



How To Predict Multiple Variables With One Model? And Why!
Last Updated on January 6, 2023 by Editorial Team
Author(s): Pere Martra
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Do you want to save time and cost? As simple as creating a model capable of predicting multiple variables with the same training and in the same prediction process.
In the article, I’m going to show some code, but if you want to check the full code, it is available on Kaggle and GitHub. Where you can fork, modify, and execute it.
Guide: Multiple Outputs with Keras Functional API
When we start working with TensorFlow, we usually use the sequential format to create Models with the Keras library.
With sequential models, we can solve many problems in all fields of deep learning. Whether they are image recognition or classification, Natural Language Processing, or Series Forecasting… they are models powerful enough to be used in a large majority of problems.
But there are times when we need to go a little further in using Keras with TensorFlow. So, we can use the API for model creation, which opens up a wide world with many more possibilities that we did not have when using sequential models.
In this article, we are going to see the creation of a model capable of predicting two different variables using the same data and the same learning process, sharing a large part of the layers.
That is, we will create a Multi-Output model with two-layer branches. As we can see in the image:
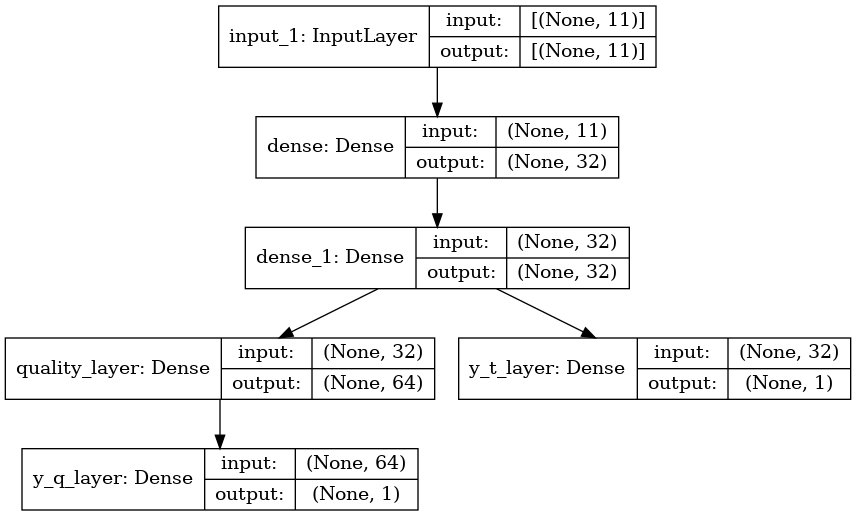
The model is made up of an input layer, followed by two dense layers. These three layers are the common part of the model. From here, the model is divided into two different branches. In one of the branches, we find the output layer of the classification variable. The other branch is composed of a dense layer and the output layer that predicts the regression variable.
Note that in the right branch, the model is predicting a classification variable, while on the left branch, the variable to predict is a regression variable.
In this article, we are going to see only how to generate and execute the model. The data treatment and subsequent evaluation of the model, as well as ideas on how to improve it, can be found in the Kaggle notebook.
A brief introduction to the Data and problem solved.
I have used a Kaggle Dataset that contains information about wines. They are data in tabular format, with 11 columns that can be considered features and two that will be our labels.
As the first label, I have selected the quality of the wine (quality), which ranges from 0 to 9. I have decided to treat it as if it were a regression variable and not a classification variable. Since it is a variable that shows that wine is getting better.
The second label is the type of wine (type), which indicates whether the wine is white or red. This is clearly a classification variable.
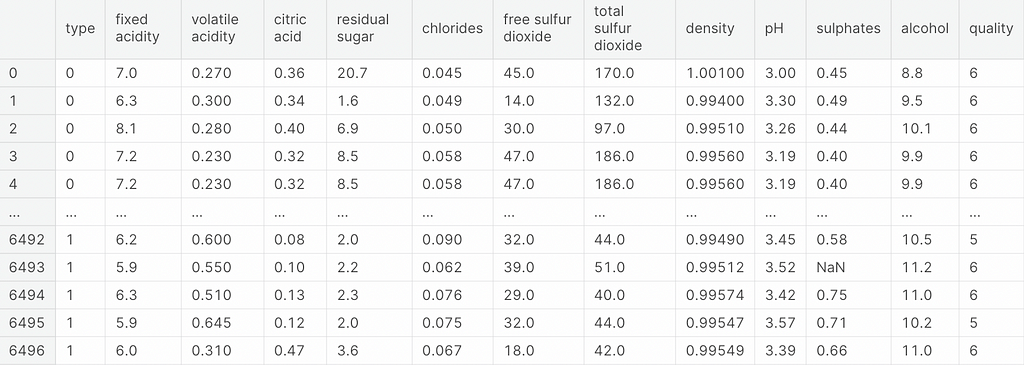
So, we have two variables of different types to predict in a single model.
After seeing the Dataset, we start the construction of the model.
As you can see, creating a model of this type is not complicated at all and opens up a world of new possibilities if we compare it with sequential models.
You have all the information in the comments in the code, but I would like to point out a couple of things.
I usually use the same name for the internal name of the layers and the name of the variables that contain the layers. Not only to make the code clearer but when we indicate the loss function and the metrics, the internal name of the layer must be indicated. When reporting the outputs of the model, we have to indicate the name of the variables containing the layers. It’s easier for me to always use the same name.
Different loss functions and metrics can be used for each output variable.
We really have to indicate them in two lists. One for the loss functions and another for the metrics, where we will relate them to the name of the layer.
model.compile(optimizer=optimizer,
loss = {'y_t_layer' : 'binary_crossentropy',
'y_q_layer' : 'mse'
},
metrics = {'y_t_layer' : 'accuracy',
'y_q_layer': tf.keras.metrics.RootMeanSquaredError()
}
)
What can multiple output models be useful for?
I do not pretend to give a complete answer since it is only my vision, and more experienced Data Scientists can find more uses for them.
This type of model is very useful in environments where periodic training must be carried out with a large volume of data to predict more than one variable. The time saved if we compare it with training two or three different models can be very significant, not only in time but also in cost.
They can also save a lot of time and process in environments where numerous predictions need to be executed repeatedly and the result of these is more than one variable.
On the other hand, they cost more to tune since, for example, it is more difficult to find a learning rate that can be optimal for all variables.
This is article is part of a series about advanced topics in TensorFlow and Keras, if you liked it, consider following me on Medium to get updates about new articles. And of course, You are welcome to connect with me on LinkedIn.
How To Predict Multiple Variables With One Model? And Why! was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

