



Falcon 40B — Data Powered AI Revolution
Last Updated on July 17, 2023 by Editorial Team
Author(s): M. Haseeb Hassan
Originally published on Towards AI.
Falcon-40B is an advanced step in the world of Large Language Models (LLMs). It is a foundational language model that is not specifically optimized for any particular task or purpose. Instead, it serves as a versatile “base” model that can be fine-tuned according to specific requirements or objectives. This flexibility allows users to adapt and customize Falcon-40B for various applications, tailoring its capabilities to suit specific language processing tasks.
What are LLMs?
Large Language Models (LLMs) are fundamental machine learning models that employ deep learning algorithms to comprehend and process natural language. They undergo training using extensive text data to acquire knowledge of language patterns and connections between entities. LLMs excel in various language-related tasks, including language translation, sentiment analysis, chatbot interactions, and more. They possess the ability to grasp intricate textual information, recognize entities, establish relationships among them, and generate coherent and grammatically correct text.
Falcon
Falcon-40B is an expansive model with 40 billion parameters, designed as a causal decoder-only model. Developed by the Technology Innovation Institute (TII) based in Abu Dhabi, it forms a crucial part of the Advanced Technology Research Council, responsible for overseeing technology research within the emirate. As a pioneering force in the field of science, TII aims to establish groundbreaking benchmarks and act as a catalyst for transformative advancements.
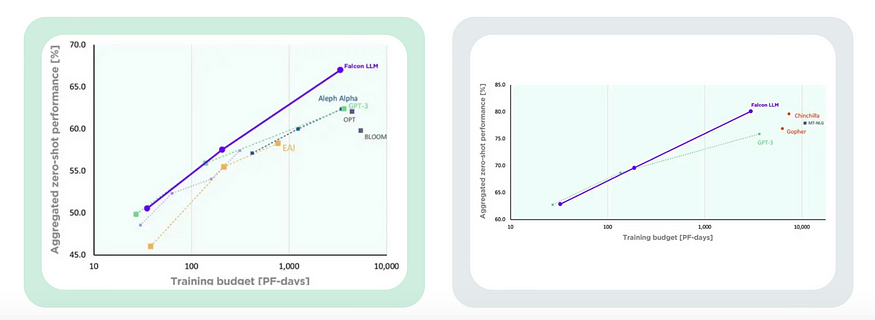
Falcon surpasses the performance of LLaMA, StableLM, RedPajama, MPT, and other models. It incorporates the FlashAttention method (as referenced) to achieve faster and optimized inference. FlashAttention enables Transformers to be trained more efficiently compared to existing benchmarks. Notably, it achieves a 15% end-to-end wall-clock speedup on BERT-large (with a sequence length of 512) compared to the MLPerf 1.1 training speed record. Additionally, it achieves a 3× speedup on GPT-2 (with a sequence length of 1K) and a 2.4× speedup on the long-range arena (with sequence lengths ranging from 1K to 4K). Moreover, Falcon is available under a license that permits commercial use, and the terms of the license can be reviewed here.
Training Data
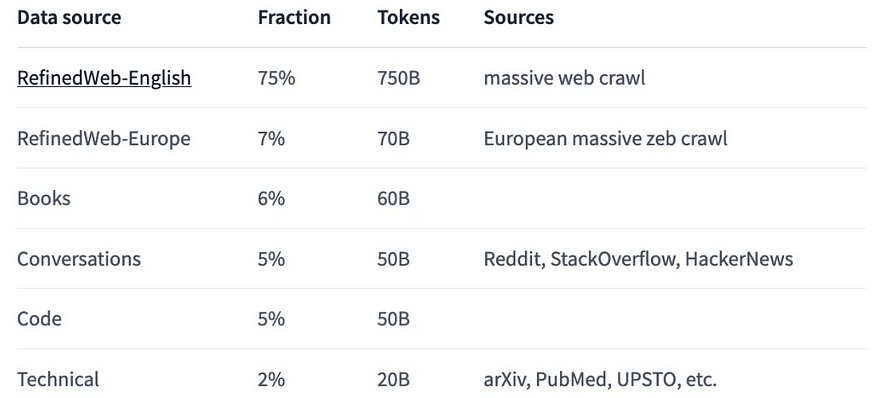
Falcon was trained using 1000 Billion tokens of refined-web dataset.
The refined web includes following.
The training process for this model involved the parallel utilization of 384 A100 (40Gb) GPUs. The training dataset consisted of a staggering 1000 billion tokens. Commencing in December 2022, the training process took approximately two months to reach completion. The model is composed of 60 layers and utilizes 64-head attention, with a vocabulary encompassing 65,024 tokens. However, it is worth noting that the sequence length is limited to a maximum of 2048 tokens. To optimize the training, the model employed the AdamW optimizer and utilized a batch size of 1152.
Want To Try?
Certainly, if you’re eager to explore this impressive model, you can experiment with the Falcon-7B version. While it may not offer the same level of excellence as the 40B model, the advantage is that you can run it on a 48GB+ GPU without incurring any expenses. However, it’s important to note that Falcon-7B performs approximately 20 percentage points lower than the 40B model, so it’s a case of getting what you pay for.
To run the 7B model, you can utilize the provided demo code, which will serve as a starting point for your endeavors. It’s important to ensure that PyTorch 2.0 is installed, as Falcon requires this version to operate successfully.
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
# model = "tiiuae/falcon-40b"
model = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"""Falcon is a magestic animal who can swim under water and fly to generate rainbows.\n
Author: Hello, Girafatron!\n
Flacon:""",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Fine-tuning
Falcon-40B is a versatile foundation model that isn’t designed for a specific purpose. To make the most of this model, you’ll need to train it using relevant data. Zero-shot involves using the model as-is without any specific tuning, while few-shot tuning involves fine-tuning based on a small number of examples.
There are other exciting possibilities like conversational fine-tuning or instruct tuning. You can utilize publicly available fine-tuning datasets to further customize the model according to your requirements. To get started, check out an article that provides insights on what it entails to fine-tune a foundation model. While it may require a GPU with ample memory and finding the appropriate template for fine-tuning a decoder-only architecture model, it’s definitely worth giving it a try. Don’t worry, it shouldn’t be too challenging once you dive in!
Do We Need Other Models?
Exciting developments are taking place with models like LLaMA, Falcon, and MPT. They’re demonstrating that they can generate satisfactory outputs without the need for massive models. Falcon-40, in particular, is a notable achievement as it is released under a completely OpenSource License. This signifies a shift towards democratizing technology, making it accessible beyond the control of a few large organizations. However, there is a downside: this accessibility also extends to malicious actors who can misuse these foundation models, posing challenges for regulatory oversight when it comes to identifying fake text.
On a positive note, these models challenge the notion that the size of a model solely determines its usefulness. In simpler terms, the utility of a model doesn’t always scale linearly with its size. Smaller, faster, and more democratic models have the potential to facilitate better knowledge dissemination compared to relying on a few massive models. It highlights the idea that there are diminishing returns in terms of training and inference costs associated with larger models.
If you haven’t done so yet, take a look at DistilBert and distilGPT! They follow a clever idea of retaining essential model information while removing unnecessary neurons, just like a distillery. These models prioritize speed, size, affordability, and efficiency, while still delivering comparable performance to their larger counterparts. It’s all about creating faster, smaller, cheaper, and lighter models that can get the job done just as well. You can find more information about them at the links provided.
Conclusion
The emergence of models like Falcon, DistilBert, and distilGPT signifies a significant shift in the field of AI language models. These models showcase the power of data refinement techniques, fine-tuning, and model compression to create faster, smaller, and more efficient models without compromising performance. Falcon, in particular, stands out with its impressive scalability and data-cleaning approaches. By open-sourcing a subset of their extensive dataset, the team behind Falcon has contributed to the democratization of AI technology.
As we venture further into this era of advanced language models, it is essential to continue exploring innovative approaches, pushing the boundaries of model compression, fine-tuning, and democratization. By harnessing the power of these models responsibly, we can unlock new possibilities for natural language understanding, and generation, and ultimately enhance human-machine interactions in a wide range of applications.
For more interesting and exciting blogs, stay tuned!
Follow me: M. Haseeb Hassan
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

