


Improving Accuracy of Text Extraction with Simple Techniques
Last Updated on July 25, 2023 by Editorial Team
Author(s): Chinmay Bhalerao
Originally published on Towards AI.
understanding data and problem statements to make predictions better
Text extraction has a lot of applications in extracting text from images, scanned documents, and pdfs. There are many modules that we can use with python to extract texts, like pytesseract, easyOCR, Keras OCR, and many… But many times, we don't get output as we want due to the constraints of these libraries. We can use many simple techniques with libraries to make our output better. Let's see how we can improve output in this blog.
Part1:Simple text extraction
Importing basic libraries
import cv2
import pytesseract
import pandas as pd
We will use pytesseract for text extraction because it is most commonly used for text extraction applications.
new_dict = []
#read image
img = cv2.imread(r'Raw image address')
cv2.imshow('Test image', img)
# cv2.imwrite(filename, edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
Now we will read the image.
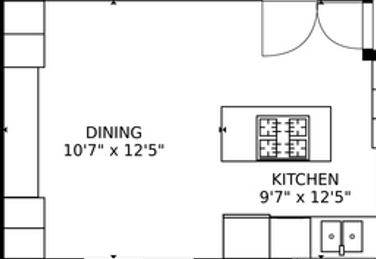
I purposefully took the harder image with a lot of noise because we wanted to see the performance of simple text extraction on the complex images.
Let's start text extraction.
# configurations
config = ('-l eng --oem 1 --psm 8')
# pytessercat
pytesseract.pytesseract.tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
text = pytesseract.image_to_string(img, config=config)
If you downloaded pytesseract, then the above one should be the location to store it. It will help you execute and use all language models effectively.
In the text variable, we are storing all texts that are extracted by pytesseract model.
The psm mode is very important in extraction. psm stands for “page segmentation mode” how to scan an image to extract text is done by psm mode. If you want to read more on psm then go through the below blog.
Tesseract Page Segmentation Modes (PSMs) Explained: How to Improve Your OCR Accuracy …
Most introductions to Tesseract tutorials will provide you with instructions to install and configure Tesseract on your…
pyimagesearch.com
After using psm mode 8, we got the following output
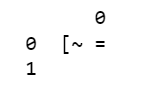
If you see this, then it is irrelevant and does not give any information from a text extraction perspective. Let's change psm mode to 4.

This output is better than psm 8. So we will take this mode to refine our text extraction model.
part2:Imroving performance
Many times there is a case where we get output from text extraction, but it is somewhat distorted than the original word.
Ex. the original word is KITCHEN, and the model is giving kitc, kitche, tchen, KITC, kitchen like any combination of words. So for this possibility, we will use one technique with one library.
the library difflib is used to calculate the difference between the original and the predicted word. Working on the difflib is very simple. You have to provide a tentative dictionary of words that may come into your images for extraction. Then this library asks for the threshold to match. Any possibility which is matching with our words in the dictionary with the given threshold will get replaced with the original word from the dictionary.
for i in text:
new_dict.append(i)
new = []
for i in text[0]:
new.append(i)
importing and working with Difflib
import difflib
#close_matches = []
possibilities = ["Drawing","Bedroom", "Hall", "Kitchen", "Balcony", "Dining","Sitout","SITOUT","HALL","KITCHEN","BEDROOM","HALL","LOBBY","TOILET"]
n = 3
cutoff = 0.3
emptyDict = {}
for w in new:
if (difflib.get_close_matches(w, possibilities, n, cutoff)):
#print (w)
i = new.index(w)
emptyDict[w] = new[i+1]
else:
continue
If you use the above code and print emptydict then the following is the output.
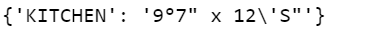
It is much more accurate and usable than the output that we previously had without any preprocessing.
What if we want a specific special character and want to eliminate any other present in extraction?
We have a solution for that. A RegEx, or Regular Expression, is a library that we can use to solve this problem.
Final_df = pd.concat(Finaldf, ignore_index=True)
Final_df = Final_df.replace('=', '', regex=True)
Final_df = Final_df.replace('x', '', regex=True)
Final_df = Final_df.replace('X', '', regex=True)
Final_df = Final_df.replace('{', '', regex=True)
Final_df = Final_df.replace('\', '', regex=True)
Final_df = Final_df.replace('°', '', regex=True)
After concatenating every extraction in one dataframe, we can use the above code to replace desired signs.
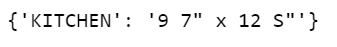
Better than the previous one!!
The better option for such cases is to change the library and go for higher-level libraries like EasyOCR, Google vision, etc. but these small changes can be useful when we are doing any kind of text extraction.
Above mentioned technique you can use when you are sure about data keywords that we want to extract, and you can update your dictionary of mapping at any stage for new words.
Other ways to improve the accuracy of the model:
1) Select only that language which are present in your source document
This reduces wrong interpretations of characters and patterns and helps to reduce noise. Like in Tesseract, you can select a language package.
2) Text rotations
Most OCR engines work well with horizontal and vertical alignment. It gets harder when there is skewness or angled rotation in the text. Some OCR engines have PSM (page segmentation mode), where we can select the orientation of scanning.
3) Lighting of image
Brightness and contrast are the two things that enhance the readability and explicitness of features for text extraction. there are many apps that can help to adjust the contrast and brightness of an image. The proper lighting condition can improve the results of OCR.
4) Image extension
Compressions, resizing, and other image manipulations tend to lose image information. .JPG format tends to lose more data after such operations where. PNG and . TIFF doesn’t lose data to such an extent. Choosing image format wisely can improve OCR’s efficiency. Below mentioned python code can be useful to convert images into desired DPI.
from PIL import Image
img = Image.open("IMAGE.png")
img.save("Converted_IMAGE-600.png", dpi=(300,300))
5) Image quality
Dots per inch or DPI is the main factor when considering the quality of the image. A resolution of less than 300 DPI can make the image unclear. There are many DPI conversion tools online that can get you the required DPI. So try to use a higher DPI image.
For more understanding of concepts like DPI, Resolution, PNG, JPG & other image formats, PPI, Lossless formats, etc.
U+007C Useful materials U+007C
- I found one pretty good series to understand OCR by Python Tutorials for Digital Humanities . This is a link for the video series on OCR.
- One interesting GitHub account I found was of Kba for OCR. Here is the link: kba /awesome OCR . You will get to know many things as well as interesting projects with source code from this account.
- I found one excellent book “OCR with Tesseract, OpenCV, and Python” by Dr.Adrian Rosebrock .link for the book: Book link
So these are all things that can help you to solve your text extraction-related problem statements at basic levels.
4. A project for “OCR models reading Captchas” you can refer to this video.
If you have found this article insightful

Give article claps if you liked this article!
If you found this article insightful, follow me on Linkedin and medium. you can also subscribe to get notified when I publish articles. Let’s create a community! Thanks for your support!
You can read my other blogs related to :
YOLO v8! The real state-of-the-art?
My experience & experiment related to YOLO v8
medium.com
Comprehensive Guide: Top Computer Vision Resources All in One Blog
Save this blog for comprehensive resources for computer vision
medium.com
Feature selection techniques for data
Heuristic and Evolutionary feature selection techniques
medium.com
Genetic Algorithm Optimization
A detailed explanation of the evolutionary and nature-inspired optimization algorithm
pub.towardsai.net
Signing off,
Chinmay
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


