



Google’s Audiolm: Generating Music by Hearing a Song’s Snippet
Last Updated on January 6, 2023 by Editorial Team
Last Updated on October 14, 2022 by Editorial Team
Author(s): Salvatore Raieli
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Whether music or speech, Google's new model can continue playing what is hearing.
AudioLM is Google’s new model, capable of generating music in the same style as the prompt. The model is also capable of generating complex sounds such as piano music or people talking. the result is stunning. In fact, it seems to be indistinguishable from the original.
Why is generating music difficult?

Generating music is not an easy task. In fact, generating audio signals (music, ambient sounds, people's speech) requires multiple scales of abstraction. For example, music has a structure that has to be analyzed over a long period of time and is also composed of numerous interacting signals. Even personal speech itself can be analyzed at different levels, be it the simple acoustic signal or phonetics, but also in terms of prosody, syntax, grammar, or semantics.
Several attempts have been made previously. The first attempts to generate music focused on generating MIDI files (an interesting project where they generated MIDI music for piano was created in 2018 using a transformer). In addition, some studies focused on tasks such as text-to-speech, where speech is generated from a transcript. The problem is that everything that is not in the transcript is not translated into the audio file. Several studies explain how in human communication, pauses and inflections, and other signals are extremely important.
For example, those using Alexa or other speakers have noticed that the voice does not sound natural. Especially in the early days, no matter how correct the pronunciation was, it sounded unnatural and gave an uncanny effect.
AudioLM, the new Google model

A few days ago, Google announced the release of a new model: “AudioLM: a Language Modeling Approach to Audio Generation”. The new model is capable of generating audio (such as realistic music and speech) just by listening to audio.
Google AI on Twitter: "Learn about AudioLM, an audio generation framework that demonstrates long-term consistency (e.g., syntax in speech & melody in music) and high fidelity, with applications for speech synthesis and computer-assisted music. ↓ https://t.co/onTH6HdCcX / Twitter"
Learn about AudioLM, an audio generation framework that demonstrates long-term consistency (e.g., syntax in speech & melody in music) and high fidelity, with applications for speech synthesis and computer-assisted music. ↓ https://t.co/onTH6HdCcX
As they blogged, there has been a great improvement in the field of Natural Language Processing (NLP) in recent years. In fact, language models have proven to be extremely effective in a number of tasks. Many of these systems are based on the use of transformers, and those who have used them know that one of the initial pre-processing steps is to tokenize (break up the text into smaller units that are assigned a numerical value).
The key intuition behind AudioLM is to leverage such advances in language modeling to generate audio without being trained on annotated data. — Google AI blogpost
AudioLM does not need transcription or labeling. The authors collected a database of sounds and fed it directly to the model. The model compresses the sound files into a series of snippets (sort of tokens). These tokens are then used as if they were an NLP model (the model, in this way, uses the same approach to learn patterns and relationships between the various audio snippets). In the same way as a text-generating model, AudioLM generates sounds from a prompt.
The result is very interesting, the sound is much more natural. AudioLM seems to be able to find and recreate certain patterns present in human music (like subtle vibrations contained in each note when piano keys are struck). In the link below, Google has provided a number of examples if you are curious to listen:
AudioLM has been trained on a vast library of sounds that include not only music but also human voices. For this reason, the model can generate sentences produced by a human being. The model is able to pick up the accent of the speaker and add pauses and exclamations. Although many of the sentences generated by the model do not make sense, the result is impressive.
Indeed, treating sequences of sounds as if they were sequences of words may seem like a clever approach, nonetheless, some difficulties remain:
First, one must cope with the fact that the data rate for audio is significantly higher, thus leading to much longer sequences — while a written sentence can be represented by a few dozen characters, its audio waveform typically contains hundreds of thousands of values. Second, there is a one-to-many relationship between text and audio. This means that the same sentence can be rendered by different speakers with different speaking styles, emotional content and recording conditions. — Google AI blogpost
In more detail, the audio tokenization approach was already tried by OpenAI Jukebox, only that the model generated many more artifacts, and the sound did not sound as natural.
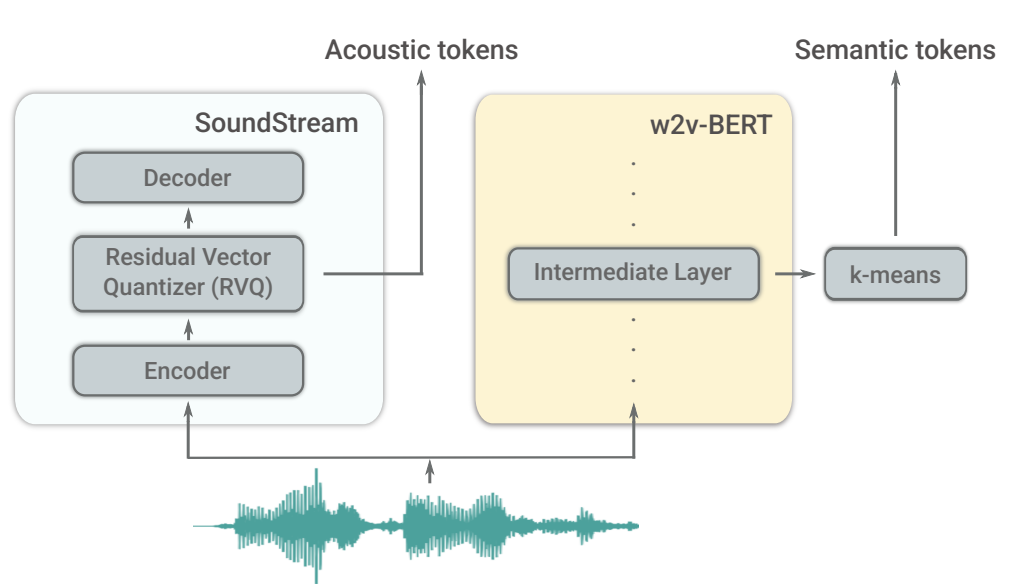
As described by the authors, the model consists of three parts:
- a tokenizer model, which maps a sequence of sounds into a discrete sequence of tokens. This step also reduces the size of the sequence (the sampling rate is reduced by about 300 times).
- a decoder-only transformer (a classical language model) that maximizes the likelihood of predicting the next tokens in the sequence. The model contains 12 layers with 16 attention heads, an embedding dimension of 1024, a feed-forward layer dimension of 4096
- a detokenizer model that transforms predicted tokens into audio tokens.
The model was trained on 60,000 hours of English speech and 40,000 hours of music for the piano experiments.
For this, we retrain all components of AudioLM on an internal dataset of 40k hours of piano music that includes players from beginner to expert level, and exhibits a wide range of different acoustic conditions, with content ranging from piano scale exercises to famous pieces. — source the original article
You can also watch the results in this short video:
The authors report that people who listened to AudioLM results failed to notice the difference with the original recording of human speech. Because the model could be used against AI principles (malicious applications, deep fakes, and so on), the authors have built a classifier that can recognize audio made with AudioLM and are investigating technology for audio “watermarking”
Parting thoughts

In recent months we have seen how several models have been capable of generating images (DALL-E, stable diffusion) and there are models such as GPT3 capable of generating text sequences. Generating audio sequences presents some additional difficulty but it seems that we will soon see some more major advances on this front.
In fact, Google has just unveiled AudioLM, a model capable of using an audio prompt (voice or piano) and generating the continuation. On the other hand, the same group that presented stable diffusion has just presented Harmonai (which, in fact, uses a similar algorithm of stable diffusion).
These technologies in the future could be used as background music for videos and presentations, better applications for health care settings, or Internet accessibility. On the other hand, these technologies could be used for deep fakes, misinformation spreading, scams, and so on.
If you have found it interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn. Thanks for your support!
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
Or feel free to check out some of my other articles on Medium:
- How artificial intelligence could save the Amazon rainforest
- Nobel prize Cyberpunk
- AlphaFold2 Year 1: Did It Change the World?
- Blending the power of AI with the delicacy of poetry
Google’s Audiolm: Generating Music by Hearing a Song’s Snippet was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

