



How I used AI to create a word translator from English to my native language
Last Updated on February 27, 2022 by Editorial Team
Author(s): Nadir Trapsida
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Natural Language Processing
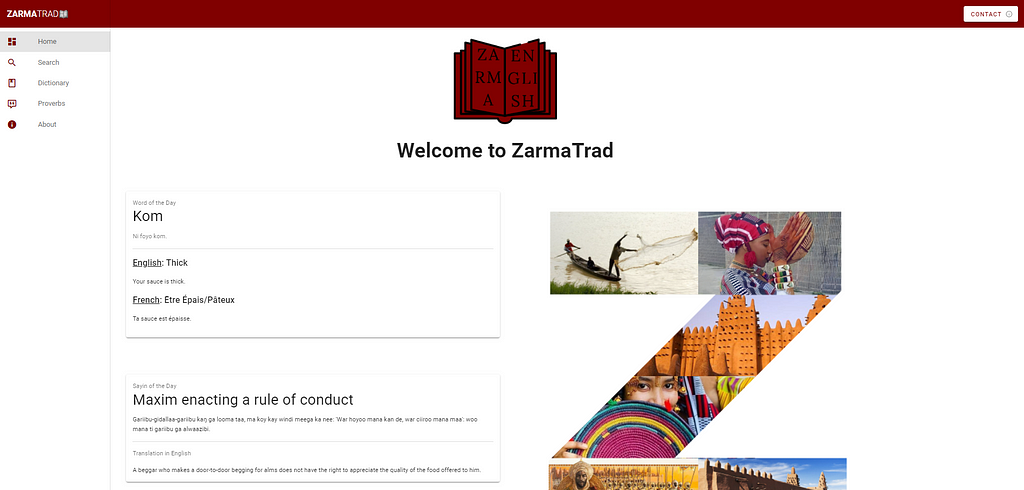
Recently I was searching to translate an English word in my native language, I went to google translate, but unfortunately, the language is not supported yet, so I started to browse all over the internet to find a translator but nothing much. All I could find was a table of words translated from Zarma to English and French, on an “old Pan-African wiki” webpage. That made me realize something important since French is the official language of the country, which forced people to become bilingual. The French are used in school and in all services, people tend to switch allegiance to the French, and it becomes more and more spoken to the detriment of the Zarma and that can lead to the death of the language. After much research on the topic, I learn that linguists have estimated that every 2 weeks, a language dies somewhere in the world. I decided so on to create a website using all my knowledge to help the community to maintain the survival of this fine language of ours.
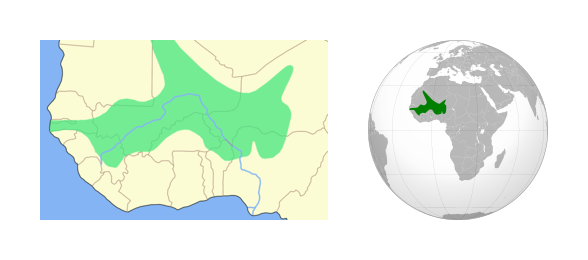
First, what is the Zarma/Songhai language?
The Songhai language was a language spoken in one of the largest states in Africa's history, the Songhai Empire. Then after the decline of this nation, the languages continues to be used, it became notably the language spoken in the well-known Mali empire ruled by the famous Mansa Moussa (Kankan Moussa) known for being referred to as the wealthiest person in history.
How the translation website has been made?
To make this project, I decided to use technologies I’m most comfortable with, so I went with Vue.Js and vuetify for the frontend, MongoDB for the database, python with selenium for the data mining, and finally, for the backend, I choose python with fast-API witch is a REST-API framework that claims to be faster and more efficient than a flask.
Data mining
To gather the data, all the words from the wiki webpage mentioned in the intro have been scrapped, then stored in a database. Since the website is old, many issues with the scrapping have been encountered, the table was not homogenous, for example, the words were sometimes in the same HTML tag as the examples and sometimes in another subtag and so on…
Backend
For the API it was really smooth, fast-API is kind of between Flask and Django, it has some useful tools and also supports swagger by default, which saves a lot of time since the documentation is generated automatically, I will definitely continue to use and learn more about it.
Frontend
I used to neglect the frontend side of all my projects but, I decided to put some effort and make something that will be enjoyed when used. The frontend has been created with Vue.Js and vuetify, this framework is so easy to use, I love it!!
Deploy
Finally, in the last part; I use Heroku to deploy all my hobby projects, hence it’s really user-friendly and the git integration works flawlessly. To deploy your projects you just have to connect the Heroku server to your git repo then add your Heroku configuration file also called Procfile.
How do I use AI to enhance the translations?
Since approximately 2500 translated words are stored in the database, it was impossible to find some words. Let’s say you want to find the word “mom” since the dictionary has only a small amount of words, the result won't be found, the search has to match perfectly the word in the database.
To fix it, I decided to use AI, because 🤷 why not 😅.
After numerous hours of searching on the internet, I came up with a solution. It was pretty simple, first, we have to convert all the words in embeddings, then when a word is searched, we just have to convert it in an embedding and pick the closest words by checking the distance (cosine similarity) between those.
Since the project is deployed on a free Heroku server, the storage was limited. Regarding that constraint, the model to convert words in embeddings has to be fairly small (RIP Universal Sentence Encoder). A combination of gensim using GloVe was the way to go and according to the papers, GloVe pre-trained models are more reliable than google word2vect ones. The pre-trained word vectors chosen have about 6 Billion words, and each word is represented as a 100-dimensional long vector. But with this pre-trained model, a lot of compound words didn’t work, so only the last part of those was used, and the first part was ignored.
For now, the conversion from word to embedding is done, the next step was to search for the closest vectors of a given one. The most used method is to compute the nearest neighbors using Scikit-learn, but I wanted to use something new.
Facebook AI Similarity Search (FAISS), is a “library for more efficient similarity search” according to Facebook. FAISS allows us to index a set of vectors, then given a vector we can make a query to find the most similar vectors within the index. It uses only RAM (random access memory) and is very efficient.
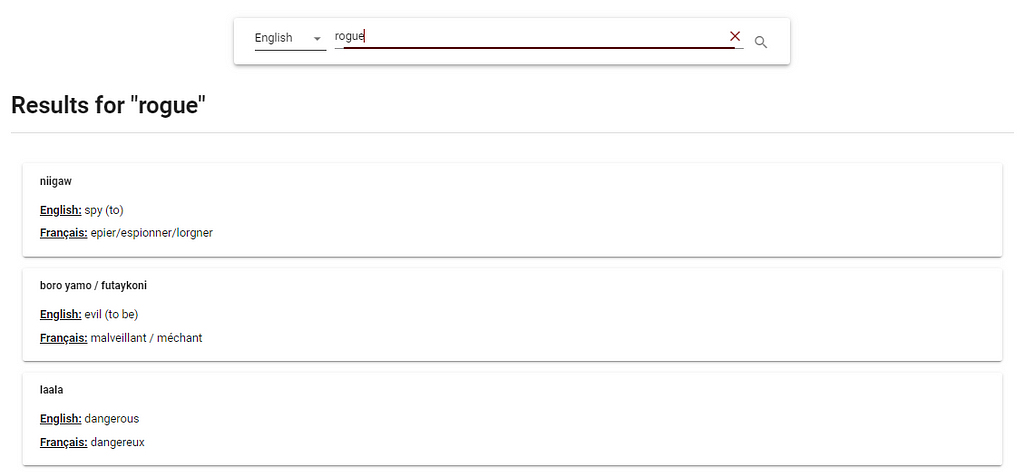
Thence, FAISS is perfect for the situation, when the server starts all word embeddings that are in the database are loaded then stored in FAISS, therefore when a query is received from the API, the word is converted to a vector then searched in FAISS. The results came out to be not bad at all, for example, if we search for “rogue” the closest words in the database returned are: “evil”, “spy” and “dangerous” and these are very acceptable.
What are the next steps?
So far, the website is working well, but we can still improve it by adding more features to make it even more complete and accurate. We can capitalize on two major improvements to increase the quality of the dictionary.
First, enriching the database with more words will help considerably. To do that, finding another source of data or talking to a Zarma/Songhai linguist expert will be the way to go.
Next, make the interface more enjoyable for the users by adding an audio button that will pronounce or read words, that are not familiar.
Thank you for reading!
❤️ If you have any questions, comment, or just want to contribute, do not hesitate and contact me at trapsidanadir@gmail.com
😊 If you enjoyed the article, share it and consider giving it a few 👏.
🌐 You can find the project using this link
How I used AI to create a word translator from English to my native language was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

