



Introduction to Computer Vision
Last Updated on July 25, 2023 by Editorial Team
Author(s): Vijay Vignesh
Originally published on Towards AI.
Computer vision (CV) is a field of computer science that focuses on enabling computers to understand and interpret visual data from images or video. It basically tries to replicate human vision capabilities in various visual tasks such as object detection and recognition, image classification, object tracking and so on. Computer Vision can be applied to a variety of applications like Autonomous Vehicles, Facial Recognition, Medical Imaging, and Robotics, to name a few.
At a very high level, Computer Vision can be divided into two parts:
1. Machine Learning based Computer Vision
2. Deep Learning based Computer Vision
Machine Learning based Computer Vision
In this form of CV, we extract features using classical image processing and feed them to a machine-learning model. Feature extractors are algorithms that aim to extract discriminative features from images. These features represent specific patterns present in the image, which are used to differentiate between different objects. Then, traditional machine learning algorithms, such as support vector machines (SVMs) or random forests, are used to process and interpret the extracted features. It relies on handcrafted features that are manually designed and extracted from images, requiring domain expertise and manual effort. I’ll give a brief explanation of some of the commonly used feature extractors below. Please note that this is by far not an exhaustive list.
Edge Detection
Edge detection is a fundamental technique in image processing that aims to identify the boundaries of objects in an image. This can be done by noting the fact the boundaries are places where the intensities of pixels change drastically from the inside of the object to the outside.
Corner Detection
Corner detection aims to identify the corners or interest points in an image. Unlike edges, which exhibit intensity changes in a single direction, corners are characterized by substantial intensity variations occurring in multiple directions simultaneously.
Histogram-based feature extraction
Histogram-based feature extraction is a technique used to represent and analyze the distribution of pixel intensities in an image. The histogram basically provides a visual summary of how the pixel data is distributed across different ranges or bins.
So, the basic steps involved in this form of CV are:
- Read the image.
- Preprocess the image.
- Use Feature extractors to extract relevant features.
- Feed the features to a machine learning model.
Deep Learning based Computer Vision
In this form of CV the entire process of extracting features and inferring meaning from them are encapsulated and automated in one single complex deep learning model, specifically the Convolutional Neural Networks (CNNs). Given a huge repository of data, CNNs are capable of learning and extracting meaning from the data by themselves without human intervention. Although this type of CV looks much more promising and accurate than the previous one, we need a huge amount of data to train these models. A brief explanation of CNNs and their components is given below.
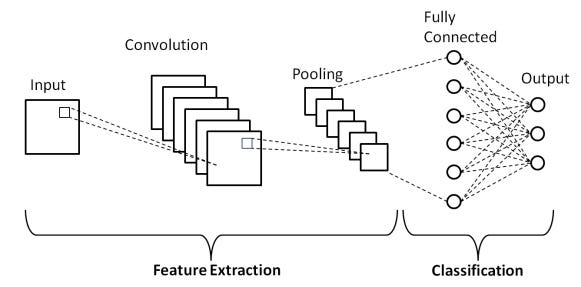
Convolutional Neural Networks is a deep learning algorithm that is used to analyze visual data like images and videos. CNNs are made up of several components:
Convolutional Layers
These are the core building blocks of a CNN. These layers consist of multiple learnable filters or kernels that search the input image for a specific pattern. This is similar to the feature extraction phase of the Machine Learning based CV, with the exception that it is automated.
Pooling Layers
Pooling layers reduce the spatial dimensions (width and height) of the feature maps while retaining the most relevant information. They are basically used to reduce the dimension of the feature maps and reduce computation.
Fully Connected Layers
At the end of the convolutional and pooling layers, the feature maps are flattened into a vector and passed through one or more fully connected layers. These are similar to the final machine learning model in the Machine Learning based CV type. We can imagine the machine learning model to be a fully connected neural network.
Both machine learning-based and deep learning-based computer vision approaches have their own strengths and limitations, and their suitability depends on the specific project requirements, such as the complexity of the task, availability of labeled data, computational resources, and desired performance.
That’s it, folks! Hopefully, you now have an overall idea of Computer Vision. While Computer Vision is an exciting topic, it is extremely vast. In future blogs, I would like to pick each topic and dig deeper into them and explain them with code.
See you soon!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

