



How To Use TPUs in Kaggle / Google Colab To Train a GAN in the Blink of An Eye.
Last Updated on March 30, 2023 by Editorial Team
Author(s): Pere Martra
Originally published on Towards AI.
Looking to speed up your GAN training? In this article, I’ll show you how to utilize TPUs in Kaggle or Google Colab to drastically reduce training time, allowing you to generate high-quality images in a blink of an eye. Follow this step-by-step guide and take your GANs to the next level!
This is the third article in the GAN series, and we are going to take a significant step forward in the complexity of our GAN. In previous articles, we’ve made two simple GANs with simple Datasets.
Creating our first optimized DCGAN
The following article is the first in a series that will discuss generative adversarial networks. Let’s get started…
pub.towardsai.net
How to make a GAN to generate color images.
In this article, we continue our journey through the exciting world of GANs and learn how Generative AI works with a…
pub.towardsai.net
For the purposes of this article, we will use a much more complicated dataset with larger full-color images. The dataset contains 200,000 images of the faces of famous people.
The GAN will try to generate realistic-looking faces that could pass for real people. Although I have restricted the size of the images to 80 × 80, the work of training the GAN can be very heavy, so on a GPU, it could well take a couple of hours or more. A good method to accelerate the process is to use TPUs instead of GPUs, a more powerful processor available in some clouds like Google Colab or Kaggle.
To know more about TPUs: https://codelabs.developers.google.com/codelabs/keras-flowers-data/#2
I am not going to explain what a TPU is or how it works. It is enough to know that it is a much faster processor than a GPU for Deep Learning tasks. It is not necessary to go into more detail.
Taking advantage of the fact that we work with a Face Dataset, we are going to explore the possibility of using the MTCNN face detection library to select only the part of the image that contains the face.
The code is available at Kaggle, Google Colab and GitHub:
https://www.kaggle.com/code/peremartramanonellas/gan-tutorial-3-how-to-use-tpus-to-train-a-gan
https://github.com/oopere/GANs/blob/main/C3_Faces_TPU.ipynb
https://colab.research.google.com/drive/1p6sQqiu4kWeDpxu91C0MQBX9P6qSwmPG?usp=sharing
I highly recommend having the notebook open and running it as you progress through the article.
Activating the TPU.
To activate the use of TPUs for our notebook, we must do two things: select it in the Google Colab or Kaggle menu and retrieve the instance of the TPU.
In Kaggle, the option to change the accelerator is on the right menu:
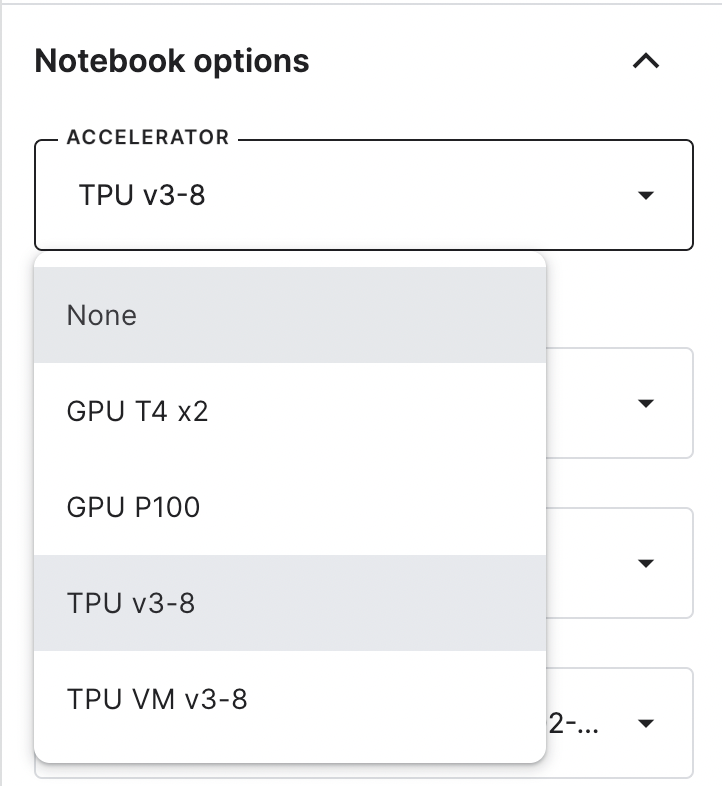
Once we have chosen the environment, we must instantiate the TPU:
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
except ValueError:
raise BaseException("CAN'T CONNECT TO A TPU")
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.TPUStrategy(tpu)
This code aims to establish an execution strategy. The first thing is to connect to a TPU. Once connected, we create the strategy with tf.distribute.TPUStrategy.
Indicating that we are going to execute the code in a distributed way. So, the Dataset will have to be divided between different machines, just like our code that will be running in parallel.
Load and prepare the Dataset.
The Dataset we will use is the CelebA Dataset. It is made up of about 200,000 images of celebrities. I’m going to download it from a repository on Google, but there are many sources where it is available.
It can be found at:
- Google directory: https://storage.googleapis.com/learning-datasets/Resources/archive.zip
- Kaggle: https://www.kaggle.com/datasets/jessicali9530/celeba-dataset
- Mmlab: https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
- TensorFlow: https://www.tensorflow.org/datasets/catalog/celeb_a?hl=es-419
# make a data directory
try:
os.mkdir('/tmp/celeb')
except OSError:
pass
# download the dataset archive
data_url = "https://storage.googleapis.com/learning-datasets/Resources/archive.zip"
data_file_name = "archive.zip"
download_dir = '/tmp/celeb/'
urllib.request.urlretrieve(data_url, data_file_name)
# extract the zipped file
zip_ref = zipfile.ZipFile(data_file_name, 'r')
zip_ref.extractall(download_dir)
zip_ref.close()
The first thing we do is to create the directory. If the directory already exists and there is an error, we ignore it. After that, we download the file containing the images from the Google directory and unzip it.
With this, the images will be unzipped into the directory /tmp/celeb/img_align_celeba/img_align_celeba.
Now we’ll need a function that loads the images and transforms them. That is, give them all the same size and normalize the value of their pixels to values between -1 and 1, as indicated in the GAN Hacks.
To accomplish this, I have prepared two functions. One of them uses a library to locate where the face is within the image, while the other just cut out the central part of the image, which is where the face usually is. In both cases, the output size of the image is the same.
In the two functions, you can specify the maximum number of images to use. I recommend that you use about 1000 images for testing. It is enough to obtain good results.
#Function to load the faces.
#Crop & center the images because the faces is almost always in the center.
def load_faces(image_paths, resize, max_images):
crop_size = 128
if (max_images == 0):
max_images = len(image_paths)
print(max_images)
images = np.zeros((max_images, resize, resize, 3), np.uint8)
for i, path in tqdm(enumerate(image_paths)):
with Image.open(path) as img:
left = (img.size[0] - crop_size) // 2
top = (img.size[1] - crop_size) // 2
right = left + crop_size
bottom = top + crop_size
img = img.crop((left, top, right, bottom))
img = img.resize((resize, resize), Image.LANCZOS)
images[i] = np.asarray(img, np.uint8)
if (i >= max_images-1):
break
return images
This function above goes through all the images in the directory and cuts the area in the center, which is where the face often is, so that all the images have the same size. Then adjust the size of the image to the value indicated in the resize parameter.
It returns all the images cropped and adjusted to the same size.
In the notebook, you can find a second function, which instead of centering the crop, uses the MTCNN library to locate the face:
#Funtion to load the faces. Use the MTCNN lybrary to detect where the face is.
def load_faces_MTCNN(image_paths, resize, max_images):
MTCNN_model = mtcnn.MTCNN()
if (max_images == 0):
max_images = len(image_paths)
print(max_images)
images = np.zeros((max_images, resize, resize, 3), np.uint8)
for i, path in enumerate(image_paths):
with Image.open(path) as img:
img = img.convert('RGB')
#img_pixels = np.asarray(img)
face = MTCNN_model.detect_faces(img_pixels)
if len(face) == 0:
#just in case MTCNN can't find a face
continue
x1, y1, width, height = face[0]['box']
x1, y1 = abs(x1), abs(y1)
x2, y2 = x1 + width, y1 + height
img = img.crop((x1, y1, x2, y2))
img = img.resize((resize, resize), Image.LANCZOS)
images[i] = np.asarray(img, np.uint8)
if (i >= max_images-1):
break
return images
The detect_faces function returns the coordinates where it finds the face. Cropping is done using those coordinates, and then, as in the previous function, the images are resized.
Both functions share inputs and outputs, so we can use either of them. In the case that we use face detection, it penalizes the time necessary to process the images, but it results in a better-trained GAN.
The images returned by either of these two functions still have to normalize the value of their pixels and put them inside a dataset that can be used to be treated in a distributed strategy.
To normalize the pixels, we have this function:
def preprocess(img):
x = tf.cast(img, tf.float32) / 127.5 - 1.0
return x
This function will be called at the time of preparing the data set.
dataset = tf.data.Dataset.from_tensor_slices((images1, images2))
dataset = dataset.map(
lambda x1, x2: (preprocess(x1), preprocess(x2))
).shuffle(4096).batch(batch_size, drop_remainder=True).prefetch(tf.data.experimental.AUTOTUNE)
return dataset
When preparing the Dataset, we pass two sets of images, and through the lambda function, the preprocess function is called to normalize the pixels of the images.
All of this occurs within a function:
#Load the pictures in the dataset. You can indicate the max_images. I recommend
#that for testing you use 1000 images, and when you want to see the result final
#use the max number of images, indicating 0 to max_images.
def load_celeba(batch_size, resize=80, max_images=0):
"""Creates batches of preprocessed images from the JPG files
Args:
batch_size - batch size
resize - size in pixels to resize the images
crop_size - size to crop from the image
Returns:
prepared dataset
"""
# initialize zero-filled array equal to the size of the dataset
image_paths = sorted(glob.glob("/tmp/celeb/img_align_celeba/img_align_celeba/*.jpg"))
print("Creating Images")
# crop and resize the raw images then put into the array
#choose wich function you want to use.
images = load_faces(image_paths, resize, max_images)
#images = load_faces_MTCNN(image_paths, resize, max_images)
#Plot the 5 first images.
plot_results(images[0:5], unnorm=False)
# split the images array into two
split_n = images.shape[0] // 2
images1, images2 = images[:split_n], images[split_n:2 * split_n]
del images
# preprocessing function to convert the pixel values into the range [-1,1]
#Is a GAN Hack to normalize the pixels of the images
def preprocess(img):
x = tf.cast(img, tf.float32) / 127.5 - 1.0
return x
# use the preprocessing function on the arrays and create batches
dataset = tf.data.Dataset.from_tensor_slices((images1, images2))
dataset = dataset.map(
lambda x1, x2: (preprocess(x1), preprocess(x2))
).shuffle(4096).batch(batch_size, drop_remainder=True).prefetch(tf.data.experimental.AUTOTUNE)
return dataset
As you can see, the function responsible for loading the Dataset that we call does not use the MTCNN face detection library. However, it is possible to change the load_faces function call to a load_faces_MTCNN call.
We can adjust the maximum number of images that will load without effort, although I recommend a minimum of 1000. In case we want to use all the images in the dataset, we only have to give a value of 0 to the variable max_images.
When preparing the dataset, each of the images is passed through the preprocess function, which is dedicated to normalizing the pixel values to values between -1 and 1.
The dataset is made on the line:
dataset = tf.data.Dataset.from_tensor_slices((images1, images2))
dataset = dataset.map(
lambda x1, x2: (preprocess(x1), preprocess(x2))
).shuffle(4096).batch(batch_size, drop_remainder=True).prefetch(tf.data.experimental.AUTOTUNE)
As you can see, within dataset.map the images are preprocessed using the lambda function. The images are shuffled, and a prefetch is made so that they can be loaded into memory, which makes the learning process faster.
Let’s see the call to the function to create the dataset:
# use the function above to load and prepare the dataset
#Note how the batch_size is multiplied by strategy.num_replicas_in_sync
batch_size = 8
batch_size = batch_size * strategy.num_replicas_in_sync
dataset = load_celeba(batch_size, max_images=1000)
We multiply the batch_size by the number of replicas that our execution strategy will have. The batch_size is just passed to datasep.map to indicate the size of the batch.
This call was made during one of the tests to train the GAN, and I only used 1000 images. To see the final result, it is best to indicate 0 in max_images and thus use all the images available in the Dataset.

Create the Generator and Discriminator.
For a more detailed explanation of how the GAN Generator and Discriminator work, I recommend reading the first article in the series dedicated to GANs: How to create a GAN for the MNIST Dataset.
A GAN is composed of two models, the Generator and the Discriminator. The Generator creates images starting with random data, which can be called noise. It transforms this noise through its layers until it gets an image of the format indicated.
The discriminator tries to figure out if an image belongs to the original Dataset, that is, if it is a true image or if it is an image made by the Generator.
The Generator model.
def adapt_generator(initial_0, nodes, upsamplings, multnodes = 1.0, endnodes = 3, input_noise=100):
#initial_0 : size of the initial mini image.
#nodes: nodes in the first Dense layers.
#upsamplings: number of upsamplings bucles.
#multnodes: a multiplicator to modify the nodes in each upsampling bucle.
#endnodes: nodes of the last layer. 1 for gray scale images, 3 for color images.
#input_noise: size of the noise.
model = keras.models.Sequential()
#First Dense layer.
model.add(keras.Input(shape=(1, 1, 128)))
nodeslayers = nodes
model.add(keras.layers.Conv2DTranspose(nodeslayers , kernel_size=initial_0, strides=1, padding="valid", use_bias=False))
#Upsampling bucles.
for i in range(upsamplings-1):
nodeslayers = int(nodeslayers * multnodes)
model.add(keras.layers.Conv2DTranspose(nodeslayers , kernel_size=4, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(alpha=0.2)))
model.add(keras.layers.BatchNormalization())
#last upsample and last layer.
model.add(keras.layers.Conv2DTranspose(endnodes, kernel_size=4, strides=2, padding="SAME",
activation='tanh'))
return model
The adapt_generator function allows us to indicate the characteristics that the GAN Generator must have through its parameters. We already saw this function in the second article of the GANs tutorial: Create a GAN that generates color images.
The Generator we want should create 80 x 80 x 3 images. As input, we will receive the randomly generated noise. We must achieve the desired image format from this noise by performing upsampling.
In our model, this upsampling are done with Conv2DTranspose layers with a stride of 2, which means that the image doubles its length and width with each upsample. For example, we could start with an image of 10 and do two upsampling, or from an image of 5, and do four upsampling. I have opted for the second option.
Some GAN Hacks are used in the generator to optimize it.
- Use of a BatchNormalization layer after each Upsample.
- Using the LeakyReLU activator with an alpha of 0.2.
- Using the tanh activator on the last layer of the model.
To create the generator, I used the following call:
model_G = adapt_generator(5, nodes=128, upsamplings=4, multnodes=1, endnodes=3, input_noise=100)
That provides us with a generator:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_transpose (Conv2DTra (None, 5, 5, 128) 409600
nspose)
conv2d_transpose_1 (Conv2DT (None, 10, 10, 128) 262272
ranspose)
batch_normalization (BatchN (None, 10, 10, 128) 512
ormalization)
conv2d_transpose_2 (Conv2DT (None, 20, 20, 128) 262272
ranspose)
batch_normalization_1 (Batc (None, 20, 20, 128) 512
hNormalization)
conv2d_transpose_3 (Conv2DT (None, 40, 40, 128) 262272
ranspose)
batch_normalization_2 (Batc (None, 40, 40, 128) 512
hNormalization)
conv2d_transpose_4 (Conv2DT (None, 80, 80, 3) 6147
ranspose)
=================================================================
Total params: 1,204,099
Trainable params: 1,203,331
Non-trainable params: 768
As you can see, we are evolving from the initial 5 x 5 to the necessary 80 x 80. I keep the number of nodes stable in all layers, but we could have indicated more nodes for the first layer and reduced them as we went along.
In order to achieve the reduction, we would only have to indicate a value less than 1 in the multnode parameter. As a sample, we can use the value 0.5 to halve the number of nodes in each upsampling.
Create the GAN Discriminator.
def adapt_discriminator(nodes, downsamples, multnodes = 1.0, in_shape=[32, 32, 3]):
#nodes: nodes in the first Dense layers.
#downsamples: number of downsamples bucles.
#multnodes: a multiplicator to modify the nodes in each downsample bucle.
#in_shape: Shape of the input image.
model = keras.models.Sequential()
#input layer % first downsample
model.add(keras.layers.Conv2D(nodes, kernel_size=5, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2),
input_shape=in_shape))
model.add(keras.layers.Dropout(0.4))
#creating downsamples
nodeslayers = nodes
for i in range(downsamples - 1):
nodeslayers = int(nodeslayers * multnodes)
model.add(keras.layers.Conv2D(nodeslayers, kernel_size=3, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2)))
model.add(keras.layers.Dropout(0.4))
#ending model
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(1, activation="sigmoid"))
return model
To create the discriminator, we are also going to use a function that allows us to generate different discriminators that we have already used in the previous article.
The discriminator needs a first layer capable of receiving an image, in this case, 80 × 80 × 3. In the last layer, it will generate a binary output indicating whether the image is false or true.
The Discriminator also follows some recommendations published in the GAN Hacks:
- The use of Dropout layers.
- Use of the LeakyReLU activator.
The use of Dropout layers is very important; it prevents the discriminator from becoming smart too early, which could prevent the generator from starting to generate images capable of fooling it.
The call to create the discriminator is:
model_D = adapt_discriminator(128, 5, multnodes=1, in_shape=shape)
That produces the Discriminator:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 40, 40, 128) 9728
dropout (Dropout) (None, 40, 40, 128) 0
conv2d_1 (Conv2D) (None, 20, 20, 128) 147584
dropout_1 (Dropout) (None, 20, 20, 128) 0
conv2d_2 (Conv2D) (None, 10, 10, 128) 147584
dropout_2 (Dropout) (None, 10, 10, 128) 0
conv2d_3 (Conv2D) (None, 5, 5, 128) 147584
dropout_3 (Dropout) (None, 5, 5, 128) 0
conv2d_4 (Conv2D) (None, 3, 3, 128) 147584
dropout_4 (Dropout) (None, 3, 3, 128) 0
flatten (Flatten) (None, 1152) 0
dense (Dense) (None, 1) 1153
=================================================================
Total params: 601,217
Trainable params: 601,217
Non-trainable params: 0
Like in the Generator, the nodes are maintained between layers. It is common practice to increase them as the size of the image is reduced. If we wanted to do it, we just had to modify the value of the multnodes parameter.
Let’s examine the complete code for the creation of both models:
# Settings
resize = 80
shape = (resize, resize, 3)
# Build the GAN
with strategy.scope():
# create the generator model
model_G = adapt_generator(5, nodes=128, upsamplings=4, multnodes=1, endnodes=3, input_noise=100)
# create the discriminator model
model_D = adapt_discriminator(128, 5, multnodes=1, in_shape=shape)
# print summaries
model_G.summary()
model_D.summary()
# set optimizers
param_G = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)
param_D = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)
The first thing we do is tell TensorFlow that we are going to use the distributed strategy. Within that scope, we will create the model and also any necessary elements, such as optimizers.
Within the scope, we are calling the functions that create the Generator and Discriminator that we have seen before.
To finish, we created two activators. Attention, even if the activator is exactly the same, two different variables must be created, one for the generator and another for the discriminator. We cannot use the same variable for both models. If we do it, it will give us an error in TensorFlow 2.11 or higher, and in older versions, it will work, but surely the GAN will lose efficiency.
Train the GAN.
We are going to use a custom function train_on_batch. We need to consider that this function will be executed in parallel in different TPUs and that we will have to unite the values that it returns. If we do not take this feature into account, the function will be very similar to the one used in the two previous articles.
First, a section to train the discriminator:
# PHASE ONE - train the discriminator
with tf.GradientTape() as d_tape:
# create noise input
z = tf.random.normal(shape=(real_img.shape[0], 1, 1, z_dim))
# generate fake images
fake_img = model_G(z)
# feed the fake images to the discriminator
fake_out = model_D(fake_img)
# feed the real images to the discriminator
real_out = model_D(real_img)
# use the loss function to measure how well the discriminator
# labels fake or real images
d_fake_loss = loss_func(tf.zeros_like(fake_out), fake_out)
d_real_loss = loss_func(tf.ones_like(real_out), real_out)
# get the total loss
d_loss = (d_fake_loss + d_real_loss)
d_loss = tf.reduce_sum(d_loss) / (batch_size * 2)
# get the gradients
gradients = d_tape.gradient(d_loss, model_D.trainable_variables)
# update the weights of the discriminator
param_D.apply_gradients(zip(gradients, model_D.trainable_variables))
We see that we create a context with tf.GradientType, with this we indicate that all the operations carried out within the context are recorded and are used to calculate the gradients of an output variable, in our case d_loss. That is, the loss of the discriminator.
Which we retrieve on the line:
# get the gradients
gradients = d_tape.gradient(d_loss, model_D.trainable_variables)
This will help us to be able to update the weights of the discriminator when applying the gradients later:
# update the weights of the discriminator
param_D.apply_gradients(zip(gradients, model_D.trainable_variables))
As a first step, within the context, the noise is created, and we call the Generator with this noise, which will be responsible for producing images from the noise.
# create noise input
z = tf.random.normal(shape=(real_img.shape[0], 1, 1, z_dim))
# generate fake images
fake_img = model_G(z)
These images are passed to the discriminator along with actual images from the Dataset, and the Loss function is used to measure how well it identifies the images.
# feed the fake images to the discriminator
fake_out = model_D(fake_img)
# feed the real images to the discriminator
real_out = model_D(real_img)
# use the loss function to measure how well the discriminator
# labels fake or real images
d_fake_loss = loss_func(tf.zeros_like(fake_out), fake_out)
d_real_loss = loss_func(tf.ones_like(real_out), real_out)
# get the total loss
d_loss = (d_fake_loss + d_real_loss)
d_loss = tf.reduce_sum(d_loss) / (batch_size * 2)
The calculated d_loss is one that we will use to calculate the gradients used to modify the weights of the discriminator and train it.
In the second block of the function, we go on to train the Generator:
# PHASE TWO - train the generator
with tf.GradientTape() as g_tape:
# create noise input
z = tf.random.normal(shape=(real_img.shape[0], 1, 1, z_dim))
# generate fake images
fake_img = model_G(z)
# feed fake images to the discriminator
fake_out = model_D(fake_img)
# use loss function to measure how well the generator
# is able to trick the discriminator (i.e. model_D should output 1's)
g_loss = loss_func(tf.ones_like(fake_out), fake_out)
g_loss = tf.reduce_sum(g_loss) / (batch_size * 2)
# get the gradients
gradients = g_tape.gradient(g_loss, model_G.trainable_variables)
# update the weights of the generator
param_G.apply_gradients(zip(gradients, model_G.trainable_variables))
As you can see, the operation is very similar to the section where the discriminator is trained. We also run it within a context that allows us to compute the gradients used to modify the Generator weights.
First, some images are generated using noise, and we pass them to the Discriminator. But this time with a true image label, that is, as if they were images belonging to the Dataset.
We then calculate the loss, with which we then calculate the gradients, and with them, we update the weight of the model.
Now let’s see the complete code:
@distributed(Reduction.SUM, Reduction.SUM, Reduction.CONCAT)
def train_on_batch(real_img1, real_img2):
'''trains the GAN on a given batch'''
# concatenate the real image inputs
real_img = tf.concat([real_img1, real_img2], axis=0)
# PHASE ONE - train the discriminator
with tf.GradientTape() as d_tape:
# create noise input
z = tf.random.normal(shape=(real_img.shape[0], 1, 1, z_dim))
# generate fake images
fake_img = model_G(z)
# feed the fake images to the discriminator
fake_out = model_D(fake_img)
# feed the real images to the discriminator
real_out = model_D(real_img)
# use the loss function to measure how well the discriminator
# labels fake or real images
d_fake_loss = loss_func(tf.zeros_like(fake_out), fake_out)
d_real_loss = loss_func(tf.ones_like(real_out), real_out)
# get the total loss
d_loss = (d_fake_loss + d_real_loss)
d_loss = tf.reduce_sum(d_loss) / (batch_size * 2)
# get the gradients
gradients = d_tape.gradient(d_loss, model_D.trainable_variables)
# update the weights of the discriminator
param_D.apply_gradients(zip(gradients, model_D.trainable_variables))
# PHASE TWO - train the generator
with tf.GradientTape() as g_tape:
# create noise input
z = tf.random.normal(shape=(real_img.shape[0], 1, 1, z_dim))
# generate fake images
fake_img = model_G(z)
# feed fake images to the discriminator
fake_out = model_D(fake_img)
# use loss function to measure how well the generator
# is able to trick the discriminator (i.e. model_D should output 1's)
g_loss = loss_func(tf.ones_like(fake_out), fake_out)
g_loss = tf.reduce_sum(g_loss) / (batch_size * 2)
# get the gradients
gradients = g_tape.gradient(g_loss, model_G.trainable_variables)
# update the weights of the generator
param_G.apply_gradients(zip(gradients, model_G.trainable_variables))
# return the losses and fake images for monitoring
return d_loss, g_loss, fake_img
As you can see, we have the two training blocks, and we return the Discriminator loss, the Generator loss and the last false images generated, which we have used to train the Generator.
As we have said, this function will be executed on different TPUs in parallel. It is necessary to find a way to concatenate the results returned by the different instances of the function as if they were returned by a single function.
This is handled by the @distributed function, with which we have decorated our train_on_batch function. Let’s go to see the distributed function:
class Reduction(Enum):
SUM = 0
CONCAT = 1
#This decorated function indicates how to concatenate the values
#returned by all the functions working in the different distributed
#TPU's.
#We have two possibilites. return a reducted SUM of each process, or
# a concatenation.
def distributed(*reduction_flags):
def _decorator(fun):
def per_replica_reduction(z, flag):
if flag == Reduction.SUM:
return strategy.reduce(tf.distribute.ReduceOp.SUM, z, axis=None)
elif flag == Reduction.CONCAT:
z_list = strategy.experimental_local_results(z)
return tf.concat(z_list, axis=0)
else:
raise NotImplementedError()
@tf.function
def _decorated_fun(*args, **kwargs):
fun_result = strategy.run(fun, args=args, kwargs=kwargs)
assert type(fun_result) is tuple
return tuple((per_replica_reduction(fr, rf) for fr, rf in zip(fun_result, reduction_flags)))
return _decorated_fun
return _decorator
The function receives a list of reductio_flags, which is nothing more than some constants that we have defined in the Class Reduction, which indicate how it should act with the values to return. For now, we only have two options: perform addition with reduction or concatenated.
Our train_on_batch function returns three elements and, therefore, when calling the decorator, we have to indicate how we want each of the elements to be treated.
@distributed(Reduction.SUM, Reduction.SUM, Reduction.CONCAT)
def train_on_batch(real_img1, real_img2):
......
......
......
# return the losses and fake images for monitoring
return d_loss, g_loss, fake_img
The train_on_batch function returns three parameters. In the call to @distributed we are indicating the Sum of the first two parameters, while a concatenation is applied to the third. It makes sense because the first two are numbers that show the loss of the discriminator and the generator, and the third is a list of the images generated.
Remember that you have the complete code available at:
GAN Tutorial 3. How to use TPUs to train a GAN.
Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
www.kaggle.com
Google Colaboratory
Edit description
colab.research.google.com
GANs/C3_Faces_TPU.ipynb at main · oopere/GANs
You can't perform that action at this time. You signed in with another tab or window. You signed out in another tab or…
github.com
The Training Loop.
Now we only have to call the train_on_batch function as many times as epochs we want to execute to train the GAN.
NUM_EPOCHS = 100
# generate a batch of noisy input
z_dim = 128
test_z = tf.random.normal(shape=(64, 1, 1, z_dim))
# start loop
tf.keras.backend.clear_session()
for epoch in range(NUM_EPOCHS):
with tqdm(dataset) as pbar:
pbar.set_description(f"[Epoch {epoch}]")
for step, (X1, X2) in enumerate(pbar):
# train on the current batch
d_loss, g_loss, fake = train_on_batch(X1, X2)
# generate fake images
fake_img = model_G(test_z)
# save face generated to file.
if not os.path.exists(out_dir):
os.makedirs(out_dir)
file_path = out_dir+f"/epoch_{epoch:04}.png"
# display gallery of generated faces
if epoch % 10 == 0:
plot_results(fake_img.numpy()[:4], 2, save_path=file_path)
After each call to train_on_batch we call the Generator to generate some images, so we can see how it is progressing. To achieve this, we not only show them on the screen, but we also save them on disk.

The images can be saved on disk, and this GIF can be created, which shows the process of the creation of faces by epoch.
What have we learned?
The most important thing is that we have seen how to work in a distributed notebook. We have used it to train a GAN using TPUs. But if we wanted to train any other model with multiple GPUs instead of TPUs the code wouldn’t change too much.
We have seen that you must create a strategy, instantiate the TPU, and take into account the returns of functions that are executed in parallel. These should be treated in such a way that they merge as if they were provided by a single function.
Regarding GANs, we have used a much more complete Dataset than the ones used in the previous articles. Therefore, we have adapted the structure of the Generator and the Discriminator, using the functions that we already created in the previous article.
What’s next?
I hope you liked the article. It’s been hard to make, and it’s longer than I wanted at first.
It is clear that it is not 100% based on GANs, but the use of TPUs or parallel processing to speed up training is very necessary in GANs, since they usually require plenty of resources and time.
In the next article, we return to the GAN! In the meantime, you can try different structures in the Generator and the Discriminator, or even increase the resolution of the output images.
It can also be a good exercise to transform the Notebook to work with GPUs, without parallel processing. This is simple, and will show the difference in performance.
I write about TensorFlow and machine learning regularly. Consider following me on Medium to get updates about new articles. And, of course, You are welcome to connect with me on LinkedIn.
More articles in the GAN series:
If you like TensorFlow and want to know some interesting techniques, check my series: TensorFlow Beyond The Basics.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

