



Is GELU, the ReLU successor ?
Last Updated on August 30, 2022 by Editorial Team
Author(s): Poulinakis Kon
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Is GELU the ReLU Successor?
Can we combine regularization and activation functions? In 2016 a paper from authors Dan Hendrycks and Kevin Gimpel came out. Since then, the paper now has been updated 4 times. The authors introduced a new activation function, the Gaussian Error Linear Unit, GELU.
Demystifying GELU
The motivation behind GELU is to bridge stochastic regularizers, such as dropout, with non-linearities, i.e., activation functions.
Dropout regularization stochastically multiplies a neuron’s inputs with 0, randomly rendering them inactive. On the other hand, ReLU activation deterministically multiplies inputs with 0 or 1 dependent upon the input’s value.
GELU merges both functionalities by multiplying inputs by a value from 0 to 1. However, the value of this zero-one mask, while stochastically determined, is also dependent upon the input’s value.
Mathematically, GELU is formulated as :
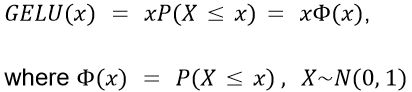
Φ(x) is the cumulative distribution function (CDF) of the standard normal distribution. The choice of this function stems from the fact that neuron inputs tend to follow a normal distribution, especially when Batch Normalization is used. So, essentially GELU has a higher probability of dropping a neuron (multiplying by 0) while x decreases since P(X ≤ x) becomes smaller. Please take a moment to think about this and let it sink. So the transformation applied by GELU is stochastic, yet it depends upon the input’s value through Φ(x).
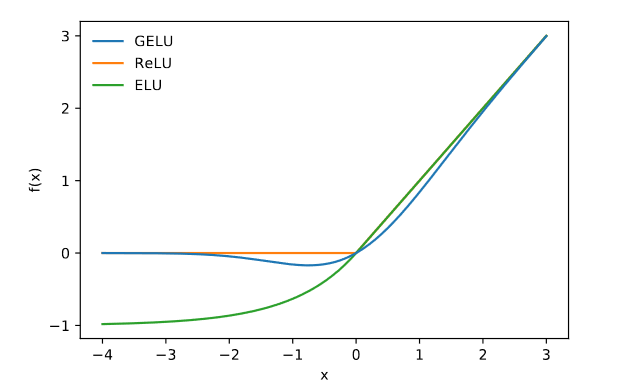
Observe how GELU(x) starts from zero for small values of x since the CDF P(X≤x) is almost equal to 0. However, around the value of -2, P(X≤x) starts increasing. Hence we see GELU(x) deviating from zero. For the positive values, since P(X≤x) moves closer to a value of 1, GELU(x) starts approximating ReLU(x). In the figure below, the red line represents the CDF of the Standard Normal Distribution N(0,1) i.e., P(X≤x).
Approximations
GELU can also be approximated through the formulas
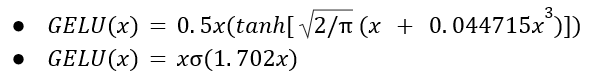
if greater feedforward speed is worth the cost of exactness.
Variations
The GELU can also be modified by using different CDFs. For example, if the Logistic Distribution CDF (x) is used, then we would get the Sigmoid Linear Unit (SiLU) x(x). Moreover, we could pick a CDF N(μ, σ) with μ and σ being learnable hyperparameters.
Advantages
The authors in [1], experimented with the use of GELU against ReLU and ELU activation functions in 3 different benchmark datasets covering the tasks of computer vision (CIFAR 10/100 classification), natural language processing (Twitter part of speech tagging), and audio phoneme recognition (TIMIT frame classification).
Throughout their experiments, they observed a consistent improvement in accuracy when using GELU compared to ReLU, and ELU. Analytically :
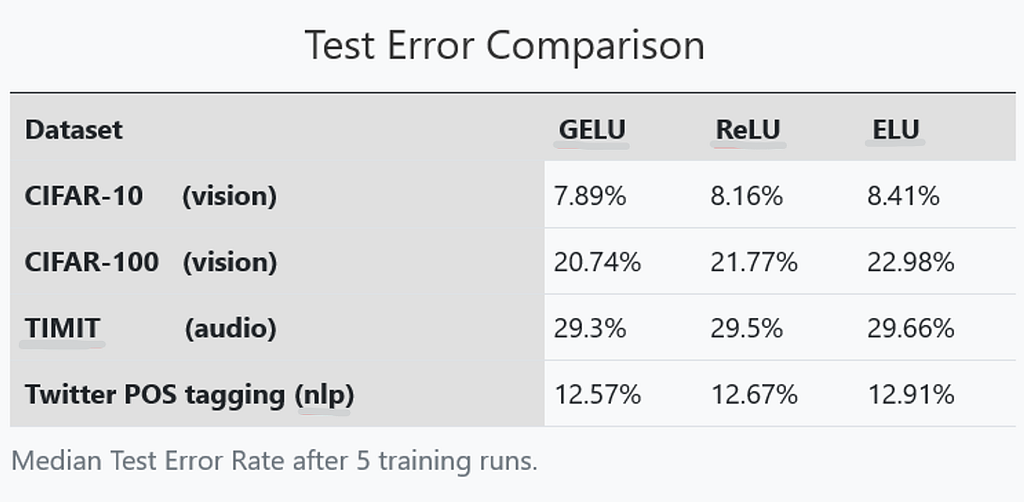
The table above presents the test error rate in 4 datasets. GELU consistently achieves the lowest test error rate, posing as a promising alternative to ReLU and ELU activations.
An Interesting Fact
The well-known paper “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale” that made Vision Transformers popular makes use of GELU activation inside the MLP of the encoder transformer block (section 3.1). This suggests that GELU is considered a good option by high-quality researchers.
REFERENCES
[1] Gaussian Error Linear Units (GELUs)
[2] https://en.wikipedia.org/wiki/Normal_distribution
[3] An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
Thanks for reading, feel free to reach out!
My Links: Medium | LinkedIn | GitHub
Is GELU, the ReLU successor ? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



