embedding
The first thing we have to do, as always when dealing with Natural Language, is transforming the text into something our algorithms can understand. Paragraphs and sentences are split into their basic components, words, in a process called tokenization. But words themselves can’t be fed to a computational model since mathematical operations can’t be applied to them, which explains the need to have them mapped onto vectors of real numbers: basically transformed into sequences of numbers which represent them in a mathematical space, also preserving the relationships between them (a process known as word embedding, a term coming from mathematics to identify an injective and structure-preserving map).
It sounds complex, but there are simple ways to do this, such as the one shown below: starting from three sentences (on the left) their tokens are extracted and a very simple embedding is performed (on the right) by counting the occurrences of each token (word) in the original texts
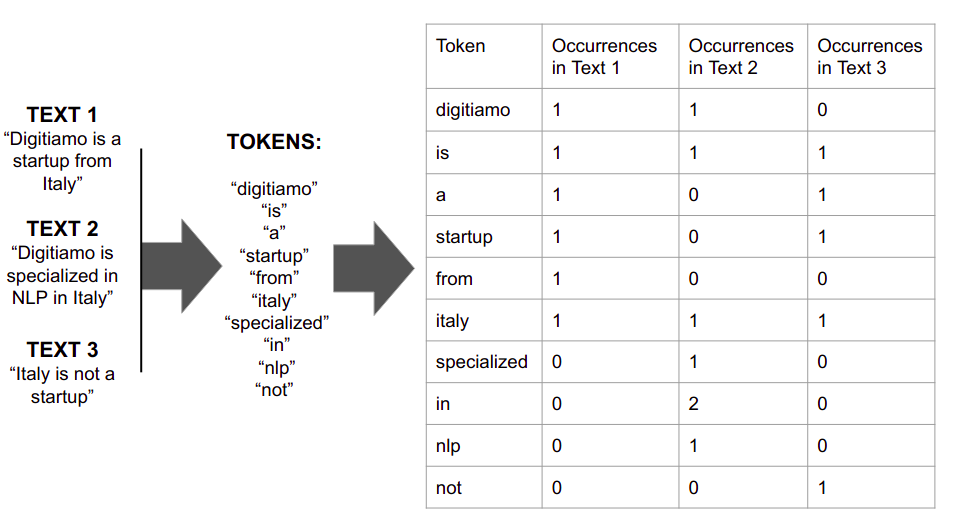
In the example above the word startup is embedded as [1,0,1] because it appears once in the first and third text but not in the second one, whereas the word “in” is embedded as [0,2,0] because it only appears in the second sentence, twice.
Note that it’s not a very practical example: given the small number of inputs different words end up having the same embedding (for example “specialized” and “in” both appear in the second text only, so they share the same embedding [0,1,0]), but we hope it helps you get a better understanding of how the process works.
Also note that the tokens are all lowercase and the punctuation has been removed: that’s common practice, although it depends on the kind of text we’re dealing with.
Another common practice not shown in the example above is the removal of stopwords, words so common they aren’t relevant for our purpose and very likely to be found an abundant number of times in most texts we come across (such as “a”, “the” or “is”).
This approach, however, provides the advantage of embedding documents themselves at the same time as words: reading the table vertically, Text1 can be read as [1,1,1,1,1,1,0,0,0,0]. This makes it easy to confront different sources by introducing a distance metric.
Tokenization Code Example in Python using nltk:
# !pip install nltk
from nltk.tokenize import word_tokenize
text = "Digitiamo is a Startup from Italy"
tokenized_text = nltk.word_tokenize(text)
print(tokenized_text)
# OUTPUT:
# ['Digitiamo', 'is', 'a', 'Startup', 'from', 'Italy']
Embedding Code Example in Python using gensim’s Word2Vec
# !pip install --upgrade gensim
from gensim.models import Word2Vec
model = Word2Vec([tokenized_text], min_count=1)
"""
min_count (int, optional) – Ignores all words with total frequency lower than this.
Word2Vec is optimized to work with multiple texts at the same time in the form of a list of texts. When working with a single text, it should be put into a list, which explains the square brackets around tokenized_text
"""
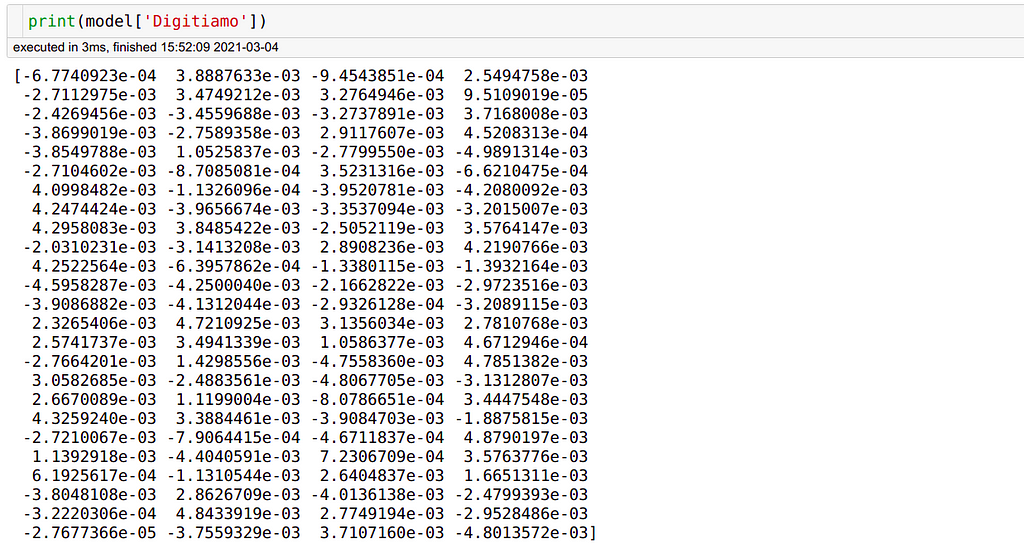
print(list(model.wv.vocab))
# OUTPUT:
# ['Digitiamo', 'is', 'a', 'Startup', 'from', 'Italy']
Commonly used Embeddings: TF-IDF and GloVe
- TF-IDF stands for Term Frequency–Inverse Document Frequency and it emphasizes the importance of each term based on how many times it appears in other texts from the corpus. It can be very useful to embed texts within a specialized domain for the purpose of clusterization. The words that appear in every document, no matter how infrequent they are in everyday usage, will be given very little weight, whereas words that only appear in some documents will be given more weight, making it easier to recognize possible clusters.
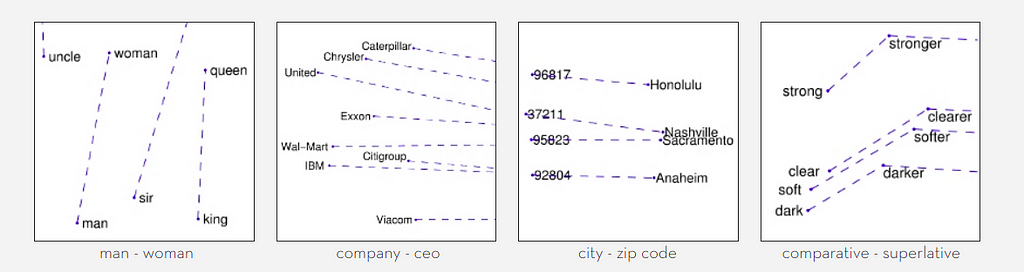
For example, if we were trying to embed a bunch of papers about endocrinology, the word “endocrinology” itself would likely be mentioned multiple times in each paper, making its presence not very helpful for the purpose of distinguishing them. - GloVe (Global Vectors for word representation) is an unsupervised algorithm that links words based on how often they occur together, trying to map the underlying meaning. You can see some examples of relationships between words obtained through GloVe in the image below: “man” is approximately as distant from “woman” as “king” is from “queen” going in the same direction, as they have the same meaning for different genders (and vice versa, of course). The same happens for comparatives and superlatives in the fourth panel: the vector that takes you from “clear” to “clearer”, if applied to “soft”, brings you to “softer”.
Depending on the size of your corpus the Mittens library could be a good complement to GloVe: according to their GitHub, it’s “useful for domains that require specialized representations but lack sufficient data to train them from scratch. Mittens starts with the general-purpose pretrained representations and tunes them to a specialized domain”, it’s also compatible with Numpy and TensorFlow.
Excellent! Now that we’ve transformed our words into numerical vectors and mapped them onto a space, if we’ve used an embedding that only works for words and not full texts it’s time to go back to sentences: remember our original goal? We don’t just want to map words, but try to cluster the texts or sentences they’re in.
There are many way to do this and some may work better than others, depending on the context. Perhaps the easiest one, that’s also quite effective for short text, would be to average the embedding of each word in a text to generate the embedding of the whole text.
For longer material another approach is to extract the keywords and then average the embedding of those, to be sure your average isn’t diluted by a myriad of common words, but that requires a keyword extraction algorithm which may not always be available.
Tf-Idf Code Example in Python using sklearn
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'Digitiamo is a Startup from Italy',
'Digitiamo is specialized in NLP in Italy',
'Italy is not a Startup'
]
vectorizer = TfidfVectorizer()
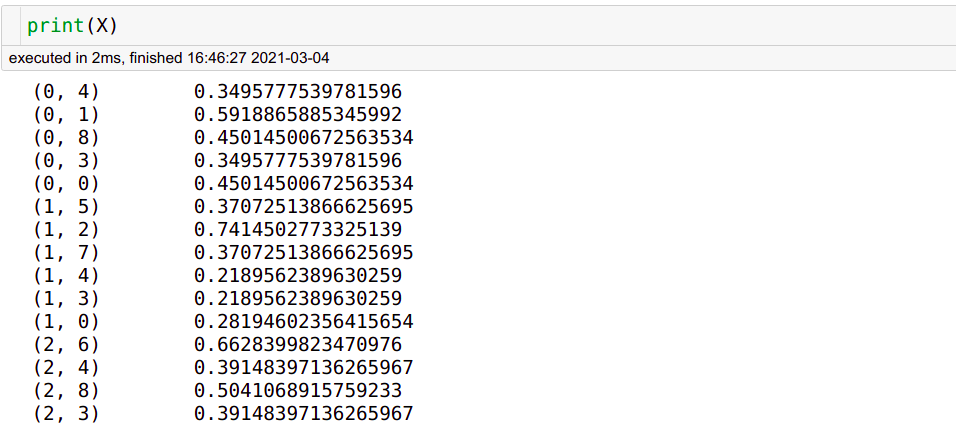
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.shape)
# OUTPUT:
# ['digitiamo', 'from', 'in', 'is', 'italy', 'nlp', 'not', 'specialized', 'startup']
# (3, 9)
# get_feature_names returns the dictionary of words, whereas X.shape # is 3x9: 3 documents, 9 different words. The word ‘a’ has been stopped.
Using GloVe in Python (source)
Once you’ve downloaded a GloVe embedding from the official source, you can use it as shown below (credits to Karishma Malkan)
import numpy as np
def loadGloveModel(File):
print("Loading Glove Model")
f = open(File,'r')
gloveModel = {}
for line in f:
splitLines = line.split()
word = splitLines[0]
wordEmbedding = np.array([float(value) for value in splitLines[1:]])
gloveModel[word] = wordEmbedding
print(len(gloveModel)," words loaded!")
return gloveModel
You can then access the word vectors by simply using the gloveModel variable.
print gloveModel['hello']
Alternatively, you can load the file using Pandas as shown below (credit to Petter)
import pandas as pd
import csv
words = pd.read_table(glove_data_file, sep=" ", index_col=0, header=None, quoting=csv.QUOTE_NONE)
Then to get the vector for a word:
def vec(w):
return words.loc[w].as_matrix()
And to find the closest word to a vector:
words_matrix = words.as_matrix()
def find_closest_word(v):
diff = words_matrix - v
delta = np.sum(diff * diff, axis=1)
i = np.argmin(delta)
return words.iloc[i].name
The file can also be opened using gensim as shown below (credits to Ben), perhaps the best method as it’s consistent with what other methods we’ve seen before in this article and allows you touse gensim word2vec methods (for example, similarity)
Use glove2word2vec to convert GloVe vectors in text format into the word2vec text format:
from gensim.scripts.glove2word2vec import glove2word2vec
glove2word2vec(glove_input_file="vectors.txt", word2vec_output_file="gensim_glove_vectors.txt")
Finally, read the word2vec txt to a gensim model using KeyedVectors:
from gensim.models.keyedvectors import KeyedVectors
glove_model = KeyedVectors.load_word2vec_format("gensim_glove_vectors.txt", binary=False)
Averaging word embeddings to get text embeddings
import re
from gensim.models import Word2Vec
text = 'Digitiamo is a Startup from Italy'
tokenized_text = nltk.word_tokenize(text)
model = Word2Vec([tokenized_text], min_count=1)
modelledText = []
for word in text.split():
word = re.sub(r'[^ws]','',word)
# remove punctuation
modelledText.append(model[word])
embedText = sum(modelledText) / len(modelledText)
# The embeddings are vectors, so the can be added and divided
print(embedText)
Now that we’ve finally gotten the embedding of our texts, we can cluster them as if they were normal numerical data entries!
To find out more about some of the available clustering techniques read the second part of this article, available soon! If you want to be notified when it gets published, subscribe to our newsletter by sliding the tool below (just like an iPhone unlock)
By leveraging and refining the techniques explained in this article we’ve developed AiKnowYou, a product that analyzes and improves the performance of chatbots over time. Feel free to contact us if you’d like to get a better understanding of how it works, or if you’d like to improve the performance of your own chatbots today
Thank you for reading!

About Digitiamo
Digitiamo is a start-up from Italy focused on using AI to help companies manage and leverage their knowledge. To find out more, visit us.
About the Authors
Fabio Chiusano is the Head of Data Science at Digitiamo; Francesco Fumagalli is an aspiring data scientist doing a R&D internship.
Natural Language Clustering — Part 1 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


