



How to Use Hugging Face Pipelines?
Last Updated on February 13, 2023 by Editorial Team
Author(s): Tirendaz AI
Originally published on Towards AI.
A practical guide on how to perform NLP tasks with Hugging Face Pipelines
Image by Canva
With the libraries developed recently, it has become easier to perform deep learning analysis. One of these libraries is Hugging Face. Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more.
This blog will walk you through how to perform NLP tasks with Hugging Face Pipelines. Here are topics we’ll discuss in this blog.
- What is NLP?
- What is Transformers?
- Performing various NLP tasks with Transformers.
The NLP tasks we’ll cover are text classification, named entity recognition, question answering, and text generation.
Let’s dive in!
What is NLP?
NLP is a subfield of AI that allows computers to interpret, manipulate and understand human language. The goal of NLP tasks is to analyze text and voice data like emails, social media newsfeeds, video, audio, and more. With the NLP techniques, you can handle various tasks such as text classification, generating text content, extracting an answer from a text, etc.
NLP doesn’t just deal with written text. It also overcomes complex challenges in speech recognition and computer vision, such as creating a transcript of a sound sample or a description of an image.
Cool, we learned what NLP is in this section. Let’s go ahead and have a look at what the Transformers library is.
What is the Transformers library?
Transformers is a library in Hugging Face that provides APIs and tools. It allows you to easily download and train state-of-the-art pre-trained models.
You may ask what pre-trained models are. Let me explain. A pre-trained model is actually a saved pre-trained network that was previously trained on a large dataset. Using pre-trained models, you can save the time and resources needed to train a model from scratch.
Nice, we looked at what the Transformers library is. Let’s carry out some tasks to show how to use this library.
Transformer Applications
Transformers library has great functions to handle various NLP tasks. The easiest way to tackle NLP tasks is to use the pipeline function. It connects a model with its necessary pre-processing and post-processing steps. This allows you to directly input any text and get an answer.
To use the Transformers library, you need to install it with the following command:
pip install -q transformers
To show how to utilize the pipeline function, let’s import it from transformers.
from transformers import pipeline
Cool, we can now perform the NLP tasks with this object. Let’s start with sentiment analysis.
Sentiment Analysis
Sentiment analysis is one of the most used NLP tasks. It is the process of detecting positive or negative sentiments in text. To show how to do this task, let’s create a text.
text = "This movie is beautiful. I would like to watch this movie again."
Awesome, we now have a text. Let’s find out the sentiment of this text. To do this, first, we instantiate a pipeline by calling the pipeline function. Next, we give the name of the task we are interested in.
classifier = pipeline("sentiment-analysis")
Nice, we are ready to analyze our text using this object.
classifier(text)
# Output:
[{'label': 'POSITIVE', 'score': 0.9998679161071777}]
As you can see, our pipeline predicted the label and showed the score. The label is positive, and the score is 0.99. It turns out that the model is very confident that the text has a positive sentiment. Great, we have finished our sentiment analysis. It is simple, right?
Let’s take a step back and think about what happened. This pipeline first selected a pretrained model that has been fine-tuned for sentiment analysis. Next, when creating the classifier object, the model was downloaded. Note that when passing some text to a pipeline, the text is preprocessed into a format the model can understand.
In this analysis, we used a pipeline for sentiment analysis. You can also use it for other tasks. Some of the pipelines that have been developed recently are Sentiment-analysis; we just learned how to perform this pipeline, summarization, named entity recognition, question-answering, text generation, translation, feature extraction, zero-shot-classification, etc. Let’s have a look at a few of these. The pipeline we’re going to talk about now is zero-hit classification.
Zero-Shot Classification
Imagine you want to categorize unlabeled text. This is where the zero-shot classification pipeline comes in. It helps you label text. So, you don’t have to depend on the labels of the pretrained model. Let’s take a look at how to use this pipeline. First, we’re going to instantiate by calling the pipeline function.
classifier = pipeline("zero-shot-classification")
Now let’s create a text to classify.
text = "This is a tutorial about Hugging Face."
Let’s define candidate labels.
candidate_labels = ["tech", "education", "business"]
Cool, we created our text and labels. Now, let’s predict the label of this sentence. To do this, we’re going to use the classifier object.
classifier(text, candidate_labels)
# Output:
{'sequence': 'This is a tutorial about Hugging Face',
'labels': ['education', 'tech', 'business'],
'scores': [0.8693577647209167, 0.11372026801109314, 0.016921941190958023]}
As you can see, the text is about education. Here we didn’t fine-tune the model on our data. Our pipeline directly returned probability scores. This is why this pipeline is called zero-shot. Let’s move on and take a look at the text generation task.
Text Generation
Tools like ChatGPT are great for generating text, but sometimes you might want to generate text about a topic. The goal of text generation is to generate meaningful sentences. Our model gets a prompt and auto-completes it. Let’s see how to perform a pipeline. First, we instantiate the pipelines with text-generation.
generator = pipeline("text-generation")
Let’s go ahead and create a prompt.
prompt= "This tutorial will walk you through how to"
Now let’s pass this prompt to our object.
generator(prompt)
# Output:
[{'generated_text': 'This tutorial will walk you through how to setup a Python script to automatically find your favourite website using Python and JavaScript so you can build a web site that'}]
As you can see, a text was generated according to our sentence. Note that this text is randomly generated. So it’s normal if you don’t obtain the same results as here.
In this example, we used the default model. You can also select a specific model from the hub. To find a suitable model for your task, go to the model Hub and click on the corresponding tag on the left.
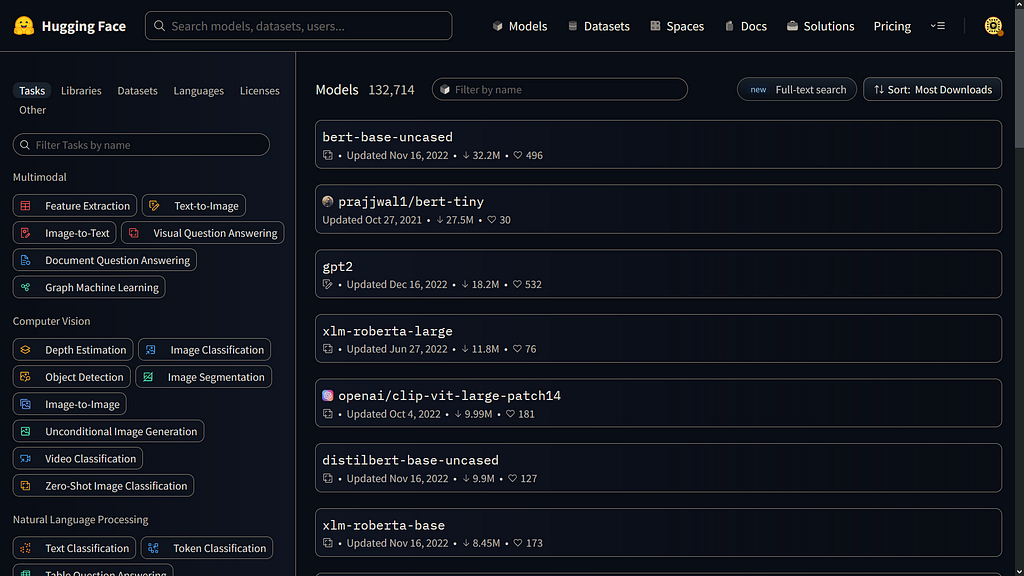
Here you can see the supported models for your task. Cool, let’s try a model. First, we’re going to create a pipeline. Let’s pass our task and model name to it.
generator = pipeline("text-generation", model="distilgpt2")
Cool, we instantiated an object. Let’s create a text with a maximum length of 30 using our previous prompt.
generator(prompt, max_length = 30)
As you can see, a text was created with the model we determined. Let’s go ahead and take a look at the named entity recognition task.
Named Entity Recognition (NER)
NER is one of the most popular data preprocessing tasks. In NLP, real-world objects like products, places, and people are called named entities, and extracting them from text is called named entity recognition. Let’s show how this task is done with an example. First, let’s create an object from the pipeline.
ner = pipeline("ner", grouped_entities=True)
Here we passed grouped_entities=True to regroup together the parts of the sentence. For example, we would like to group “Google” and “Cloud” as one organization. Now let’s create an example sentence.
"text = My name is Tirendaz and I love working with Hugging Face for my NLP task."
Now, let’s pass this text to our object.
ner(text)
# Output:
[{'entity_group': 'PER',
'score': 0.99843466,
'word': 'Tirendaz',
'start': 11,
'end': 19},
{'entity_group': 'ORG',
'score': 0.870751,
'word': 'Google Cloud',
'start': 31,
'end': 43},
{'entity_group': 'LOC',
'score': 0.99855834,
'word': 'Berlin',
'start': 47,
'end': 53}]
As you can see, our model correctly identified the entities in our text. Nice, let’s move on and the question-answering task.
Question-Answering
In question-answering, we give the model a piece of text called context and a question. The model answers the question according to the text. Let’s illustrate this with an example. First, let’s create an object from the question-answering pipeline.
question_answerer = pipeline("question-answering")
Now let’s use this object.
question_answerer(
question="Where do I live?",
context="My name is Tirendaz and I live in Berlin",)
# Output:
{'score': 0.7006925940513611, 'start': 31, 'end': 43, 'answer': 'Google Cloud'}
As you can see, our pipeline extracted information from the context. Cool, we learned how to perform various NLP tasks with the pipeline. You can also use pipeline for other tasks, such as summarization and translation.
You can find the notebook I used in this blog
Wrap-Up
Transformers is a library in Hugging Face that provides APIs and tools. You can perform NLP tasks using this library. The easiest way to do this is to use Hugging Face pipelines. Pipelines provide an easy-to-use API that connects a model with its necessary pre-processing and post-processing steps. So, you can easily carry out various NLP tasks using pipeline objects.
That’s it. Thanks for reading. I hope you enjoy it. Let me know if you have any questions. Follow me on Medium, so you don’t miss the latest content. We also create content about AI on other social media platforms. Don’t forget to follow us on YouTube | Twitter | Instagram 👍
Resources
How to Use Hugging Face Pipelines? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


