



How to Save and Load Deep Learning Models with Keras?
Last Updated on July 17, 2023 by Editorial Team
Author(s): Tirendaz AI
Originally published on Towards AI.
Learn how to use ModelCheckpoint callback
Training deep learning models is a time-consuming process. You can save model progress during and after training. So, you can resume the training of a model from where you left off and overcome the long training challenge.
In this blog post, we’ll cover how to save your model and load it step-by-step with Keras. We’ll also explore the ModelCheckpoint callback, which is often used in model training.
Let’s start by loading the dataset first.
Loading the Dataset
To demonstrate how to save a model, let’s use the MNIST dataset. This dataset consists of images of numbers.

Before loading the MNIST dataset, let’s first import TensorFlow and Keras.
import tensorflow as tf
from tensorflow import keras
Now, let’s load the training and test datasets with the load_data method in Keras.
(train_images,train_labels),(test_images,test_labels)=tf.keras.datasets.mnist.load_data()
The training input and output datasets consist of 60,000 samples, and the test input and output datasets consist of 10,000 samples.
Data Preprocessing
One of the most important steps of data analysis is data preprocessing. In deep learning, some data preprocessing techniques, such as normalization and regularization, improve the performance of the model.
First, let’s take the first 1000 samples from these datasets to run the codes faster. Let’s do this for the output variables first.
train_labels = train_labels[:1000]
test_labels = test_labels[:1000]
We’re going to do the same for training data. The data samples consist of images of numbers. These images are two-dimensional. Before giving these samples to the model, let’s convert them to a dimension with the reshape method. In addition, let’s normalize the data to increase the performance of the model and to make the training faster.
train_images = train_images[:1000].reshape(-1, 28 * 28) / 255.0
test_images = test_images[:1000].reshape(-1, 28 * 28) / 255.0
Nice, our data sets are ready for the model. Let’s go ahead and move on to the model-building step.
Building the Model
The easiest way to build a deep learning model is the Sequential technique in Keras. In this technique, the layers are stacked one by one. What we’re going to do now is define a function that contains our model. By doing this, we can easier build a model.
def create_model():
model = tf.keras.Sequential([
keras.layers.Dense(512, activation='relu',input_shape=(784,)),
keras.layers.Dropout(0.2),
keras.layers.Dense(10)
])
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]
)
return model
Let’s go through these codes. First, we define a function that creates and compiles a Sequential model using Keras.
We built a model that contains two dense layers, the first with 512 neurons and a relu activation function. We also set a dropout layer that randomly drops out 20% of the input units to help prevent overfitting. After that, we wrote a dense layer containing 10 neurons with no activation function, as it will be used for the logits.
Next, we compiled the model with the Adam optimizer and SparseCategoricalCrossentropy loss function. As metrics, we set SparseCategoricalAccuracy.
Finally, we used the return statement to return the compiled model.
Awesome, we’ve defined a simple Sequential model. Now, let’s take an example object named model from this function.
model = create_model()
Now let’s see the architecture of our model with the summary method.
model.summary()
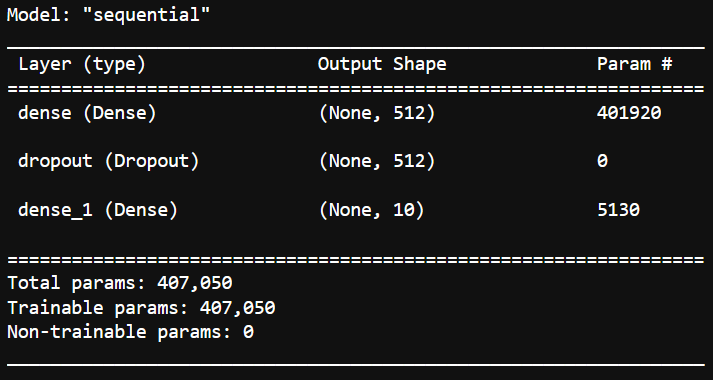
As you can see, our model consists of an input layer, a dropout layer, and an output layer. Let’s move on to exploring the ModelCheckpoint callback.
Saving Model Weights with ModelCheckpoint Callback
You can save your model to reuse a model you have trained or to continue training where you left off.
As you know, building a model actually means training the model’s weights, called parameters. With the ModelCheckpoint callback, you can save the weights of the model during model training. To illustrate this, let’s instantiate an object from this callback.
First, let’s create the directory where the model will be saved with the os module.
import os
checkpoint_path = "training_1/my_checkpoints"
checkpoint_dir = os.path.dirname(checkpoint_path)
Nice, we’ve created our directory. Now let’s create a callback to save the weights of the model.
checkpoint_cb = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_path,
# Let's save only the weights of the model
save_weights_only=True)
Great, we’ve created our callback. Now, let’s call the fit method and pass our callback to this method.
model.fit(train_images,
train_labels,
epochs=10,
validation_data=(test_images, test_labels),
callbacks=[checkpoint_cb])

So, we saved the model weights in our directory. The callback we use updates the checkpoint files at the end of each epoch. Let’s look at the files in the directory using the os module.
os.listdir(checkpoint_dir)
# Output
['my_checkpoints.index', 'my_checkpoints.data-00000-of-00001', 'checkpoint']
As you can see, the weights were saved after the last epoch. Let’s go ahead and take a look at how to load weights.
Loading Weights
After you save the weights, you can load them into a model. Note that you can only use the saved weights for models with the same architecture.
Let’s instantiate an object to demonstrate this.
model = create_model()
Note that we have not yet trained the weights of this model. These weights were randomly generated. Now let’s look at the accuracy score of this untrained model on the test data with the evaluate method.
loss, acc = model.evaluate(test_images, test_labels, verbose=2)
print(f"Untrained model, accuracy: {100 * acc:5.2f}%")
# Output:
Untrained model, accuracy: 10.70%
As you can see, the accuracy of the untrained model on the test data is about 10 percent. That’s a pretty bad score, right?
Now, let’s load the weights we saved earlier with the load_weights method and then look at the accuracy score of this model on the test data.
model.load_weights(checkpoint_path)
Awesome, we loaded the weights. Now let’s examine the performance of this model on the test set.
loss, acc = model.evaluate(test_images, test_labels, verbose=2)
print(f"Untrained model, accuracy: {100 * acc:5.2f}%")
#Output:
Untrained model, accuracy: 87.40%
As you can see, it turned out that the accuracy of the model was around 90 percent.
In this section, we have seen how to save model weights and how to load them. Now let’s go ahead and explore how to save the whole model.
Saving the Entire Model
After you train your model, you can want to deploy that model. To save the model’s architecture, weights, and training configuration in a single file, you can use the save method.
You can save your model in two different formats, SaveModel and HDF5. Keep in mind that in Keras, the SavedModel format is used by default. Let’s save our final model. Let’s create a directory for it.
mkdir saved_model
Now let’s save our model in this file.
model.save('saved_model/my_model')
Great, we saved our model. Let’s look at the files in this directory.
ls saved_model/my_model
# Output:
assets fingerprint.pb keras_metadata.pb saved_model.pb variables
Here you can see files and subdirectories. You don’t need the source code of the model to put the model into production. SavedModel is sufficient for deployment. Let’s take a closer look at these files.
The saved_model.pd file contains the model’s architecture and computational graphics.
The keras_metadata.pb file contains extra information required by Keras.
The variables subdirectory contains parameter values such as weight and bias.
The assets subdirectory contains extra files, such as the names of attributes and classes.
Nice, we saw how to save the entire model. Now let’s see how to load the model.
Loading the Model
You can load the saved model with the load_model method. To do this, let’s first create the model architecture and then load the model.
new_model = create_model()
new_model = tf.keras.models.load_model('saved_model/my_model')
Awesome, we have loaded the model. Let’s look at the architecture of this model.
new_model.summary()

Note that this model is compiled with the same arguments as the original model. Let’s look at the accuracy of this model on test data.
loss, acc = new_model.evaluate(test_images, test_labels, verbose=2)
print(f'Restored model, accuracy: {100 * acc:5.2f}%')
# Output:
Restored model, accuracy: 87.40%
As you can see, the accuracy score of the model we saved on the test data is 87 percent.
You can also save the model in h5 format. But most TensorFlow deployment tools require the SavedModel format.
Wrap-Up
When training a model, you can save your model to pick up where you left off. By saving the model, you can also share your model and allow others to recreate your work.
In this blog post, we covered how to save and load deep learning models. First, we learned how to save model weights with the ModelCheckpoint callback. Next, we saw saving and loading the entire model to deploy the model.
Thank you for reading. Let me know If you have any questions. You can find the link to the notebook here.
Let’s connect YouTube U+007C Twitter U+007C Instagram U+007C LinkedIn.
Improving Deep Learning Models Performance
with normalization and standardization
ai.plainenglish.io
How to Use ChatGPT in Daily Life?
Save time and money using ChatGPT
levelup.gitconnected.com
If you liked the article, do not forget to hit the clap button below a few times.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

