



Incremental Machine Learning for Linked Data Event Streams
Last Updated on February 13, 2023 by Editorial Team
Author(s): Samuel Van Ackere
Originally published on Towards AI.
Unlocking the Power of Real-time Predictions: An Introduction to Incremental Machine Learning for Linked Data Event Streams
This article discusses online machine learning, one of the most exciting subdomains of machine learning theory. The potential of using incremental machine learning becomes more and more apparent when working on fast-moving Linked Data Event Streams (LDES).
With the conventional machine learning method, a lot of time is lost when training models from scratch repeatedly. It is better to use all parameters of previously trained models to arrive at faster predictions and analyses of fast-moving Linked Data Event Streams. A practical example applied to forecasting a Linked data event stream is used to show its potential.
Linked Data Event Stream
A data stream is typically a constant flow of distinct data points, each containing information about an event or change of state that originates from a system that continuously creates data. More comprehensive, a Linked Data Event Stream is a constant flow of immutable objects (such as version objects, sensor observations, or archived representation), each containing information about an event or change of state that originates from a system that continuously creates data.
It is the linked data version of data event streams, which is considered the core API of fast- and slow-moving data.
For more info about this, please read this article on medium:
Linked Data Event Streams explained in 8 minutes
Incremental or Online Machine Learning
Of all services that can be built on top of one or more Linked Data Event Streams, a machine learning service is one of them. The concept of an ML-LDES server is that you can send an LDES via HTTP POST request, after which the ML-LDES server can harvest the data in real-time and run a machine-learning model on some relevant parameters in the LDES. To show the potential of such an ML-LDES server, we showcase an incremental forecasting model on an Internet of Water (IoW) LDES.
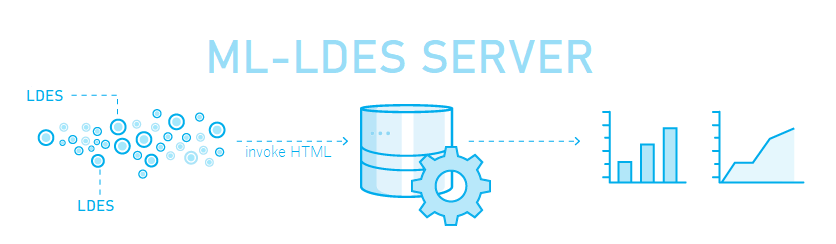
But first things first, what is incremental or online machine learning? Conventional machine learning algorithms train a model on the full training dataset at once. A potential disadvantage is that they frequently create new models from scratch rather than continuously integrating new data into already-built models. This could result in outdated models and take a lot of time to retrain the model every time from scratch.
Unlike these batch learning techniques, incremental learning or online machine learning updates the best predictor for future data at each step as new data becomes available.
Online learning and incremental learning have recently drawn attention, particularly in the context of big data and learning from data streams. This contradicts the conventional premise that all data is available at all times.
Continuous adapting of a machine learning model based on a stream of data that keeps coming in is known as incremental learning. With incremental learning, the machine learning model should adapt to new data while maintaining its prior understanding.
An online learner needs to make predictions about a sequence of instances, one after the other and receives feedback after each prediction. Danny Butvinik
Machine learning entails instructing a model one sample at a time during training. Therefore, an online model is a stateful, dynamic object. It never needs to review old data because it is constantly learning.
Data event streams are often incrementally analyzed, and real-time aggregation, enrichment, transformation, correlation, filtering, or sampling are conducted on the fly. As a result, it enables the possibility to detect emerging trends, strange events, and substantial departures from the norm, approaching alarming limits. Afterward, real-time answers and data-driven decisions can be made by it.
Linked data event stream (LDES) of Internet of Water case (IoW)
First, the Linked Data Event Stream is fetched by the LDES client, after which all LDES members are sent via HTTP request to the ML-LDES server.
 LDES workbench in Apache NIFI (Image by the author.)
LDES workbench in Apache NIFI (Image by the author.)
An example of one of those LDES members is added underneath:
 N-triple flow file fragment (Image by the author.)
N-triple flow file fragment (Image by the author.)
If we convert this N-triple to a Terse RDF Triple language (for easier interpretation), we get this:
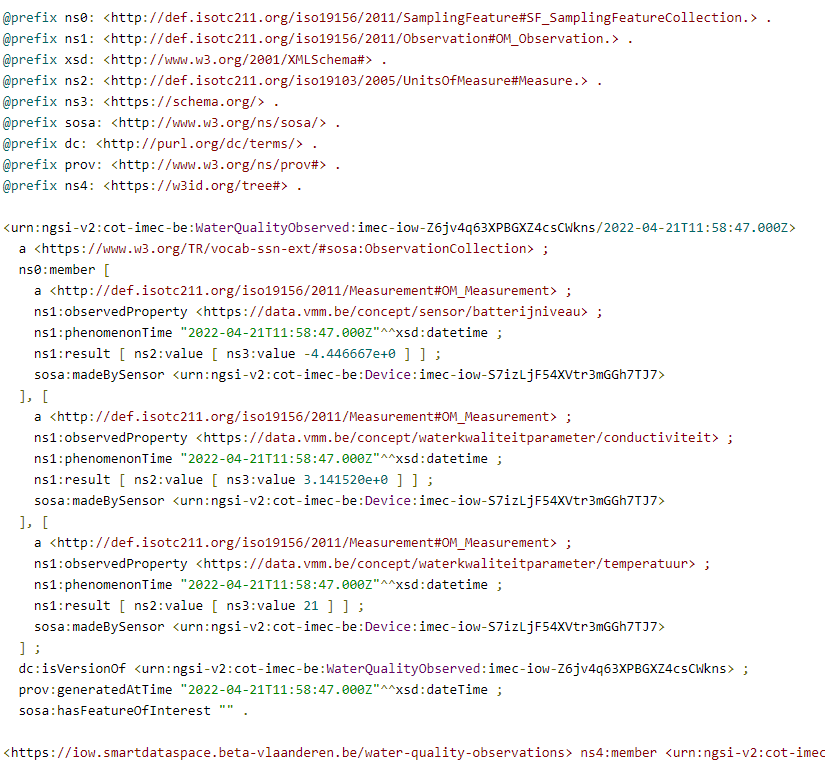 Turtle output of one LDES member (Image by the author.)
Turtle output of one LDES member (Image by the author.)
Incremental forecasting with River
River is the sklearn library for machine learning on streaming data, Alexandra Amidon
River is a Python library composed of numerous classes that carry out different online processing methods. Most of these classes are machine learning models that can analyze a single sample for learning or inference purposes.
For the IoW case, we use the SNARIMAX forecasting module. SNARIMAX stands for Seasonal Non-linear AutoRegressive Integrated Moving-Average with eXogenous inputs model.
It is a time series forecasting model that considers the data’s trend and seasonality, as well as any additional predictor variables (also known as exogenous variables) that may be relevant for forecasting.
In the SNARIMAX model, the “seasonal” component accounts for periodic fluctuations in the data (such as monthly or quarterly cycles). The “natural additive” component accounts for long-term trends and patterns, and the “regressive” feature allows the model to incorporate the influence of one or more predictor variables on the forecast. The “integrated” and “moving average” parameters of the model help to smooth out short-term fluctuations and noise in the data.
Now to perform an incremental learning model on the time-series values of the Linked Data Event Stream, all RDF members are pulled in one by one (and remain in sync with the CoW (City of Water) sensor). The code snippet below illustrates what such an RDF member roughly looks like (simplified). As soon as a new RDF member is available, the LDES Client reads this value and sends it to the incremental learning model. This model will run a new forecast starting from the parameters it already had from its previous forecasting.
We can visualize this continuous prediction per point in time and plot the whole data stream at once underneath it. In that case, we see how the incremental learning process becomes better and better in predicting future values.
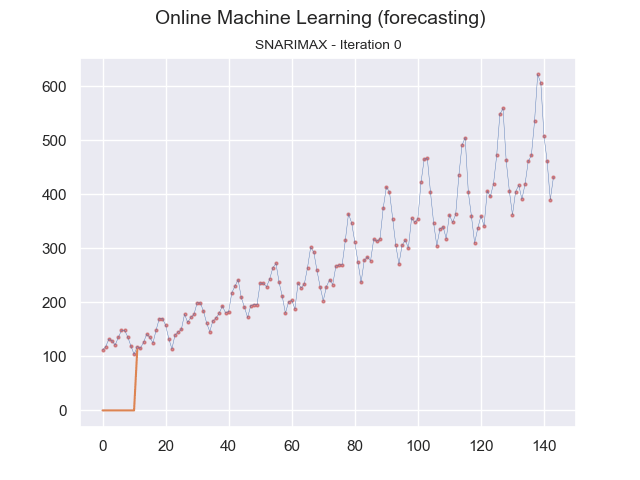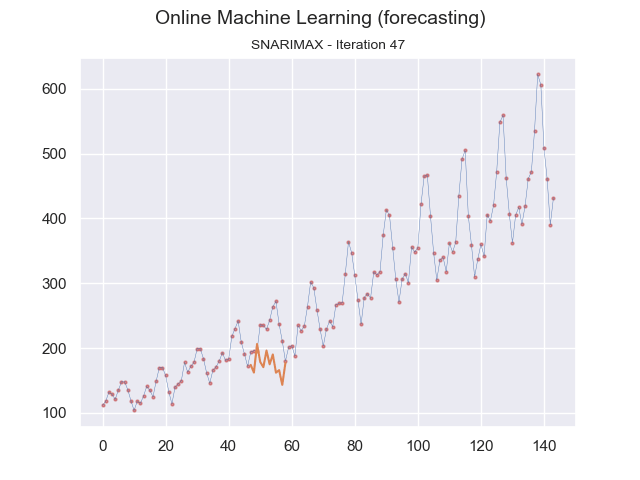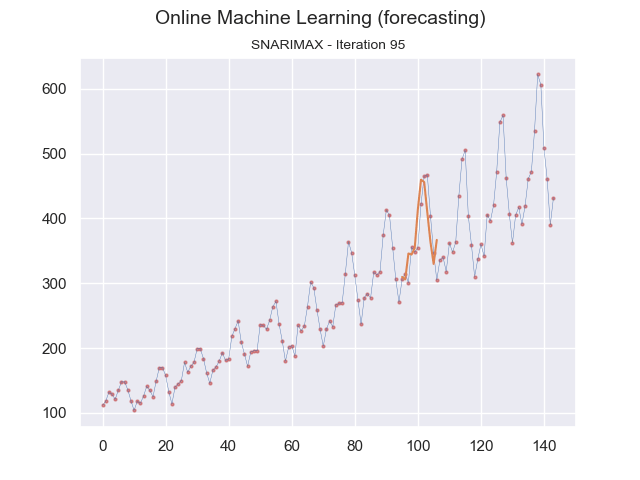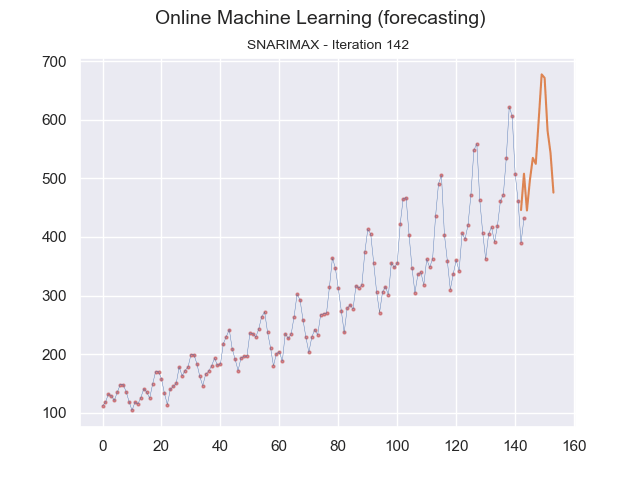 Image by the author.
Image by the author.
Note that in the graph above, the plotted time series data is for reference and is not used in one batch to learn the model. Instead, at each iteration, the data sample is sent to the model for learning.
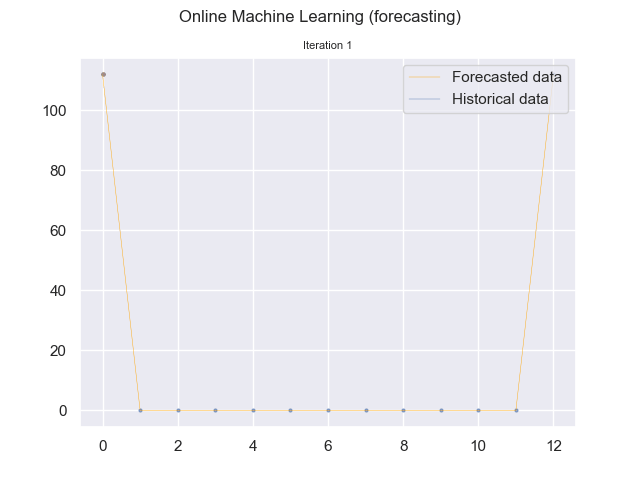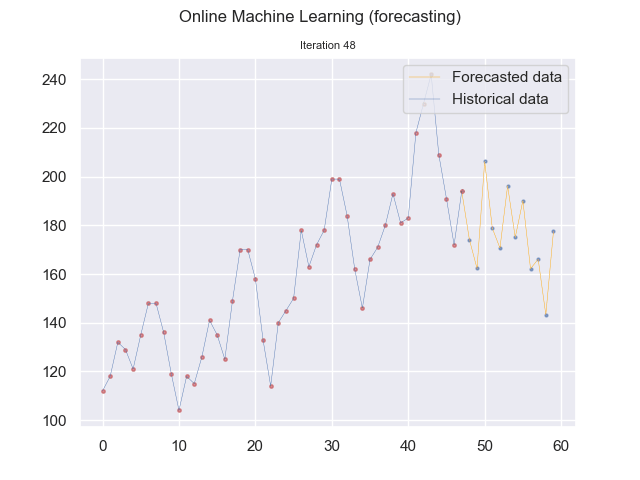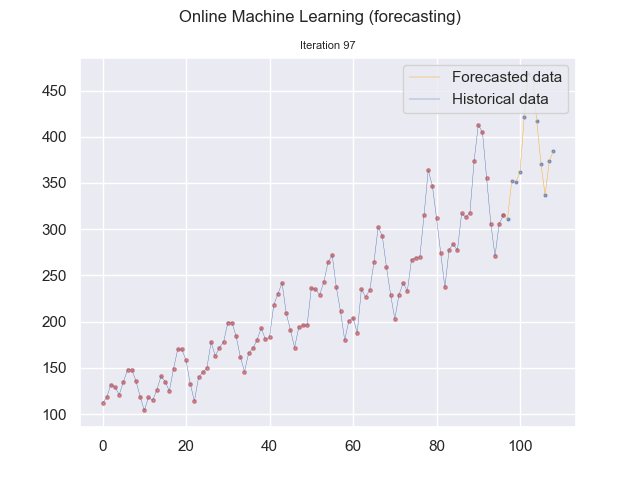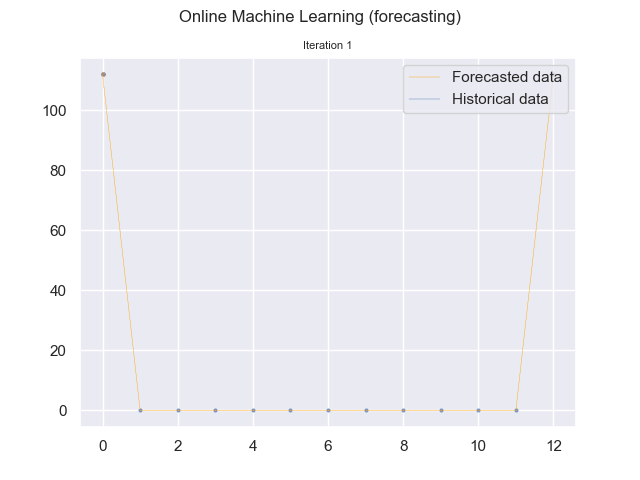 Online machine learning (forecasting) using SNARIMAX method (Image by the author.)
Online machine learning (forecasting) using SNARIMAX method (Image by the author.)
When we use this Snarimax forecasting model for the IoW case, it is important to use the correct Snarimax parameters (p: Order of the autoregressive part, d: Differencing order, q: Order of the moving average part, m: Season length used for extracting seasonal features, sp: Seasonal order of the autoregressive part, sd: Seasonal differencing order, sq: Seasonal order of the moving average part). This is demonstrated in the figure below. See River specs for more info.
 It is important to use the correctly chosen, applicable Snarimax parameters when running a forecasting model (Image by the author.)
It is important to use the correctly chosen, applicable Snarimax parameters when running a forecasting model (Image by the author.)
To demonstrate how well the Snarimax model scores, we evaluated the model each time on the last twelve forecast points against the reference value and calculated a Mean Absolute Error of this.
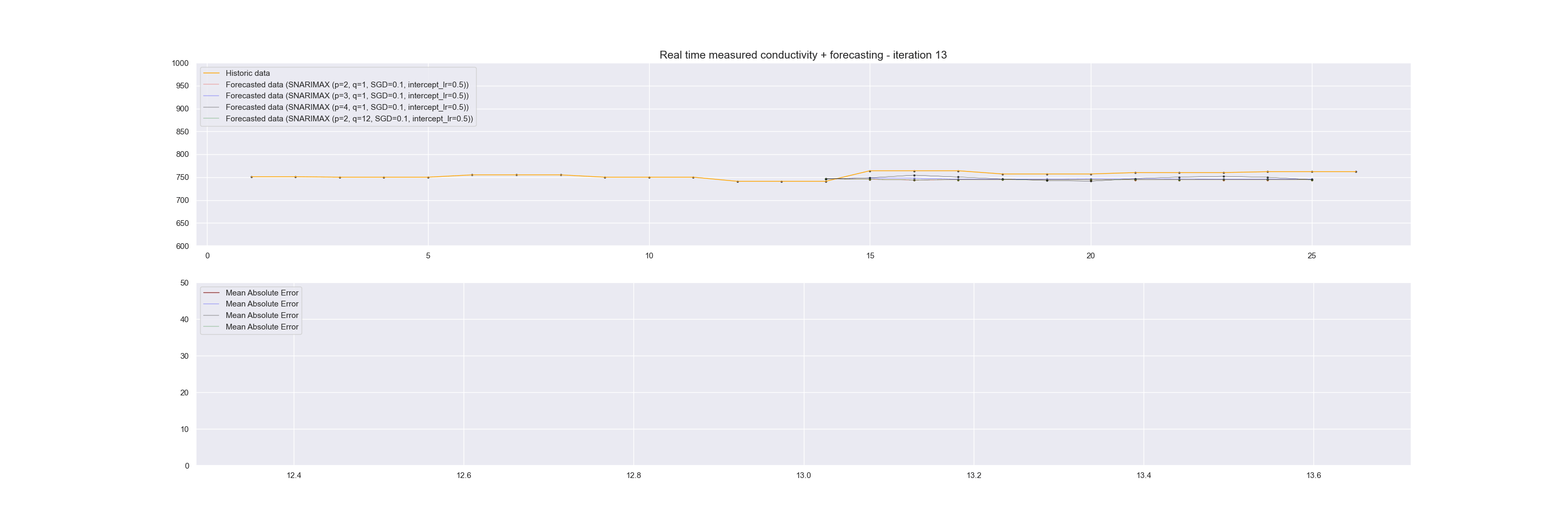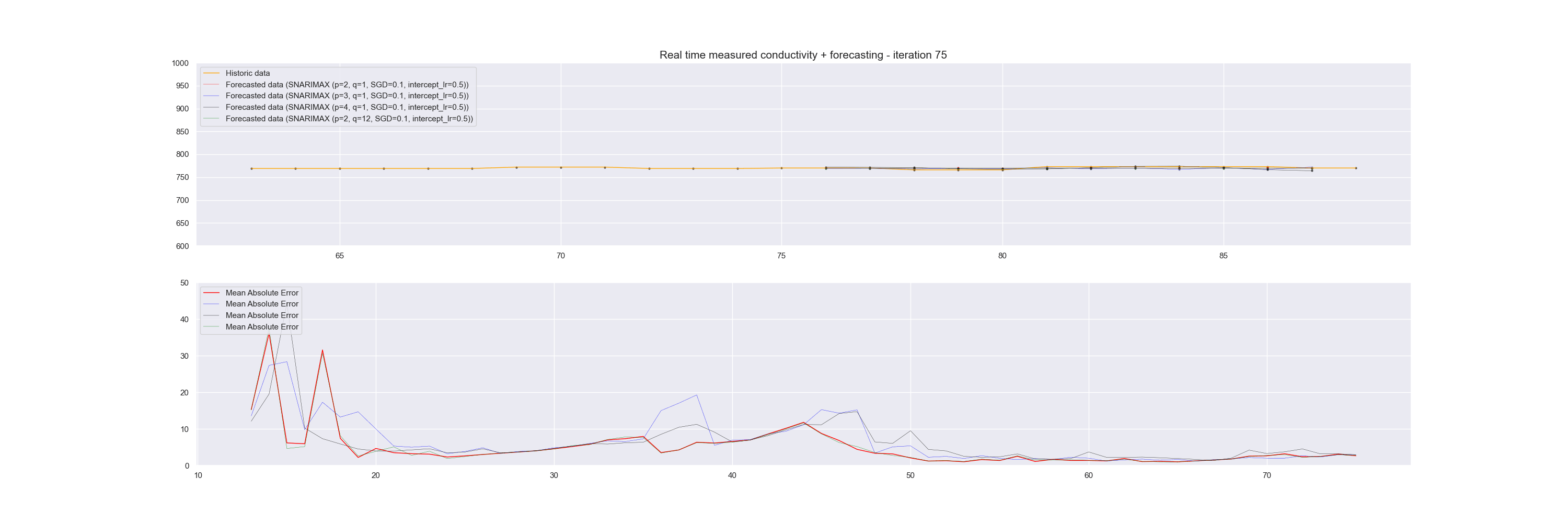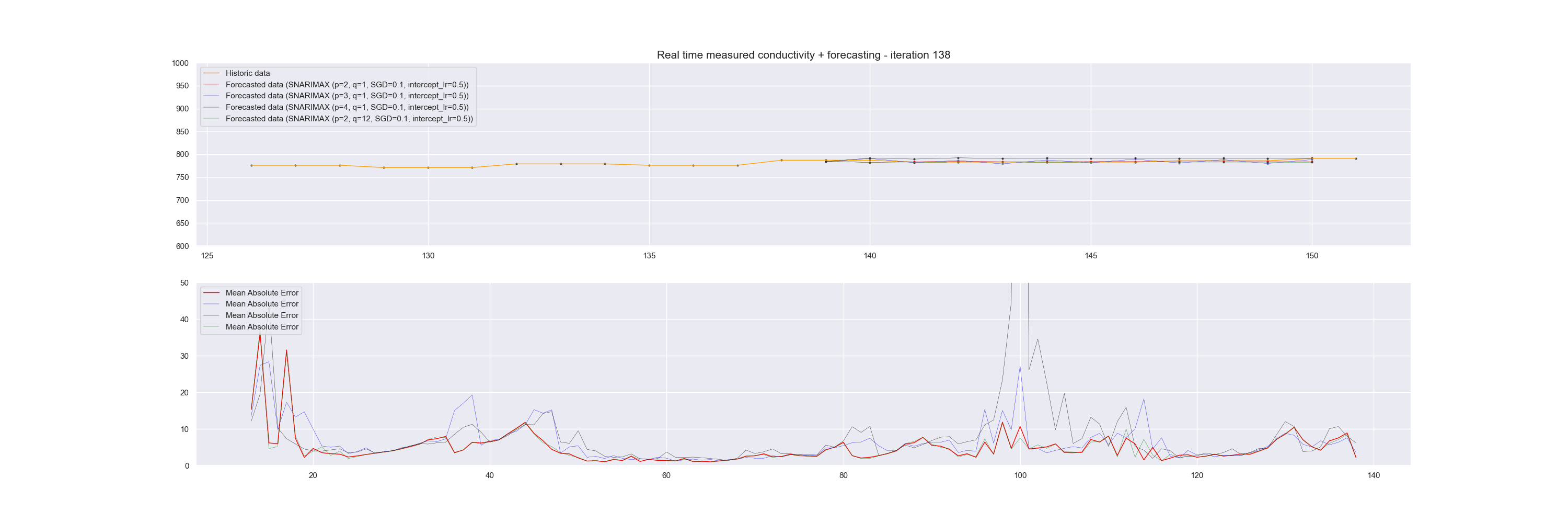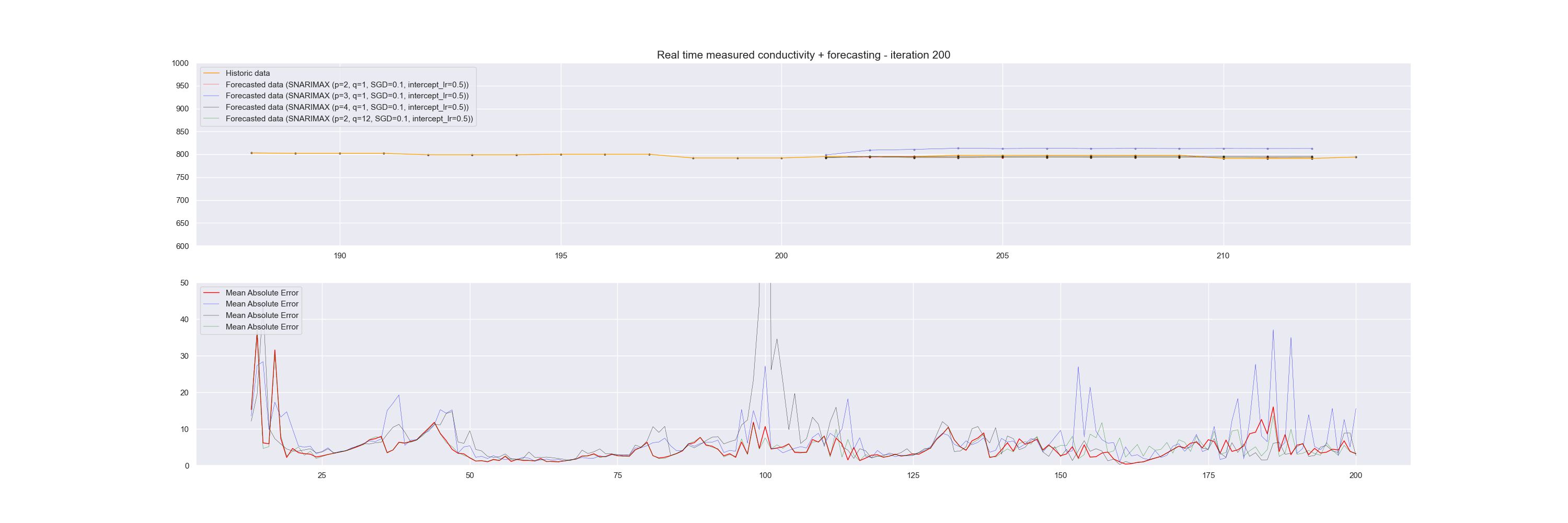 Snarimax forecasting of a Linked Data Event Stream with accompanying Mean Absolute Error
Snarimax forecasting of a Linked Data Event Stream with accompanying Mean Absolute Error
This article demonstrates how incremental learning can be applied to Linked Data Event Streams. At the time of writing, there was only data available over a time period of two weeks, with only a slight variation in the reference value.
Conclusions
The use of incremental learning offers numerous benefits over conventional machine learning methods, allowing for faster predictions and analyses of linked data event streams. The SNARIMAX forecasting module within River, which considers seasonal fluctuations, long-term trends, and exogenous variables, provides a practical example of the potential of incremental learning in real-world applications.
To replicate the data flow in this article, please go to the ML-LDES server. It describes how to set up the dockerized PostgreSQL/PostGIS, PgAdmin, and Apache NiFi, after which the data flow can be started using the supplied Apache NiFi setup file.
ML-LDES-server/server_forecasting_snarimax.py at master · samuvack/ML-LDES-server
References
[1] Van Lancker, D., Colpaert, P., Delva, H., Van de Vyvere, B., Rojas Melendez, J. A., Dedecker, R., … Verborgh, R. (2021). Publishing base registries as linked data event streams. In M. Brambilla, R. Chbeir, F. Frasincar, & I. Manolescu (Eds.), WEB ENGINEERING, ICWE 2021 (Vol. 12706, pp. 28–36). https://doi.org/10.1007/978-3-030-74296-6_3
[2] river — River. (n.d.). Retrieved February 7, 2023, from https://riverml.xyz/0.15.0/
[3] Linked Data Event Streams. (n.d.). Retrieved February 7, 2023, from https://semiceu.github.io/LinkedDataEventStreams/
[4]European commission. (n.d.). Publishing data with Linked Data Event Streams: why and how. Retrieved February 7, 2023, from https://academy.europa.eu/courses/publishing-data-with-linked-data-event-streams-why-and-how
If you like what you read, be sure to ❤️ it — as a writer, it means the world. Stay in touch by following me as an author.
Contributors to this article are ddvlanck (Dwight Van Lancker) (github.com), sandervd (Sander Van Dooren) (github.com) at Smart Data Space (Digital Flanders). In a rapidly changing society, governments need to be more agile and resilient than ever. As a strategic partner, we realize and supervise digital transformation projects for Flemish and local governments.
Incremental Machine Learning for Linked Data Event Streams was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

