



How to Create an E-Commerce Price Comparison App using Selenium and TkInter
Last Updated on January 6, 2023 by Editorial Team
Author(s): Vishnu Nair
Web Scraping
Motivation
From my years of being an avid e-commerce consumer, I have noticed certain inconveniences when buying a product of interest. One of these time-consuming hassles is finding the best value for said product. With just one query on these e-commerce websites, we often find ourselves scrolling through a plethora of items to find the one with the most ratings and most positive reviews all for a minimal price. There are so many options to buy something online that we often get flustered with the number of tabs open and “Compare price” buttons (which are at times, not even present).
Consider buying a headset for example. You spend a significant time researching the brands, specs, pros, and cons of this item until you pick one that satisfies your needs. After finally picking one, you are faced with an equally arduous task: figuring out which store to purchase the item from. Some stores are offering it at a $50 discount while others are not. Other sellers are providing an even steeper discount although their seller ratings are as high as you would like. The variance continues to increase and you get even more perplexed when making a simple purchase. What if we could automate this process to find an optimal purchase?
As our reliance on e-commerce continues to grow each day, it would be a great asset to have a tool that automates the laborious process of price comparison based on rating, number of ratings, and price. In this article, I will show you how to build a web scraper in Python that is able to do just that!
Our To-Do List
Before we get started, let us outline what we will be doing exactly. I am limiting the scope of this project to Amazon and eBay, arguably the two most popular e-commerce companies of today. By the end of this article will:
- Use the BeautifulSoup and Selenium libraries in Python to scrape data from Amazon and eBay
- Sort the dataset based on the number of ratings and price, obtaining the optimal top 10 potential purchases
- Create a GUI using the TkInter library that is user-friendly to put it all together
Using Python, we can winnow out a lot of the excess deals that you otherwise would spend time looking at. Not only does this save you time, but also money!
“Beware of little expenses; a small leak will sink a great ship” — Benjamin Franklin
The Scrapers
For this analysis, we first build two parsers, one for each website respectively. First, we would like the user to input a search term as well as a page range to scrape. For example, if we look for “sea salt” and enter a page range of 5, we would want our script to visit the Amazon/eBay webpage and scrape sea salt information iteratively until reaching the end of page 5.
Now that we have a goal in mind, let’s jump into the code. We have to first convert the syntax of the search term to match the manner in which the URL is constructed. We can get a general base URL using the website domains followed by the formatted search term, which is then followed by the page number we wish to scrape. Using this specific URL, we can use the Selenium API to point our scraper to it and get whatever information we desire.
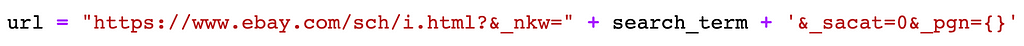
Each item of a webpage is constructed of HTML attributes. After finding the specific tags that correspond to items on that page, we can grab all the items that fall under those tags. Using the BeautifulSoup API, we can directly access the HTML source of the webpage and do so. Knowing which tags to locate is a trial-and-error process. Start by printing out whatever HTML code your tag-based query returns and modify them until you get the item you are looking for.
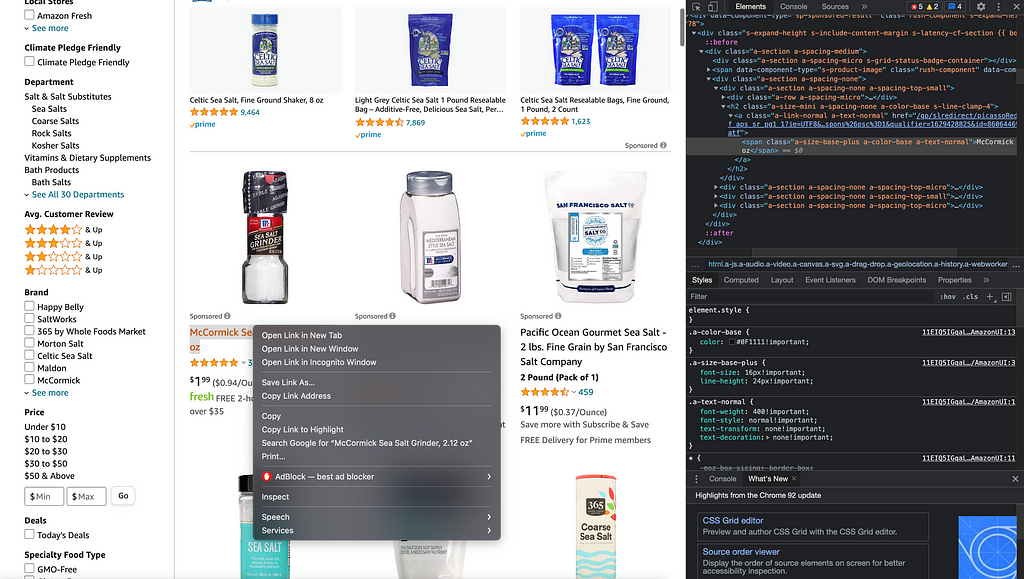
In my implementation, I use Chrome as the default browser. Whatever browser you choose, make sure to change the web driver type that you use in Selenium. Now that your parser knows what link to visit, we face the next problem: iterating through different pages. The way to approach this is quite simple. In the image above we have placed curly braces at the very end to format by page number. Now, all we have to do is set up a for-loop that contains the parser code, formatting by the page number at each iteration, and scraping all product information on said page. We use the ‘find’ function in the BeautifulSoup API to scrape the HTML tags containing this information.
With this, my parser is able to extract the name, price, condition, URL, shipping cost, average rating, and a number of ratings for each product on a page. There are instances when we get a blank query for these information bits. Thus, it is necessary to use try statements to circumvent errors. I created lists to store the parsed information, ensuring that placeholders are present if there is missing information as well. This was done so that every list maintains consistency in information. We can drop observations by index easily later on.
Hopefully, the above explanation made sense by itself, but in case it does not here is the code for the eBay parser here! Reading through the comments I wrote in tandem with the code will better illustrate the points I made previously.
This same logic applies when creating the Amazon parser. If you want to check out the code for it, you can in my GitHub repo here. Now that we have the two parsers, we need an external function that takes the resulting datasets and preprocesses them. I have done this in a function called ‘main’ in the GitHub repository. Within the function, I converted string variables to numeric in order to sort by the number of ratings for each product. This is the metric I chose when filtering for the top 10 items in a query. This metric can easily be tweaked based on your preference.
Creating the GUI
Now that we have the parser built, let's try to make this into a tool that others can use! I created a GUI using the TkInter library in Python. This API provides us a convenient and efficient way to create a friendly user interface for the scraper.
There are several modules that you can use within this library to get widgets within the interface. For this project, we utilize four:
- tk.Canvas: Use this to set the dimensions of the application window
- tk.Frame: Creates a rectangular area where you can place the widget of your choice
- tk.Entry: Creates a text box where the user can input text data
- tk.Button: Creates a button which upon clicking, can trigger a function (in our case this will be the scraper function)
It is also important to note three ways of adjusting the layout of your widgets. The TkInter library has three that you can utilize: place, pack, and grid. For our project, we utilize the “place” method exclusively. In my opinion, this is the most straightforward way of arranging your widgets as the method allows absolute x and-y-values as inputs. If you are curious about the other two methods, you can read about them here.
In my app, I created six frames. One houses the search bar where the user can enter their product of interest. Two of them serve as background for the canvas. One frame houses two other sub-frames that display the two datasets that are obtained from the scraping script. Then, I created two entry toolbars: one for the product name and the other for the maximum page number to scrape product data from. Lastly, I added a “Compare” button. When clicked, it triggers the “main” function discussed earlier which gives us the two sorted data-frames.
Let us see the app in action. I have searched for the Bose nc700 headset as an example. I prompted the app to scrape the first two pages of eBay and Amazon and sort according to my function, returning the top 10 queries for both websites. Here is our final product:
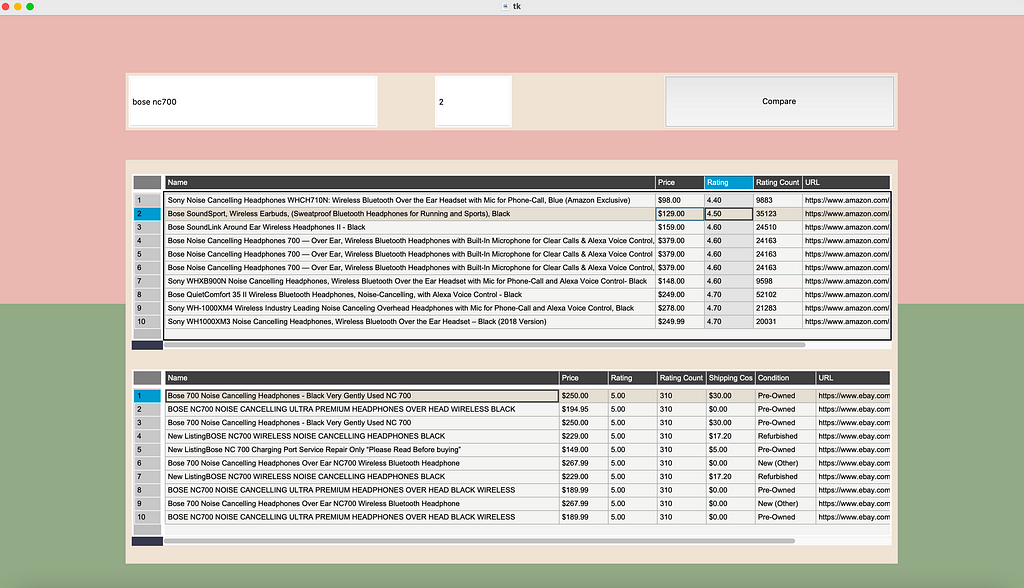
Based on the sorted data frames, we see that the top 10 choices for the product on eBay and Amazon do not have much difference in price. Hence, buying from either website would suffice, unless you want to save $50 or so buying a refurbished product.
Now that you have an idea of how this works, you can build your own parser and incorporate even more websites you wish to compare. The HTML tags you query for and the website URL will need to be queried for slightly different, however. When doing this, inspect the website attributes closely and experiment with different HTML queries until obtaining the information you desire.
As one can see, this tool may be quite helpful in comparing product deals across different websites and will save quite a bit of time. Instead of looking through various tabs and scrolling through endless products, we have the best purchase options at our fingertips!
As always, feel free to reach out if you have any questions or suggestions. Thank you for reading!
How to Create an E-Commerce Price Comparison App using Selenium and TkInter was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

