



From Vision to Sound: How Meta’s ImageBind is Bridging Modalities in AI
Last Updated on July 17, 2023 by Editorial Team
Author(s): Sriram Parthasarathy
Originally published on Towards AI.
Unleashing the Power of Combined Senses: How ImageBind could redefine AI Experiences
Meta’s ImageBind is an open-source artificial intelligence model that can learn from many different kinds of information all at once, like images, sound, and movement. It creates a shared understanding of how different things are connected, like linking objects in a photo with the sounds they might make, their 3D shape, how warm or cold they are, and how they move. It can help machines to better understand information from the world around them and can be used in many different industries, like healthcare, finance, and manufacturing, to help solve problems and make tasks easier.
One example of ImageBind is using it to generate images from audio. For instance, if you have an audio recording of a rainforest, ImageBind can use the sounds to create an image that looks like what the rainforest might look like. Another example could be using ImageBind in the real estate industry to create virtual tours of properties. The model could use images, sound, and movement data to create an immersive experience that gives potential buyers a better understanding of the property.
What is ImageBind
ImageBind is an advanced technology that brings together six different types of data into one shared space. These types of data include visuals like images and videos, thermal information from infrared images, text, audio, depth details, and movements captured by an IMU sensor. IMUs are commonly found in devices like phones and smartwatches, and they help detect movements and activities. With ImageBind, all these diverse data types can be combined and understood together, providing a more comprehensive and holistic understanding of the world around us. This unique capability allows ImageBind to bridge the gap between different forms of information and enhance the potential applications of AI.
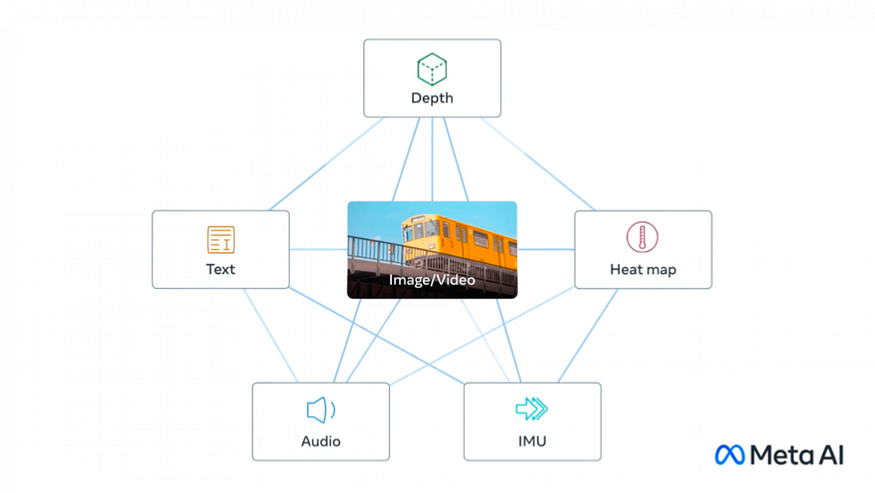
ImageBind is designed to create a shared representation space, or a single embedding, that connects different types of data together. For example, if ImageBind is given an image of a car and an audio recording of a car engine, it can use the shared representation space to connect the image with the sound of the car engine, even without explicitly being trained on paired data. This holistic understanding allows ImageBind to analyze many different forms of information together and generate new content from it, such as creating an image from audio or finding links between different types of data. This capability could potentially lead to new breakthroughs in areas such as content moderation, creative design, and multimodal search functions.
ImageBind in action
Let's see a few examples of using ImageBind in action.
1. Generate audio based on a specific image input
Pair images with corresponding audio to create a more immersive experience. For example, using AI tools like ImageBind, you can generate sound effects that match the image of a dog, such as barking or wagging tail. This adds depth and interactivity to visual content, making it more engaging and realistic for viewers. It allows for the creation of dynamic and captivating experiences that combine both visual and auditory elements seamlessly.

2. Generate an image based on a specific audio input
For example, by using ImageBind, you can create an image that is associated with the sound of a helicopter. The model analyzes the audio data and generates an image that represents or corresponds to the audio input. This capability allows for the exploration of audio-visual connections and provides a unique way to generate visual content based on different sounds.

3. Generate an image + audio based on a specific text input
Create an image and accompanying audio based on a given text input. For instance, if you provide a description of a train, ImageBind can generate a corresponding image of a train and even produce audio that resembles the sound of a train moving on the tracks. This multimodal capability allows ImageBind to bring together different modalities, such as text, images, and audio, providing a more immersive and realistic experience. So, if you were to input a text like “A train chugging through the countryside,” ImageBind can create an image of the steam train in action and generate audio that captures the distinct sounds of its engine and wheels on the tracks.

4. Generate a new merged image based on a specific audio + image input
Create a fresh combined image using a particular audio and image input. For example, you can use a recording of a dog barking and an image of a beach. ImageBind can merge these two inputs together, resulting in a new image that represents the combination of the audio and the beach picture. This innovative feature allows for the generation of unique visuals that are influenced by specific sounds, opening up creative possibilities and offering a novel way to explore the relationship between different forms of media.

Image-Content Binding: A Path to Learning a Single Embedding Space
People are good at learning new things with just a few examples. For example, we can read about an animal and then recognize it when we see it. We can also look at a picture of a car and imagine how it sounds. This is because a single image can bring together different senses and create a complete experience. In the field of AI, it can be challenging to learn from different types of information when we don’t have enough data that is paired together.

However, ImageBind has found a way to overcome this challenge. It uses large-scale models that understand both images and text to create a shared space where different types of data can be combined. ImageBind demonstrates that when paired with images, various modalities can be effectively connected. For instance, ImageBind can associate audio and text even without them being presented together, enabling other models to comprehend new modalities without extensive training. The model enables a comprehensive understanding of content, facilitating communication and linkages between different modalities without requiring direct observation. This allows the model to learn visual features along with other types of information. This flexibility broadens the potential of AI models and opens doors to richer multimodal experiences.
Unlocking the Power of ImageBind: Enhanced Performance with Limited Training
ImageBind has shown remarkable performance in its ability to outperform previous models that were trained for individual modalities, such as audio or depth. For example, when compared to a specialist model for audio classification, ImageBind achieved approximately 40 percent higher accuracy in top-1 accuracy for few-shot classification tasks. Similarly, when compared to specialist models for depth classification, ImageBind achieved improved performance on zero-shot recognition tasks across different modalities.
ImageBind, can improve its performance even with very little training data. As it grows larger, it gains new abilities that were not present in smaller models. For example, it can recognize which sounds go well with specific images or estimate the depth of a scene just from a picture.
Vision model is the key for ImageBind. The performance of ImageBind improves when the image part of the model becomes stronger and more powerful. This means that larger vision models not only help with tasks related to images but also with tasks like classifying sounds.
Though only six types of information were used, additional modalities such as touch, speech, smell, and brain fMRI signals, which connect more senses, will allow for the development of more advanced AI models that are closely aligned with human experiences.
Potential use of this technology: Recreating crime scene
Imagine a detective investigating a suburban home burglary. Using ImageBind, a multimodal AI tool, the detective can recreate the entire crime scene in a video format. By analyzing images from security cameras, aligning them with corresponding audio recordings, and utilizing thermal and motion sensor data, multi-modal support can potentially generate a detailed video reenactment.

This includes synchronized sounds, a realistic living room, and precise locations of individuals involved. The detective gains distinctive opportunities to animate static images by combining them with audio prompts.
For example, an image of an alarm clock with the sound of a rooster crowing can segment and animate the clock, while an audio prompt of an alarm sound can segment and animate the rooster. ImageBind empowers the detective to reconstruct the crime accurately, aiding in their investigative efforts and enhancing the efficiency of solving the case.
From Healthcare to Manufacturing: ImageBind’s Potential Applications in Different Sectors
Here are some examples of potential applications of this technology in other industries by making use of the Multimodal capabilities of ImageBind along with other technologies to provide comprehensive solutions.
1. Industry: Life Sciences
- Potential application: Multimodal analysis of medical images and patient data
- Example use case: Analyze various types of medical images and patient data, such as radiology images, electronic health records, and biosignal data. Use the information from these different modalities and provide a holistic understanding of the patient’s health status.
- Pain point it solves: The traditional approach to medical imaging analysis often requires manual interpretation of separate modalities, leading to potential errors or overlooking critical information. Multi-modal input + analysis could address this pain point by enabling a holistic analysis that combines multiple modalities, improving accuracy and supporting better decision-making in healthcare.

2. Industry: Finance
- Potential application: Fraud detection
- Example use case: Analyzing data from multiple modalities, including transaction history, audio from customer calls, and video footage from surveillance cameras, to identify potentially fraudulent activity.
- Pain point it solves: Traditional fraud detection methods can be time-consuming and prone to errors.
3. Industry: Manufacturing
- Potential application: Quality control
- Example use case: By integrating visual data with other modalities, such as sensor data and text descriptions, ImageBind could analyze images of manufactured products in real time. Multi-modal input + analysis could identify defects, anomalies, or deviations from the desired specifications. For example, it could assess the surface quality of a product, detect imperfections, and classify them based on severity.
- Pain point it solves: Traditional quality control methods in manufacturing often rely on manual inspections or limited automation, which can be time-consuming, prone to errors, and subjective. Multi-modal input + analysis could address these pain points by leveraging its ability to combine multiple modalities, resulting in more accurate and efficient defect detection processes, reducing waste, and improving overall product quality.

4. Industry: Oil and Gas
- Potential application: Asset Inspection and Maintenance
- Example use case: Analyzing data from multiple sensors, such as vibration sensors and thermal cameras, to identify potential equipment failures before they occur.
- Pain point it solves: Equipment failures can be costly and cause downtime, leading to decreased productivity and increased maintenance costs. Traditional methods often involve manual inspections or limited use of data, leading to potential risks, costly downtime, and suboptimal maintenance decisions.
5. Industry: Real estate
- Potential application: Property Maintenance and Management
- Example use case: By integrating visual data, textual descriptions, and additional sensor data, Multi modal input + analysis could facilitate the assessment and monitoring of properties to highlight specific assets that need attention.
- Pain point it solves: Property maintenance and management can be complex, involving the manual inspection of various aspects and keeping track of maintenance activities.
Conclusion
In conclusion, ImageBind is a groundbreaking AI model that brings together different types of data to create a comprehensive understanding of content. It has the ability to connect images, text, audio, depth, thermal, and motion data, enabling machines to learn and analyze information holistically. ImageBind’s performance surpasses specialist models and demonstrates its potential in various industries. With its unique capabilities, ImageBind opens doors to innovative applications in fields such as healthcare, finance, manufacturing, oil and gas, real estate, and automobiles. As AI continues to advance, ImageBind paves the way for machines to learn from multiple modalities just as humans do, leading to enhanced creativity, problem-solving, and more immersive experiences.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

