



From OLTP to Data Lakehouse
Last Updated on June 9, 2022 by Editorial Team
Author(s): Guilherme Banhudo
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
A layman’s overview of the Data ecosystem in a few paragraphs
The Data ecosystem has grown exponentially in the last years, with emerging technologies and increasing vendor-hype clouding the way for newcomers. This post is my brief and simple attempt to explain the origin and path from OLTP to Data Lakehouse in a few short paragraphs.
Bear with me, hopefully, in five minutes, the journey will be clear.
From the top to bottom approach, we can generically think of two broad categories of Databases: SQL and NoSQL. In simple and generic terms, the former is relational databases whereas the latter are non-relational. The former are table-based, whereas the latter can have multiple storage options (key, document, graph, and wide-column). The former hinges heavily on the concept of multi-row Transactions (you can think of Transactions as a group of tasks that either succeed as a whole, or fail as a whole), and the latter is more suitable for unstructured data (although lately, this line has become increasingly blurrier).
Relational Database Management Systems (RDBMS) implement ACID compliance, which, among others, manages Transactions for SQL-based databases. NoSQL databases, in turn, abide by the BASE compliance (I wrote a long article on the subject).
Most backend systems rely on Online Transaction Processing (OLTP), handling multiple Transactions, the record reads, writes, updates, and deletes (CRUD operations), and typically, do not save historical data. However, for data teams, every change is important hence, we require systems that can handle extremely large amounts of records holding every single business-relevant change which occurred in the operational databases! But this large data now needs to be stored and queried efficiently. For this purpose, RDBMS has been expanded to support complex queries to large amounts of historical data, aggregated from OLTP databases and other sources, resulting in Online Analytical Processing (OLAP). Typically, this vast data is stored in the form of a Data Warehouse, data structures optimized for analysis that often reaches Petabytes of scale.
While OLAP works for several situations, like all RDBMS, they are vertically scalable (note: Distributed SQL does tackle this point, however, its popularity is small at the moment). NoSQL in turn is horizontally scalable meaning, lower data storage costs as your data grows, a highly desirable but unattainable characteristic for OLAP for a long time, since the missing ACID compliance in NoSQL, is incredibly useful. What if we could combine RDBMS ACID compliance, OLAP’s massive historical data analysis capabilities, with NoSQLs horizontal scalability? This is where the Data Lakehouse shines.
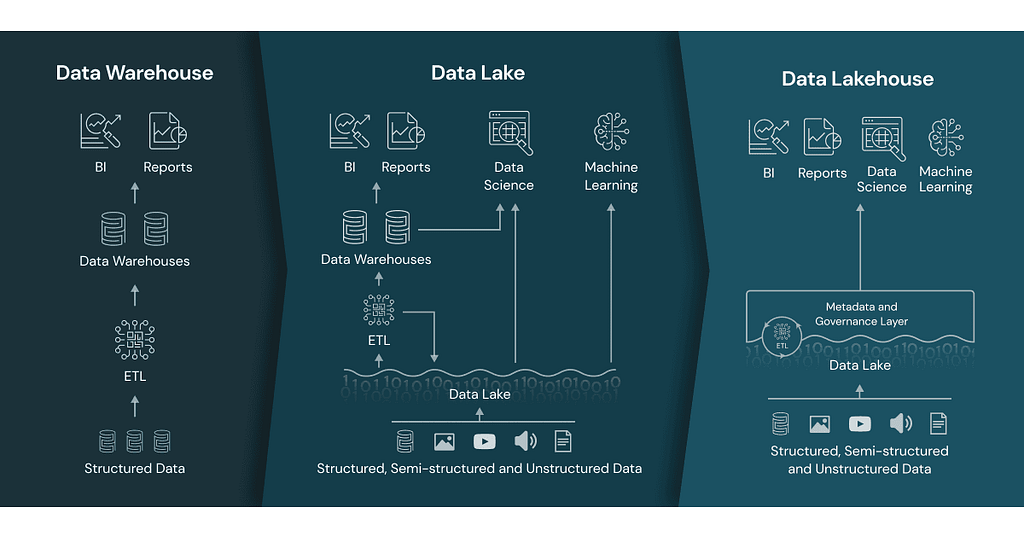
Data Lakehouses leverage the concept of Data Lakes, file systems supporting vast amounts of structured and unstructured data at low costs; Data Warehouses; and decoupled processing. In other words, Data Lakehouses do not require you to have a server constantly online as RDBMS do, and use Data Lakes for storage. Why is this important?
- If your data does not need to be accessed every single second, then you can save on the cost of having a server constantly online, with the tradeoff of having some latency to retrieve your data
- In fact, since processing is independent of storage, you can actually use more powerful clusters to process your data, which only run — and you only pay for — for the duration of the workload. Meaning, you get more juice for a fraction of the cost. In addition, you can even configure per-workload server characteristics, further optimizing your costs
- RDBMS are expensive to grow, relying on expensive and coupled hardware. But a Data Lakehouse relies on files that, with some magic, have an ACID compliance layer on top of it, along with some other nifty optimizations and features (see Delta.io). And we all know, file storage is cheap, especially when you can optimize your cost around the file usage frequency (unfrequent file access layers are significantly cheaper)
- You can build your Data Warehouse directly in Delta leveraging the aforementioned advantages
- Delta contains a set of very powerful features that greatly facilitate the Data Engineer’s job: ACID transactions, scalable metadata, time travel, unified batch/streaming, schema evolution & enforcement, audit operations, DML operations, etc. All of which, in an open-source project so, no vendor lock-in
- You can hold data in multiple formats and curation levels, serving multiple use cases: from Data Analysis/BI to Data Science/ML
Are there no drawbacks? Like all technologies, none is perfect and the choice of technology must be made according to the context and requirements. Lakehouses are no different, and they suffer from their own set of drawbacks:
- The technology is fairly recent (Delta Lake 1.0 was certified by the community in May 2021) meaning, several features may mutate and some highly desirable features may be missing for the time being
- The technology is very different from traditional RDBMS, especially, in terms of optimization thus representing a larger risk and may be harder to find experienced professionals
- They are hard to optimize, relying on several different techniques, some of which, must be implemented from the start of the project (Bloom Filters)
- Like all new technologies, documentation, examples, and best practices are scarce
- Finally, it is important to reflect on the BI/reporting layer since some BI tools (Power BI for instance), will make a query for each visual hence, complex dashboards, especially those users interact a lot with, may drive high costs
Let me know if the article helps shed some light on the ecosystem — although in simple terms — or if you feel something is not quite accurate!
From OLTP to Data Lakehouse was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

