



Melting ML Requests by Using SQS and Multiprocessing
Last Updated on January 6, 2023 by Editorial Team
Author(s): Ömer Özgür
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Let’s consider a site that has a lot of users and predicts whether there are dogs in the pictures posted. We need to queue up and process all incoming requests and give users results in a short time.
In my experiments with Flask, I didn’t get the results I wanted and it looks a bit black box. With deep learning, we’ve learned that GPUs aren’t just for gaming. Although GPUs are optimal for training they may encounter limitations in inference.
We can unlock the power of multiple CPUs to speed up the prediction.
In this article these topics will be discussed and presented:
- What is SQS and why to use it
- Why use multiprocessing
- An Experiment and Code
What is SQS
SQS is a fully managed message queuing service from Amazon that lets you decouple and grow microservices, distributed systems, and serverless applications. SQS removes the complexity and expense of managing and operating message-oriented middleware, allowing developers to concentrate on work that is unique. You may transmit, store, and receive messages across software components using SQS at any volume without losing messages or necessitating the availability of other services.
SQS provides two different types of message queues. Standard queues provide high throughput, best-effort ordering, and delivery at least once. SQS FIFO queues are meant to ensure that messages are processed only once, in the sequence in which they are received.
What Are the Benefits of Amazon SQS?
Durability: To ensure the safety of your messages, Amazon SQS stores them on multiple servers. Standard queues support at-least-once message delivery, and FIFO queues support exactly-once message processing.
Availability: Amazon SQS uses redundant infrastructure to provide highly-concurrent access to messages and high availability for producing and consuming messages.
Scalability: Amazon SQS can process each buffered request independently, scaling transparently to handle any load increases or spikes without any provisioning instructions.
Reliability: Amazon SQS locks your messages during processing so that multiple producers can send and multiple consumers can receive messages at the same time.
Pay for what you use: When using SQS, you only get charged for the messages you read and write (see the details in the Pricing section). There aren’t any recurring or base fees.
AWS SQS — Long Polling: When a consumer requests a message from the queue, it can optionally “wait” for messages to arrive and if there is nothing in the queue, this is called Long Polling. Long Polling decreases the number of API calls made to SQS while increasing the efficiency and latency of your application. The wait time can be between 1 sec to 20 sec. Long Polling is preferable to Short Polling. Long polling can be enabled at the queue level or at the API level using WaitTimeSeconds.
Instance selection for effectiveness
There are instances on AWS that are adapted to different jobs. For example, CPU or memory-optimized. We need to Compute optimized machines to do matrix multiplication.
Compute-optimized instances are ideal for compute-bound applications that benefit from high-performance processors. C5, C6, and Hpc6a are examples of compute-optimized instances.
These instances are well suited for the following:
- Batch processing workloads
- Media transcoding
- High-performance web servers
- High-performance computing (HPC)
- Scientific modeling
- Dedicated gaming servers and ad serving engines
- Machine learning inference and other compute-intensive applications
EC2 Inf1 instances are powered by AWS Inferential, a custom chip built by AWS to accelerate machine learning inference. These instances deliver the lowest cost for deep learning inference in the cloud.
Inferential chips with the latest custom 2nd Gen Intel Xeon Scalable processors and up to 100 Gbps networking to enable high throughput inference. This powerful configuration enables Inf1 instances to deliver up to 3x higher throughput and up to 40% lower cost per inference than Amazon EC2 G4 instances, which were already the lowest cost instance for machine learning inference available in the cloud.
Why Multi-Processing ?
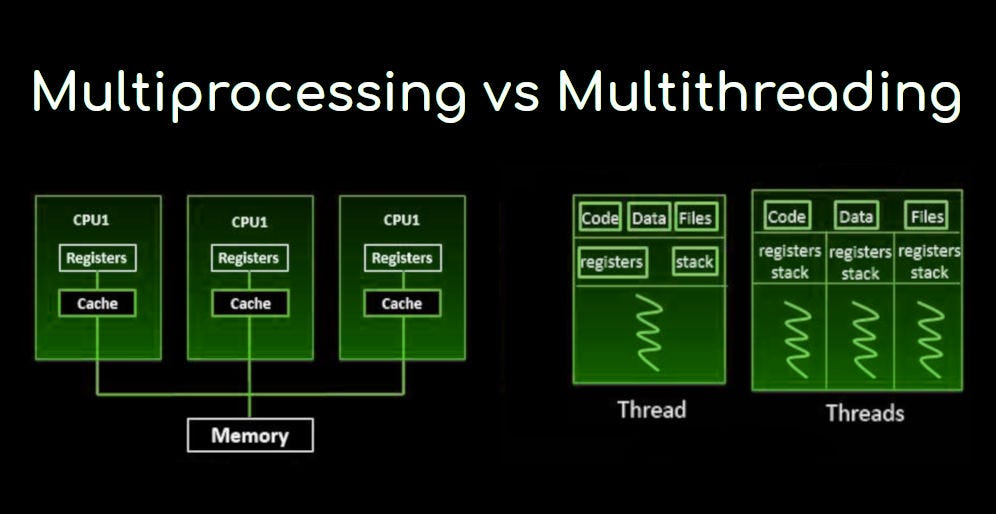
The threading module uses threads, the multiprocessing module uses processes. The difference is that threads run in the same memory space, while processes have separate memory. This makes it a bit harder to share objects between processes with multiprocessing. Multiprocessing takes advantage of multiple CPUs & cores.
Experiments show that multiprocessing is faster and more effective for model inference. As the number of threads increased, a decrease in performance was observed.
Architecture of solution
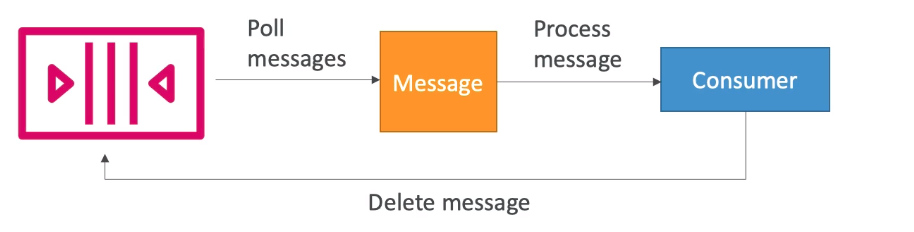
In the architectural plan, the frontend saves the files to S3 and queues them in SQS for processing. EC2 instance constantly checks for SQS, if there is a queue, it processes the element and deletes it from the queue.
EC2 instances have more than one CPU core. By using these cores with multiprocessing we can speed up the process and the queue is cleared quickly. Depending on the number of incoming requests, you can choose the right ec2 instance type.
Let’s Code
- We import our necessary libraries.
- S3fs is required to read files from s3 and will need to add credentials.
- In terms of the experiment, when a picture comes in, we will predict with the pretrained xception model.
- Also, 20 seconds of Long Polling is used by WaitTimeSeconds parameter. In this way, we will reduce the number of unnecessary requests and the costs will decrease.
- The consumer constantly checks the SQS queue and processes the requests. In the code example, we start with 12 of these consumers. The machine I tested had 16 CPU cores. Using less than the number of cores available will be advantageous in terms of creating and managing multi processes.
In this article, we did an experiment on machine learning, but this architecture can be adapted to other problems as well.
Resources
- Amazon EC2 Inf1 instances – New features, improved performance and lower prices
- Compute optimized instances
Melting ML Requests by Using SQS and Multiprocessing was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

