



Image segmentation of rotating iPhone with scikit-image
Last Updated on January 7, 2023 by Editorial Team
Last Updated on August 23, 2022 by Editorial Team
Author(s): Dmitri Azarnyh
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Image Segmentation of Rotating iPhone With Scikit-image
Modern devices are full of different sensors: front and back cameras, accelerometers, gyroscopes, magnetometers, GPS, etc. Smart use of these devices allows for a large number of interesting applications such as compass, location detection, and games.
One such application is to detect the orientation of an iPhone in space which can be accomplished with data from the accelerometer and gyroscope. In the previous blog post, I wrote about the detection of iPhone orientation around one axis with data from two sensors of iPhone: gyroscope and accelerometer. The reconstruction of iPhone orientation was compared with the video. The results of the orientation reconstructed with sensors were a good qualitative match with the orientation depicted in the video:
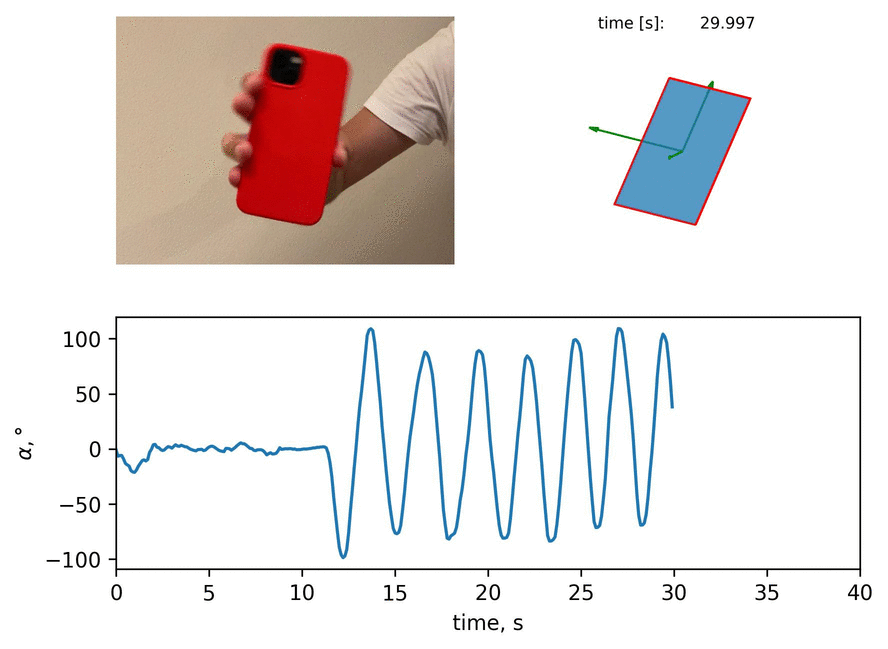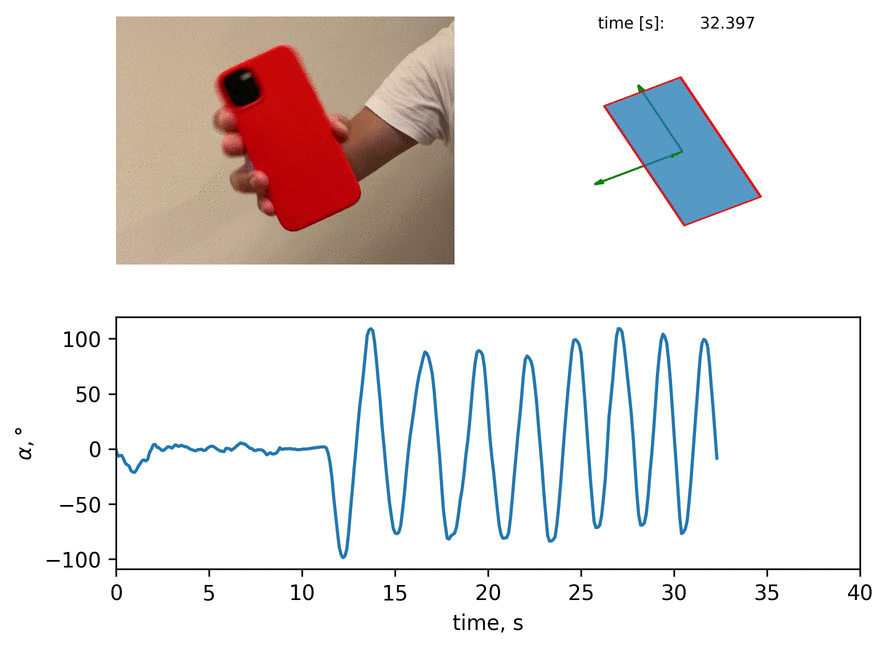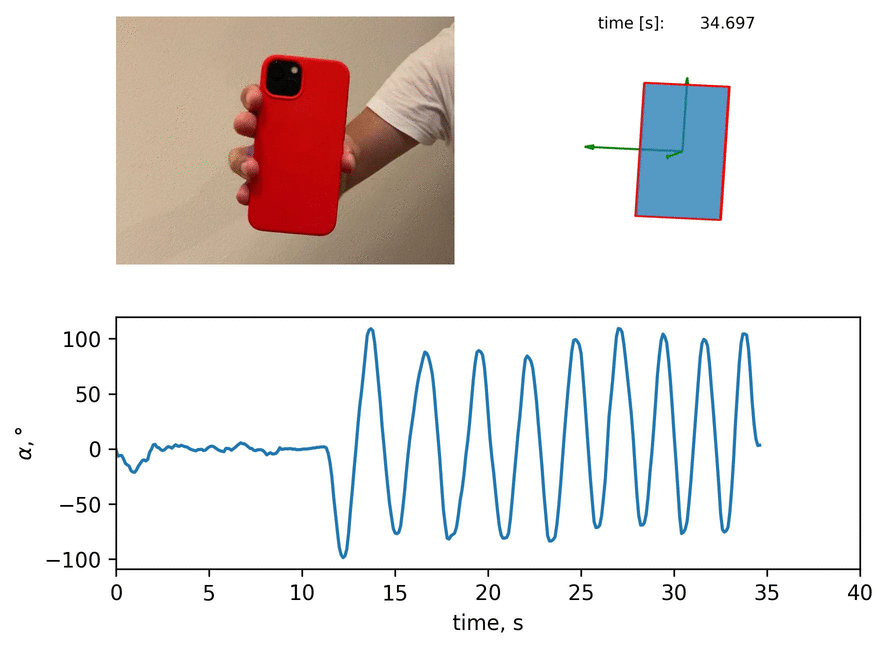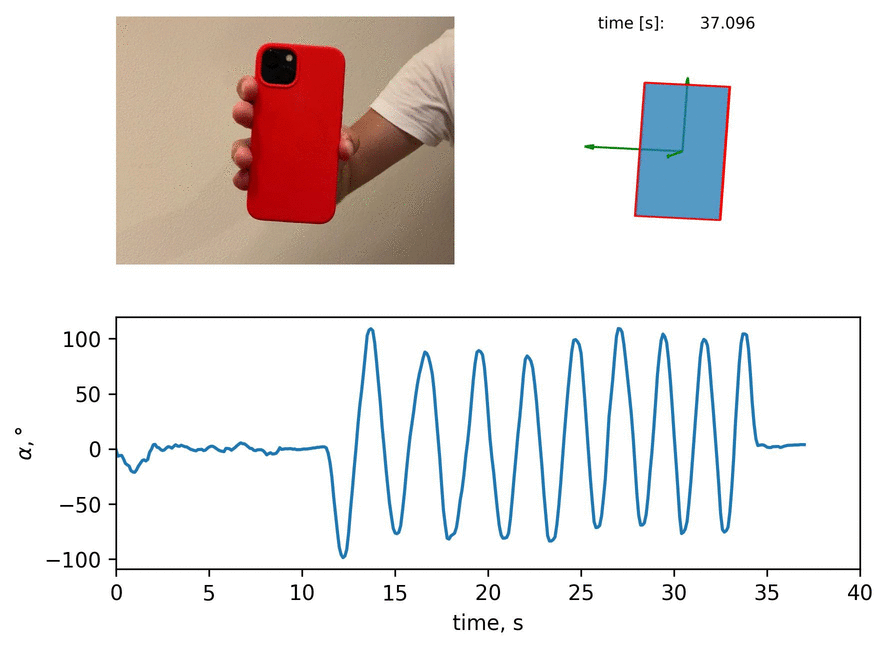
In this blog post, I present the way to extract the angle of iPhone inclination from the video with image segmentation. Then, I show the comparison of an error between two ways of measurement. Let me guide you through.
Video preparation
Before starting with the segmentation, there are a few things to prepare. My video was recorded with an iPhone and had a variate frame rate. To synchronize video clocks with sensor clocks, a constant frame rate is preferable. So, the first step would be to transfer the video to a constant frame rate. The next step would be to split the video into images where each frame corresponds to a jpeg image. The whole dataset of images can be found here.
Deep learning approach with Mask-R-CNN
When we talk about the segmentation of an image, it’s a great temptation to try some cool deep learning algorithm and hope that it will work. Following this temptation, I tried pre-trained Mask-RCNN. Fortunately, a cell phone is one of the classes the original model was trained on. The first result was quite impressive, as shown in the picture below:
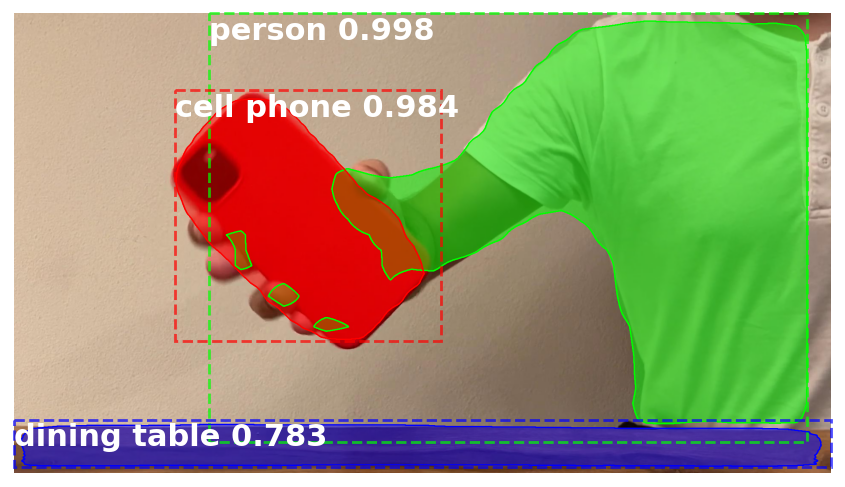
However, with a closer investigation, it appears that some images of the iPhone were misidentified (see the picture below):
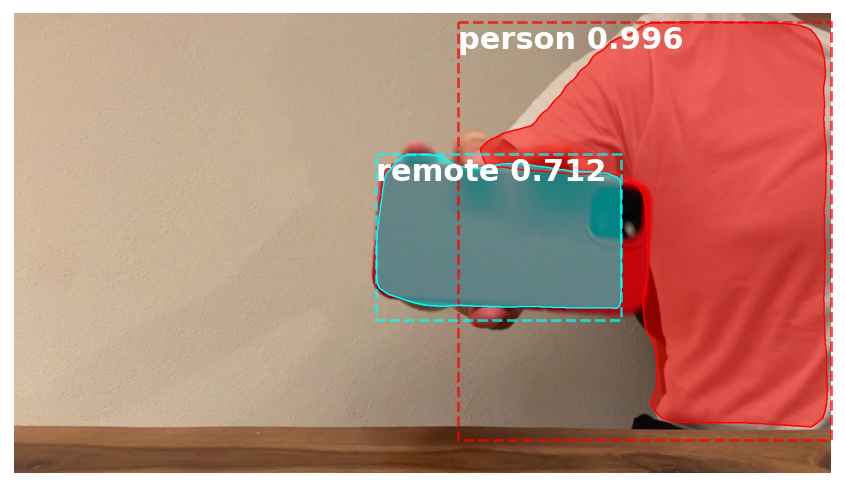
Like in many real-life data science projects, the results of the deep learning model are surprisingly good but do not fully deliver what is expected. At least not for the whole dataset. One option to overcome this challenge would be to label the data and fine-tune the original model. However, given the fact that it’s a red iPhone on an almost white background, there should be some easier ways. Let us have a look at them.
Classical CV approach with RGB image
To segment an image, we first try using a 3-channel RGB representation of an image that is short from red, green, and blue. Red would correspond to the first number that is very high, while the second and the third numbers are expected to be low, somewhat like (255,0,0). In this case, we can just choose all red pixels and hope that it will be the iPhone. To capture more shadows of red, I tried to filter all pixels which have a color value for the first channel (red) bigger than 130. For the second and the third channels, I filter the pixels which are lower than 60. Here is the code.
Such an approach produces reasonably good results:
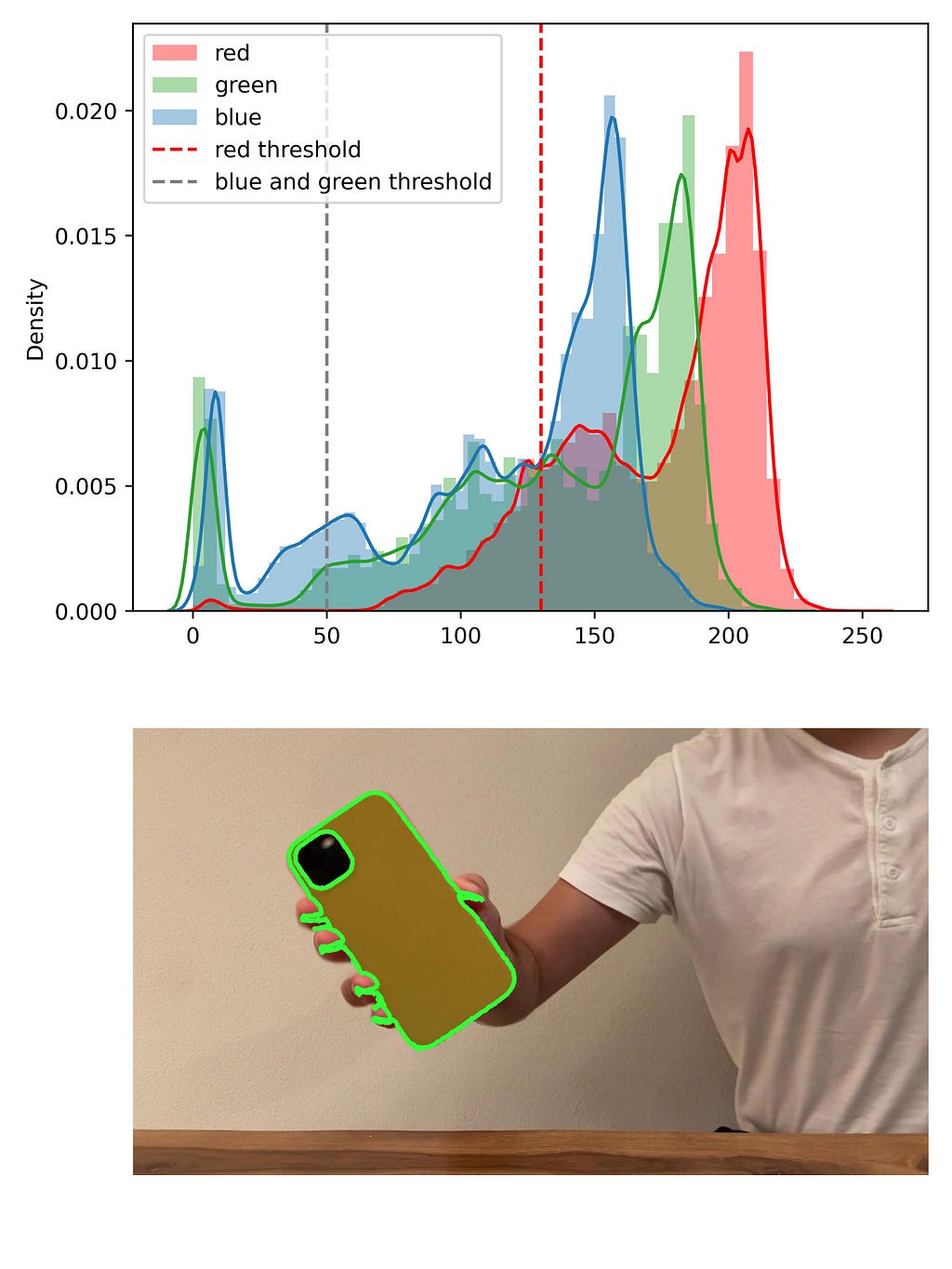
There is also a camera “hole” in the iPhone, which is black and was hence not segmented. We can fill out this hole with scikit-image tools:
One has to set up the area of the holes to fill out and small objects to filter out. I choose 40000 as the area. Now the segmentation does include the cameras of the iPhone:

So, the segmentation based on red color in RGB representation works well on one image. However, after running this threshold-based algorithm through all images, I found that there are some segmentation inaccuracies:

These inaccuracies could be fixed by manipulating thresholds on red, green, and blue colors. However, if we relax the parameters, the mask starts to capture brown color:

It’s still possible to play around with thresholds in RGB. However, there are at least three parameters to tune (thresholds in red, green, and blue). Much easier would be to reduce it to only one tunable parameter. For that purpose, we can consider the iPhone image in a different color representation.
Classical CV approach with HED image
In the scikit-image library, several transformations are available from the RGB to different color representations. One of the challenges which I experience in working with the images of rotating iPhones is the separation from dark red and brown. This color separation is well addressed in the Haematoxylin-Eosin-DAB (HED) color space, where Hematoxylin has a deep blue-purple, Eosin is pinkish, and DAB is brown. Red iPhone is quite well detected with Eosin channel of such a color representation, which fixes the issue of mixing it up with brown, as brown is presented as DAB. In the HED representation, we have only one threshold in the Eosin channel to tune. The mask for the images which are challenging for RGB is captured correctly based on the Eosin channel and threshold of 0.05.

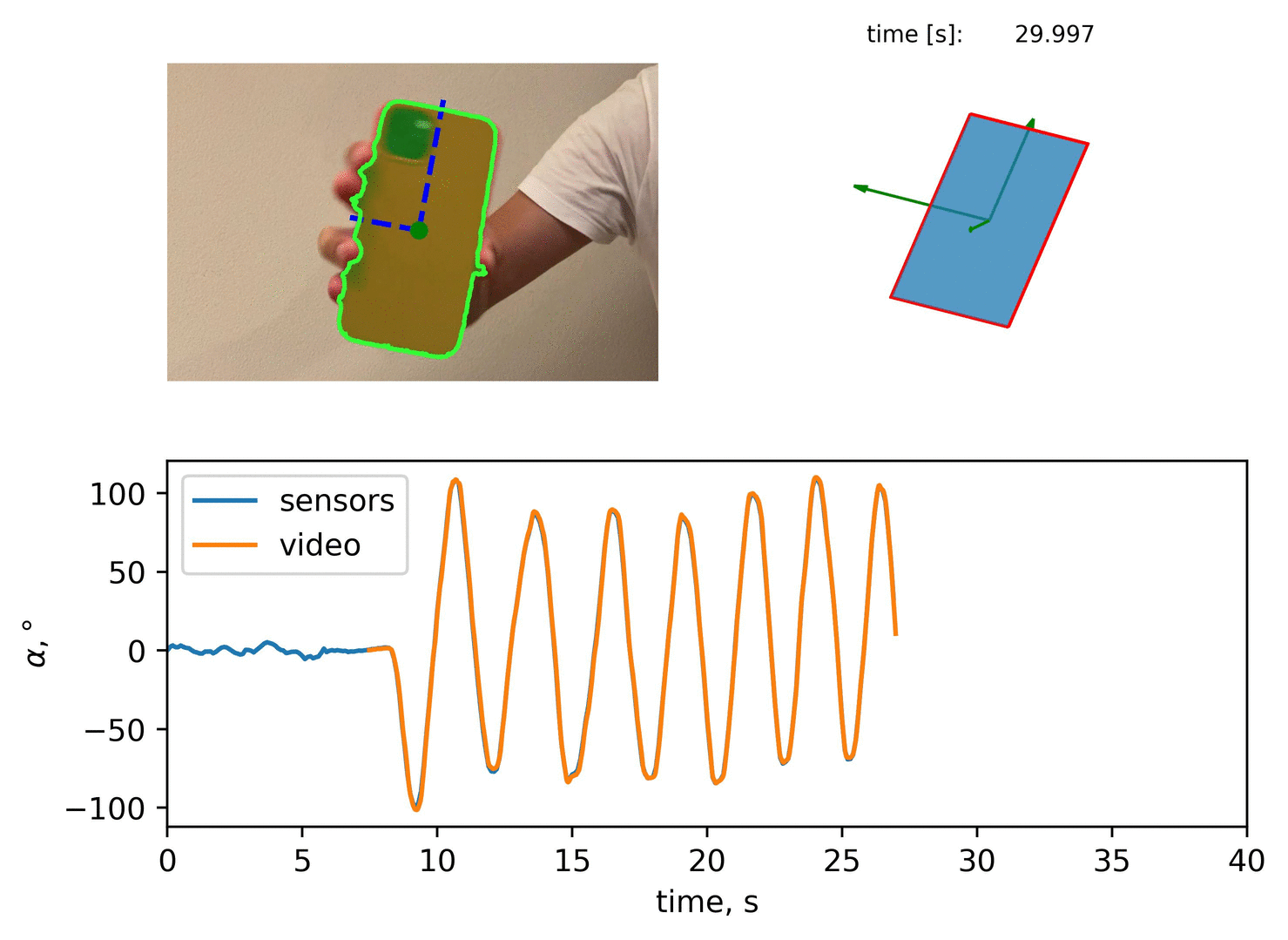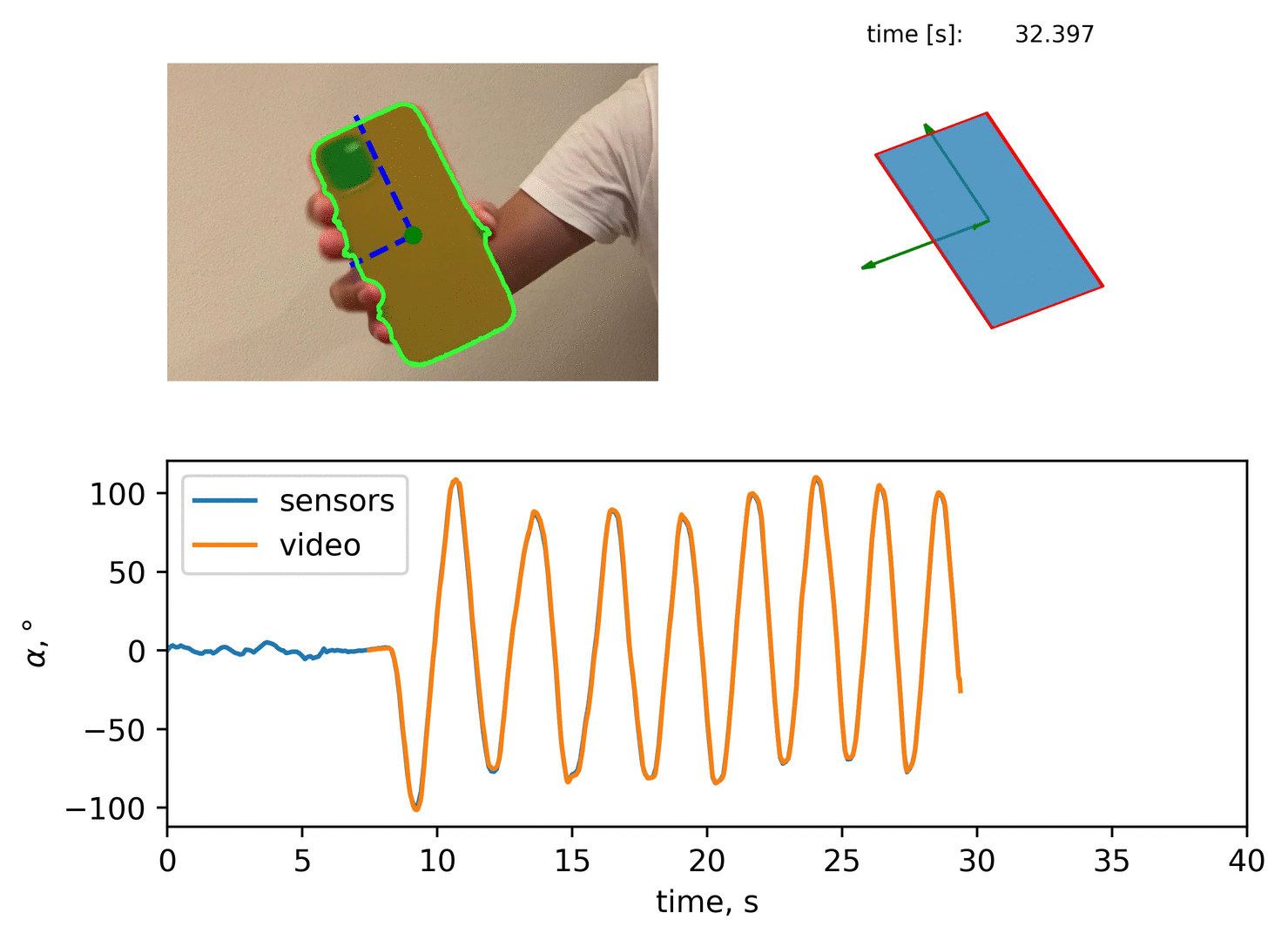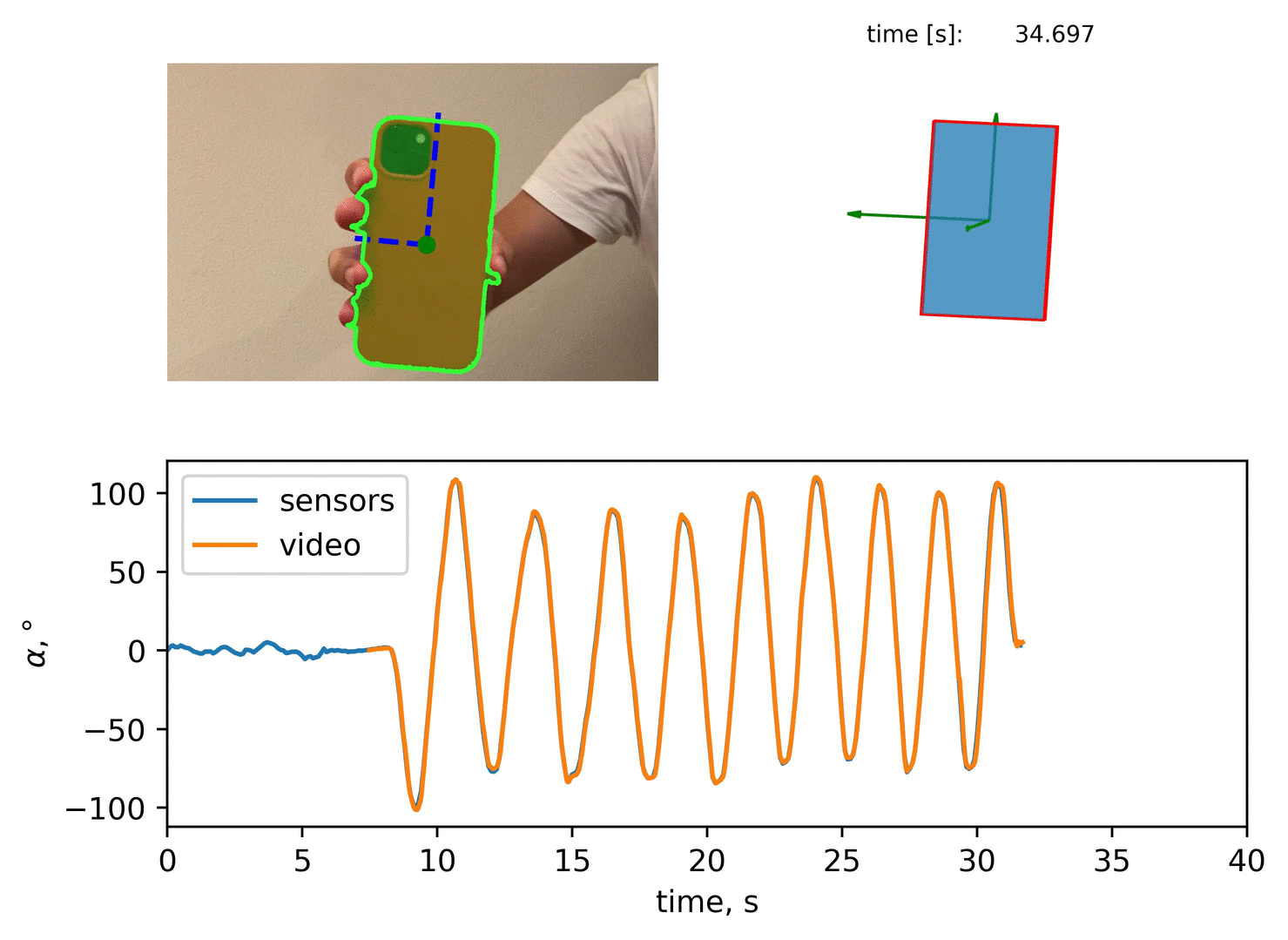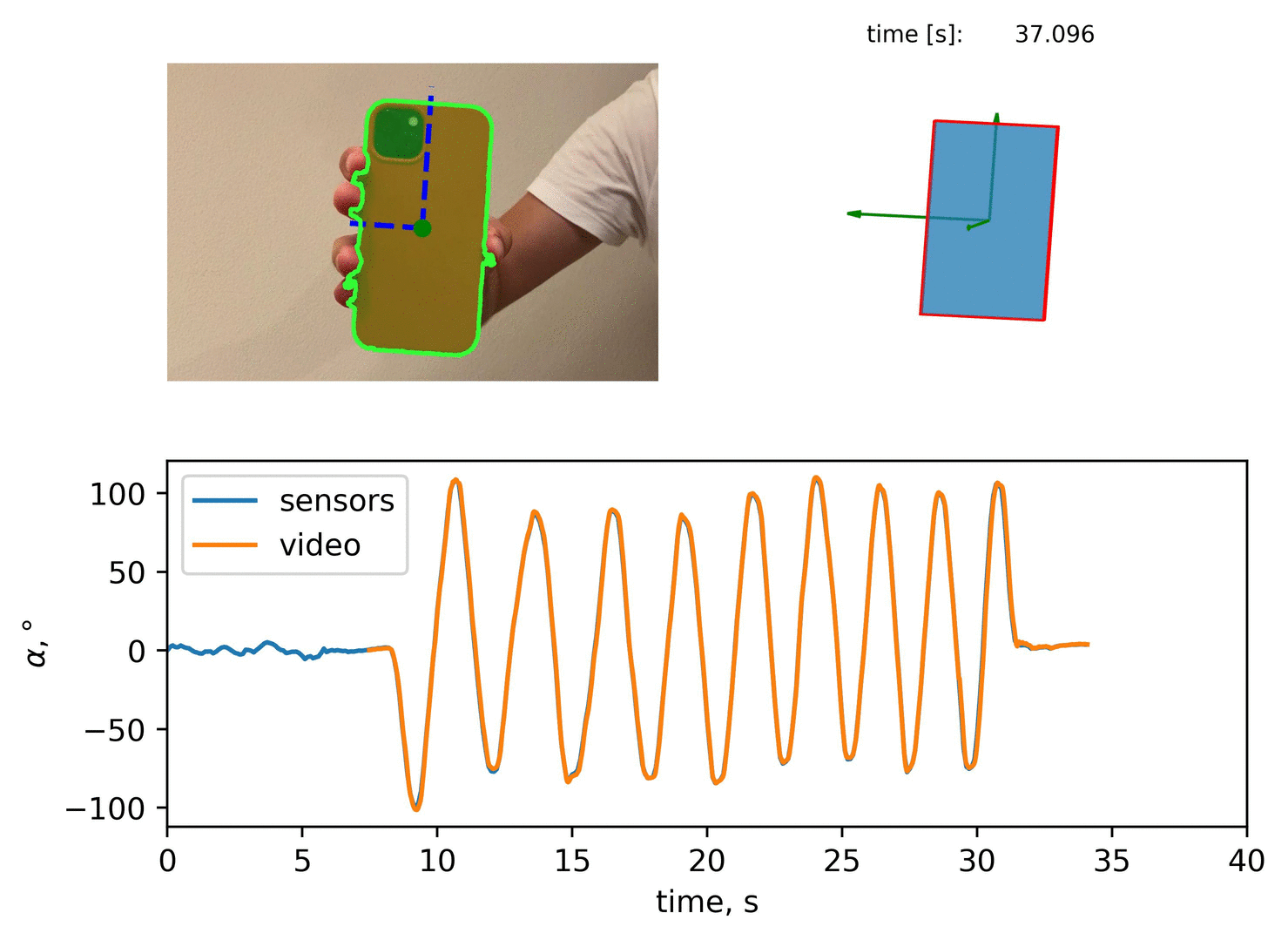
Scikit-image also provides tools to measure the properties of the segmented region. Among other properties, it’s possible to measure the orientation of the iPhone:
The full segmentation algorithm would result to:
A qualitative comparison would result to:
Quantitative Comparison
Now it’s possible to compare the inclination angle, which is derived from segmentation, with the one derived from sensors data. It gives a good match:
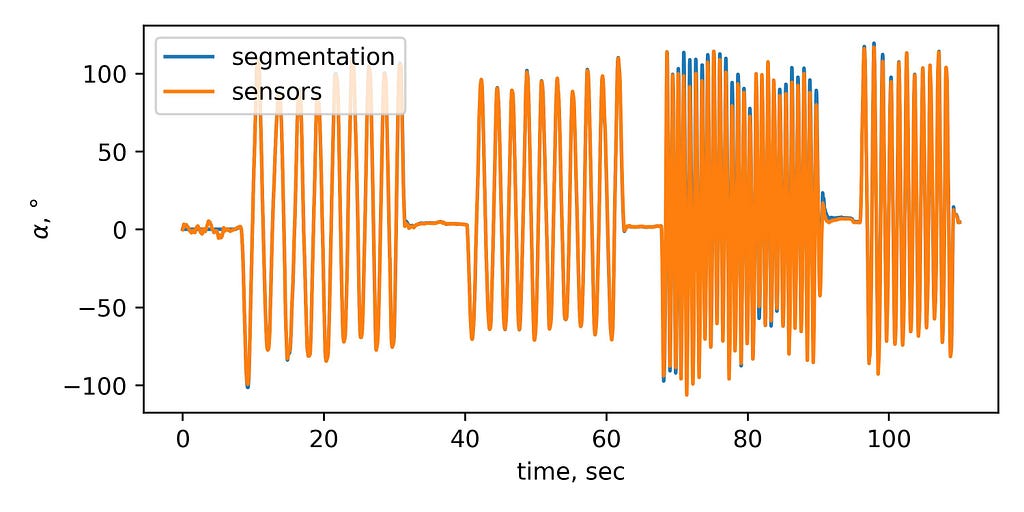
The absolute error between sensors and interpolated values of video are:
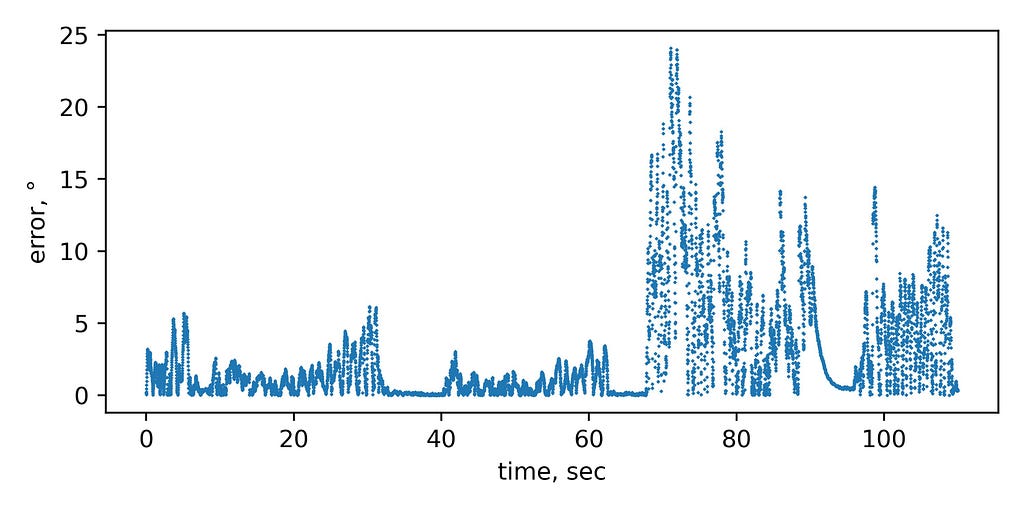
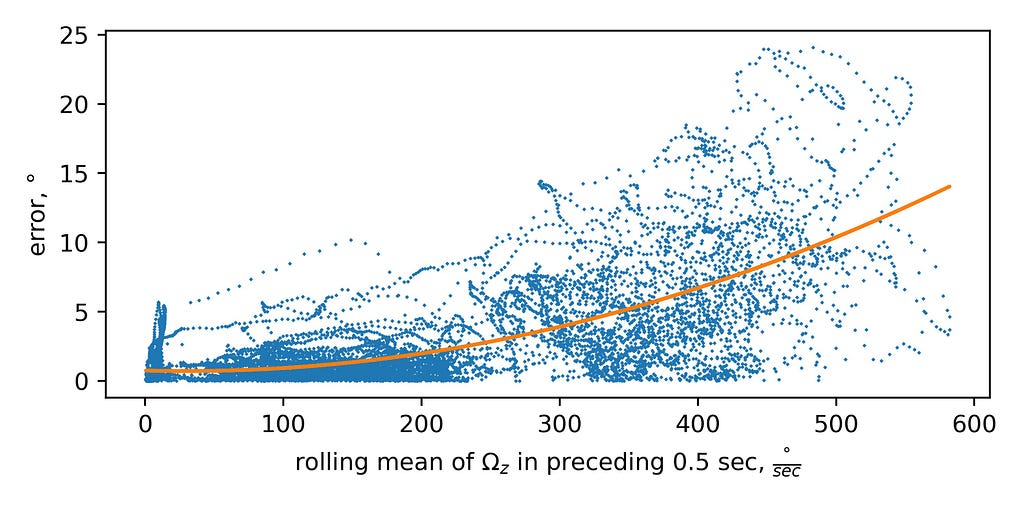
We can see that faster rotation results in higher errors between the two methods. That is also seen on the plot of the rolling mean of the rotational speed of preceding 0.5 sec versus the error:
P.S.: I want to thank my wife Katya and Vladyslav Rosov for helping with the post.
Image segmentation of rotating iPhone with scikit-image was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

