



Live vs Extract Connection: A Road to Tableau Desktop Specialist Certification
Last Updated on March 28, 2022 by Editorial Team
Author(s): Daksh Trehan
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Chapter 4: An extensive guide to Live & Extract data connection, Logical Table & Physical Table in Tableau
Welcome to the fourth chapter, In this piece, we are going to learn about data connections in Tableau and which one should you go for.
If you want to navigate through other chapters, visit: Tableau: What it is? Why it is the best?; A road to Tableau Desktop Specialist Certification.
If you want to directly go on Tableau Desktop Specialist notes, access them here → https://dakshtrehan.notion.site/Tableau-Notes-c13fceda97b94bda940edbf6751cf30
Use the link to get access to free Tableau certification dumps (Valid till 13 Apr 2022):
When we connect our data, Tableau let us define two types of connections: Live & Extract.
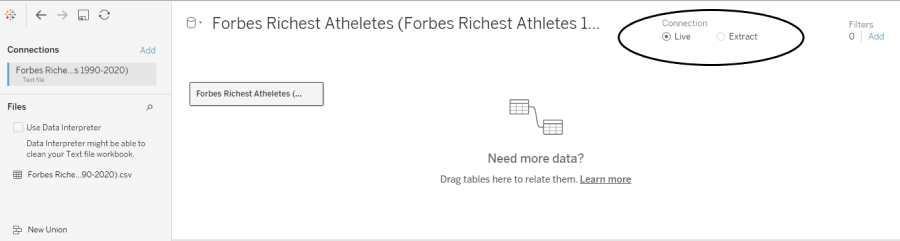
Table of Content
- Live Connection
- Extract Connection
- Selecting a better connection type for your data
- Sample Exam Questions from this topic
Live Connection
As the name suggests, a Live connection is made when we want our data to keep flowing in our Tableau Data source from a dynamic database.
This offers flexibility when we want real-time updates and instantaneous insights.
Live data process queries in the source database.
By default, when we create a connection, it is a Live connection.
Single Cylinder represents Live Connection →
With Live connection, the data in our worksheet would be updated every time we re-open a worksheet or manually refreshes the data.
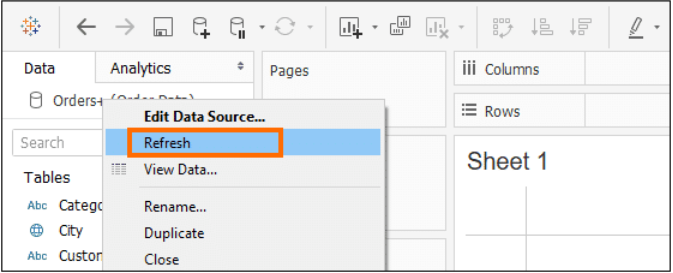
To refresh the live data →
Extract Connection
“Extracts” are one of the most underrated features of Tableau.
An Extract file have .hyper extension(previously referred as .tde)
An extract connection is made over tde. Tableau Data Extract(.tde/also referred to as hyper file) is a compressed snapshot of live data that is stored locally and loaded into memory. To ease off our connection and minimize the load due to complex data, we can apply filters to our data, save it as a .hyper file and later use them for our extract connection. This tends to be much faster than Live Connections and hence provides an edge when used for complex visualizations.
An extract process queries using Tableau Data Engine because a hyper file is so much optimized and efficient that Tableau in-memory Data engine can process queries easily.
An extract is only an extract for that particular workbook, and when it will be shared with others it will act as live data.
Double Cylinder represents Extract connection →
Extracts can’t be updated automatically, but can only be refreshed either manually or periodically.
Extracting Data in Tableau
Method 1
Step1 → Chose “Extract” Connection
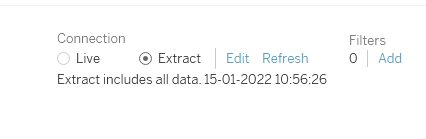
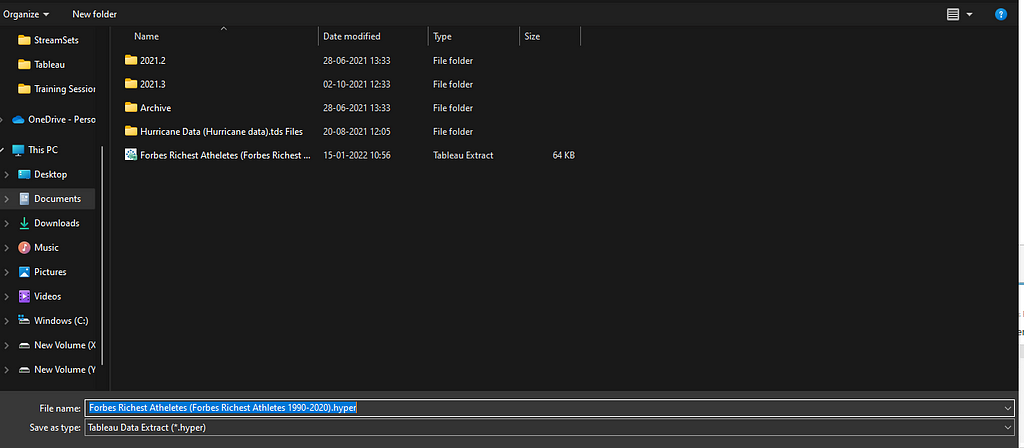
Step2 → When we chose “Extract” Data, Tableau ask for the location of .hyper file.
Method 2
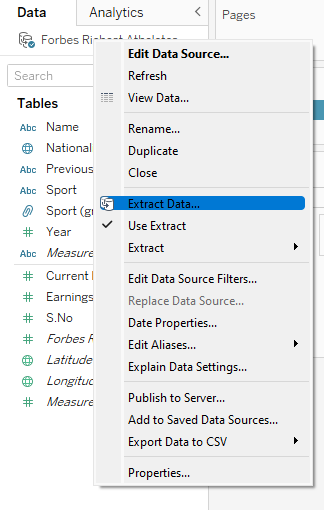
Step1 → Go to the Data pane and right-click on Data Connection and click on “Extract Data”
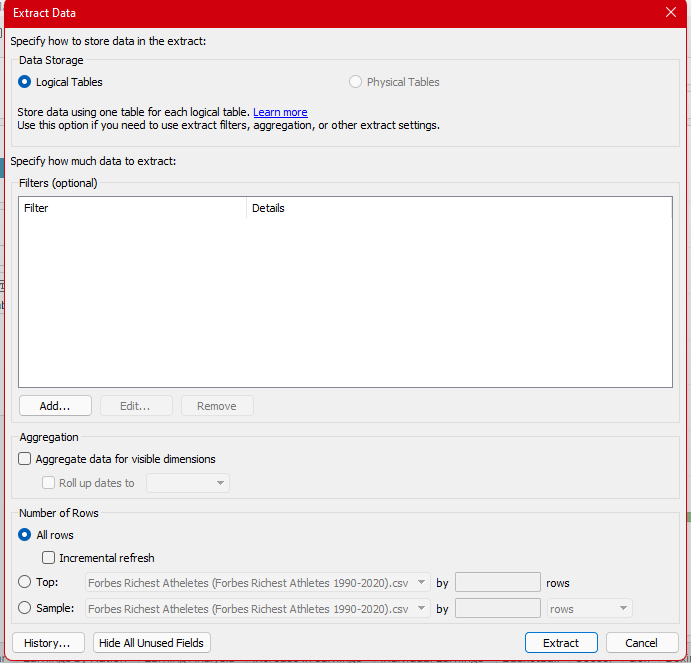
Step2 → Add filters and modify the extract according to your needs.
Refreshing an Extract in Tableau
Once an extract is made and loaded in our Workbook, there are two ways we can refresh our data:
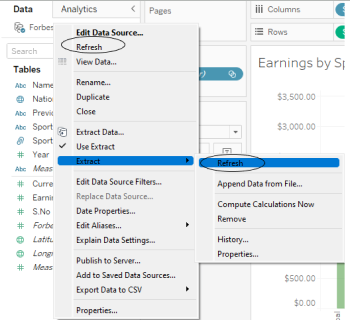
The first option will refresh the connection, but since the connection is static, there won’t be any changes reflected in your data. This option is also present in Live connection and is more specifically to be used when we are working with Live data.
The second option will create a new snapshot of the data i.e. new extract and hence the data in our workbook would be updated.
To periodically refresh the data automatically, we can publish our data to Tableau Server and can choose the time interval for refreshing.
Tableau offers to refresh the data in two ways, we can either go for a full refresh, which replaces all the content in the extract or can use an incremental refresh, which only adds new rows.
(Logical)Single Table vs Multiple(Physical) Table Extraction
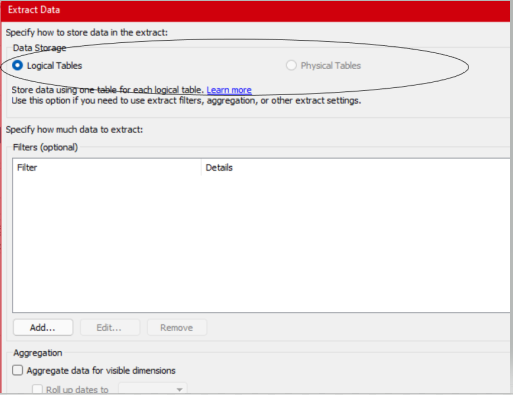
Logical Tables are extracted by default.
Only use Physical tables, when the extract constitutes multiple tables with equality joins and meet the following conditions:
- No RAWSQL.
- No Incremental refreshes.
- No Sampling.
- No Extract Filters.
- Data Types of Columns used for relationship/joins are identical.
- All joins between physical tables are equality joins.
Physical Tables should only be used when the size of our extract is larger than expected while Logical Tables must be used when we want to limit the amount of data in our extract using Filters or aggregations.
Selecting a better connection type for your data
Benefits of Live Connection
- Allows working with real-time data and provides instantaneous insights.
- This connection is suggested if you’re working with a rapid database.
Benefits of Extract Connection
- This can be used if you want a portable dataset.
- It helps us to limit the amount of data we need.
- It improves performance and efficiency.
- These are fast to create and work with.
- These support additional functionalities such as the COUNTD function.
Disadvantages of Extract Connection
- This connection is not suggested while working with sensitive data, as the extract is saved locally and hence can be shared with anyone.
- This requires a manual refresh.
Sample Exam Questions from this Topic
Can we automatically refresh our Extract data?
- True
- False
Solution: True
Why should we not use Extract Data?
- They are slow.
- They might expose confidential data.
- They are difficult to use.
- They can’t be refreshed.
Solution: They might expose confidential data.
What is the extension for extracted data?
- .hyper
- .twb
- .tds
- .tbm
Solution: .hyper
By default, Tableau starts ____ connection.
- Live
- Extract
Solution: Live
Which connection should we use for real-time data?
- Live
- Extract
Solution: Live
Use the link to get access to free Tableau certification dumps (Valid till 13 Apr 2022):
References:
[1] Tableau Help | Tableau Software
[2] Personal Notes
[3]Tableau Desktop Specialist Exam (New Pattern — 2021) — Apisero
Thanks for Reading!
Feel free to give claps so I know how helpful this post was for you, and share it on your social networks, this would be very helpful for me.
If you like this article and want to learn more about Machine Learning, Data Science, Python, BI. Please consider subscribing to my newsletter:
Find me on Web: www.dakshtrehan.com
Connect with me at LinkedIn: www.linkedin.com/in/dakshtrehan
Read my Tech blogs: www.dakshtrehan.medium.com
Connect with me at Instagram: www.instagram.com/_daksh_trehan_
Want to learn more?
How is YouTube using AI to recommend videos?
Detecting COVID-19 Using Deep Learning
The Inescapable AI Algorithm: TikTok
GPT-3 Explained to a 5-year old.
Tinder+AI: A perfect Matchmaking?
An insider’s guide to Cartoonization using Machine Learning
How Google made “Hum to Search?”
One-line Magical code to perform EDA!
Give me 5-minutes, I’ll give you a DeepFake!
Cheers
Live vs Extract Connection: A Road to Tableau Desktop Specialist Certification was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


