



MLOps Notes -1: The Machine Learning Lifecycle
Last Updated on January 5, 2023 by Editorial Team
Author(s): Akhil Theerthala
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
MLOps Notes 1: The Machine Learning Lifecycle
Good day, everyone! And Happy New Year!
Akhil Theerthala here. Because of my personal obligations, I haven’t been able to write articles seriously until now. But finally, beginning today, I will begin contributing once a week to my medium page!
I haven’t taken any online courses in the last two months because I’ve been swamped with work, such as preparing for placements and completing project reports, etc., But now that I’ve started taking the Machine Learning For Engineering (MLOps) Specialization on Coursera and I’ll be sharing my notes on my medium. So, for the time being, check back every two days to catch up on my notes!
What is this course about?
Till now, we have seen the training part of machine learning models. Now it is time for us to see how we put them into production and the challenges and requirements we face in the process. i.e., this course deals with what happens outside the Jupyter notebook.
Example: Let us look at the case of scratch detection of mobile phones. We use a device to identify whether the phone has scratches or not.
Some terms!
Edge Device: device living inside the factories
Software : The program that controls the way edge device works.
In our case, we have inspection software that controls the camera that takes photos and passes them to the control software.
- The control software calls an API, which passes the picture to the prediction server.
- The prediction server has the model, whose job is to predict whether there is a scratch or not.
- This result is sent back to the control software, which behaves in specified ways to classify the phone.
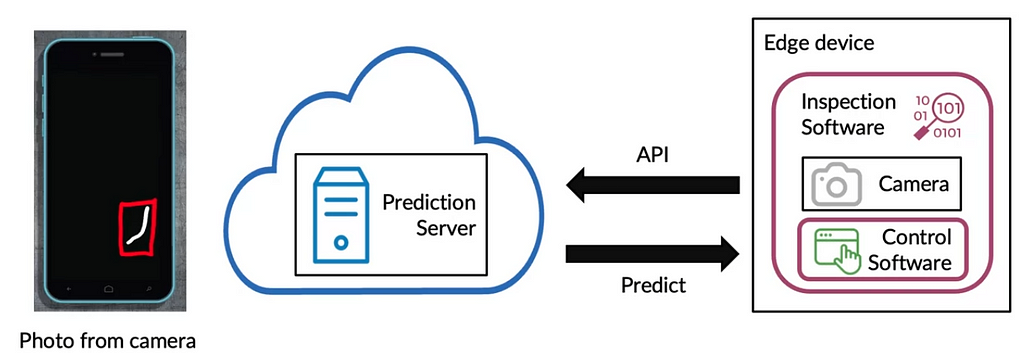
This is generally termed cloud deployment. There is another type of deployment called edge deployment, where the factory keeps running irrespective of the internet connection. The POC (proof of concept) is ultimate the model that we build. But there is a lot out there that makes people believe that this POC is only 5~10% of a production deployment.
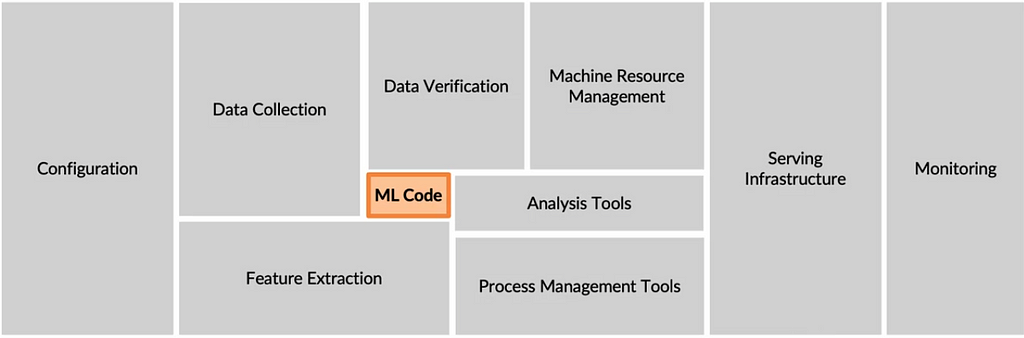
Well, the above image shows the entire components of an ml production deployment. In this course, the goal is to look into all the other processes. One of the easiest ways to look into these other components is to define a lifecycle for the machine learning project and explore each step when needed.
ML System lifecycle:
The generic lifecycle consists of 4 major parts, wherein in each part, we go through different processes or tasks and move on to the next part when satisfied. The parts are
- Scoping the project — Here, we define the project and the requirements and assumptions of the project that we work on.
- Data — Based on the scoping, we define the required data, label them and organize the data.
- Modeling — Using the final processed data, we select and train a model followed by performing error analysis. This is the part that we are most familiar with, and it happens in the Jupyter notebook.
- Deployment — Finally, after testing the model, it is sent to the first deployment into production. After the deployment, we monitor and maintain the entire production system based on feedback from the users.

Steps 3,4 are iterative processes, where, based on the need, we might have to redefine the particular step or retrain the model or some of the previous steps, like changing the assumptions taken or getting more data.
Let us look at an example by using the steps in this cycle: Consider a Speech Recognition system where based on the input audio clip, we will generate the transcript, along with a search function. In each step, we will be asking ourselves a few questions, which makes what we need to do a bit clearer.
Step-1: Scoping
- Defining the project: Speech recognition can have many applications. One such application is speech recognition for voice search.
- What would be our key metrics in this case? (Completely problem dependent)
- Some of the key metrics include accuracy, latency, throughput, etc.,
- What is the target resource consumption? (In this step, we can see how the different systems are performing in the market and define a target)
So mostly, what we do in this step is theoretically define what we have to do and how we do it, along with making necessary assumptions. This part will be discussed in detail later in the course.
Step-2: Data
- Is the data labeled consistently?
- How much silence should we expect in the clip?
- How do you normalize the volume of all the different speakers so that the dataset can have all the voices in the same volume?
This step contains mostly Data scraping, processing, and feature engineering, which makes modeling with this data easier.
Step-3: Modelling
- Select the training model, i.e., selecting the code, Hyperparameters, and Data, gives us the model.
- Generally, in research work, the data is fixed, and the code is played around with. Whereas, in Product Teams, it is found that holding the code fixed and playing around with the data and the hyperparameters is normal and efficient.
- It is recommended that rather than taking a model-centric view, it is also recommended to take a pre-defined opensource models and then optimize it for the code and the data.
- Error analysis for the model is generally help us be more targeted toward selecting the data and verify that the model is working.
Step-4: Deployment
- We can deploy it in the following model, where the edge device is the mobile phone.
- The software uses the microphone and VAD (voice activity detection) module of the edge device (mobile phone) and sends the speech data to the production server.
- The production server processes the request and sends the results according to the request. Generally, this production server is where our model pipeline is stored.
- Later, we have to keep monitoring the system to see for any concept drifts or other issues to make that the production tool delivers the value we envisioned.
The entire step is practically different and is highly application dependent. But the general essence of what we do is we try and deploy the model with a specific deployment pattern and later monitor it. If the model is performing according to our plan, then we go ahead with the full-scale deployment, with constant monitoring for different kinds of errors that can creep up.
In the first course, we will be looking backward, starting from the deployment and then going each step back, i.e., the next article in the series will be on the Deployment part. We will also be looking into MLOps, which is an emerging discipline and comprises a set of tools and principles that support the best practices.
Thanks for stopping by! I will make sure that the next article comes out on January 3, 2023, as planned. So, keep an eye out for it! In the meantime, you can read my articles about my data analytics project or about how the popular Deep Learning Specialization compares to Udacity’s Deep Learning Nanodegree.
MLOps Notes -1: The Machine Learning Lifecycle was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")