


Introductory Notes on Stable Diffusion and Stable Video Diffusion
Last Updated on December 30, 2023 by Editorial Team
Author(s): Nieves Crasto
Originally published on Towards AI.
Stable diffusion represents a cutting-edge approach to image generation. Generative models, such as Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs), and more recently, Diffusion models, enable the generation of new, realistic images based on patterns learned from existing data. This process has applications in diverse fields, from art and design to medical imaging and data augmentation in machine learning.
Image generative models, specifically GANs, use noise as input to the network, to generate an image (Figure 1). One significant challenge with GANs is the complexity of their training process. Additionally, attempting to transition from a chaotic noise input to a clean image in a single step is a formidable task!

Instead of making a single leap from complete noise to an image, why not approach it in incremental steps?
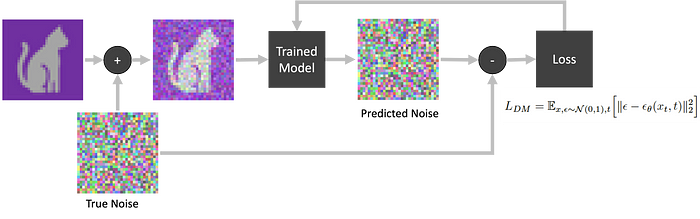
The concept involves gradually reducing noise step by step (Figure 2). The idea is to take a noisy sample and employ a trained network to predict the noise within it. The predicted noise is then subtracted from the original image, resulting in a less noisy image. The word ‘diffusion’ in physics is defined as the process in which particles move from a region of high concentration to a region of low concentration till equilibrium is reached. The process of incrementally reducing the noising could be viewed as a process of reverse diffusion.

Understanding the Training Process: Forward Diffusion + Image Space to Latent Space
In the initial training phase, we start with a clear image and progressively introduce increasing levels of noise — a process known as forward diffusion.

Instead of operating directly in the image space, which can be computationally intensive, we employ an encoder to transform our high-dimensional image into a more manageable, smaller-dimensional representation termed the latent space (Figure 3). By transitioning to this reduced dimensionality, computations become more efficient and streamlined. During the forward diffusion stage, our primary action revolves around introducing noise; it’s here that we determine the amount of noise to incorporate, ultimately producing our desired noisy image.
Understanding the Training Process: A Step-by-Step Breakdown

Firstly, select a random time step based on a predefined noise schedule — let’s say we choose time T = 5, which indicates a specific noise level. Next, this designated noise is added to the image, resulting in a noisy version that is then inputted into our network, specifically the UNet. The UNet’s role here is pivotal; it predicts the noise component, allowing us to discern the difference between the forecasted noise ϵ Θ— where Θ represents the network parameters — and the actual noise, denoted as ϵ, corresponding to the chosen time step T (Figure 5). This discrepancy serves as the foundation for our loss function, guiding the iterative training process of our network.
Understanding the Training Process: Integrating Control through Prompts and Conditioning
Indeed, while the foundational aspects of image generation are fascinating, there’s a pivotal component yet to be addressed: control. Imagine providing a prompt, such as “generate an image depicting a sunny day” — this interactive aspect remains absent from our discussion thus far. Within this framework, conditioning is intricately woven through the upsampling part of the UNet. Leveraging a text encoder, words are transformed into vectors, which are then integrated into the network embeddings. Additionally, the time embedding (related to the timestep and noise level) is also integrated into the network embedding (Figure 6). Essentially, this process amalgamates textual prompts, time elements, and contextual nuances to refine and steer the image generation process toward desired outputs.

Evaluating Generative Models: Unraveling the Metrics and Methodologies

As we immerse ourselves in the myriad of generative models, including various diffusion models, a pressing question emerges: how do we objectively evaluate their performance? Given the inherently qualitative nature of generated images, distinguishing between superior and subpar models becomes a nuanced challenge. Enter CLIP — a pivotal tool in this evaluative landscape. For context, CLIP stands for Contrastive Language-Image Pretraining, which can be used to assess the alignment and quality between textual prompts and generated visual outputs. To elaborate, the mechanism involves encoding both the image and text into a shared vector space, facilitating a straightforward dot product evaluation. A high score indicates alignment, while a lower score suggests divergence between the image and its textual representation.
Another intriguing approach is the directional CLIP loss methodology. Here, the evaluation pivots around analyzing the rotational adjustments between reference and generated images and texts. For instance, by juxtaposing images of contrasting scenes — say, a sunny day versus a rainy one — and their respective textual descriptions, one can gauge the alignment shifts in both image and text embeddings.
Venturing Beyond Images: The Evolution Towards Video Generation
As we continue to push the boundaries of image generation, the natural progression beckons us toward the realm of video creation. Recognizing this shift, innovators are now setting their sights on mastering the temporal dimension, complementing the spatial intricacies already achieved. A noteworthy stride in this direction is the advent of stable video diffusion — a cutting-edge approach that has garnered significant attention for its promising outcomes.
Training this model involves three stages: first, is the text-to-image pretraining, synonymous with stable diffusion as we’ve explored earlier; second, video pertaining, existing image diffusion model is modified to include temporal convolutions; and finally, high-quality video fine-tuning.
Unraveling the Data Collection Process for Video Generation
Training image generation models involved creating datasets around pairing images with captions. Similarly, for video models, the imperative is to match videos with relevant captions. So, how did they assemble this expansive dataset?
Initially, the approach centered on sourcing extensive collections of lengthy videos. One inherent challenge with long-form videos lies in abrupt scene transitions or cuts, complicating the modeling process. To circumvent this, they employed tools adept at identifying these abrupt shifts, enabling the segmentation of videos into more manageable clips across varying frame rates. Notably, they leveraged a tool called “PySceneDetect,” which is designed to pinpoint scene changes and partition videos accordingly.
Once the clips were segmented, the next step entailed 3 step annotation process.
- Step 1: The image captioner, CoCa is used to caption the mid-frame of each clip.
- Step 2: The video captioner, V-BLIP is used to caption the entire clip. Step 3: The third caption is generated by summarizing the above two captions using a Large-Language Model (LLM).
This resulted in an extensive dataset comprising an astounding half-billion clips, translating to a staggering 200 years of content.
Refining the Dataset: Enhancing Quality and Aesthetic Value
Firstly, clips characterized by minimal motion or an overwhelming text presence were identified for exclusion. Optical flow analysis was used to eliminate low-motion images. Concurrently, Optical Character Recognition (OCR) was leveraged to identify clips with excessive text, ensuring their removal from the dataset.
Further refinement involved the exclusion of clips with diminished aesthetic value. CLIP score was used to evaluate the alignment between generated captions and their corresponding videos. Clips failing to meet the desired score threshold were systematically filtered out. The resulting dataset comprised approximately 10 million videos.
Model Architecture: Video Pretraining and the Fusion of Spatial and Temporal Dynamics
The incorporation of temporal convolution in the stable diffusion model is inspired by the insights from a paper titled “Align Your Latents”. They introduce additional temporal neural network layers, which are interleaved with the existing spatial layers, to learn to align individual frames in a temporally consistent manner (Figure 8).
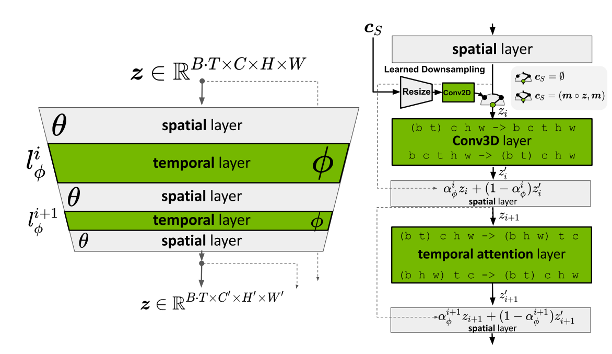
Model Initialization and Training: A Three-Phase Approach
To lay a robust foundation, the model is primed using the weights from a pre-existing image model. Following this initialization, it undergoes rigorous training on a meticulously curated video dataset. As we progress, the model is further fine-tuned, leveraging a specialized dataset enriched with 250K pre-captioned video clips distinguished by their superior visual fidelity. This sequential approach ensures optimized performance and fidelity throughout the training continuum.
I hope this article gives you insight into how diffusion techniques can be applied in the field of image and video generation.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


