



Exponential Smoothing for Balancing Multilingual Model Training Data
Last Updated on July 17, 2023 by Editorial Team
Author(s): Deepanjan Kundu
Originally published on Towards AI.
What is a multilingual model?
Machine learning models that cover more than one language are called multilingual models. Since languages differ significantly from each other in script, vocabulary, grammar, and writing styles, in the early days of NLP, each language used to be dealt with separately. Each language used to have its own separate model. A single model hosting separate languages was not the recommended approach. Prior methods for multilingual (and monolingual) understanding relied upon specialized linguistic approaches.
But since the advent of transformers, multilingual models have become a staple. Joint pre-training across multiple languages led to noticeable performance benefits, where classification tasks in low-resource languages saw the largest boost. Such results revealed that multilingual pre-training facilitates positive inductive transfer — training on many languages at once is actually better than training separate models for each language. A single multilingual model for all languages has become the norm.
Challenges with low-resource languages
Most practical use cases have one set of languages with more data. For example, products like YouTube Comments have a high amount of English data compared to Hindi. This translates to an uneven distribution. When we train a multilingual model directly on this data, there is a performance compromise that we need to make between these languages. Languages with more data perform much better than languages with less data. This affects the tail performance of the model in live traffic.
To fix the tail performance issues, we can have the same amount of data for all languages. But this would significantly reduce the model’s performance for the most prevalent languages. Hence, we need to balance the distribution of data for low-resource languages such that the performance of the model is improved significantly for tail languages with minimal impact on the performance of the most prevalent languages. Exponential smoothing is an approach that helps create this necessary balance between languages in training data.
How is exponential smoothing used for sampling?
Each data point is usually assigned a probability of being sampled for training data. In random sampling, each data point would have an equal probability, which would mean that at per language level, the under-represented languages would have a lower probability.
We will change this system a little bit. We will assign a probability to each language and sample a portion of data from a single language in the training data according to the new probability. To mitigate the impact of the imbalance discussed in the sections above, the probability of each language is exponentially smoothed as follows:
- Take the probability of each language based on random sampling.
2. Exponentiate this probability by a smoothing factor ‘s’, a float between 0 and 1.

3. Based on these exponentiated probabilities, re-normalize each language’s likelihood.

These new probabilities describe the probability of each language in the new smoothed dataset. When sampling data from each language, you would need to remap these probabilities to sample from within that language.
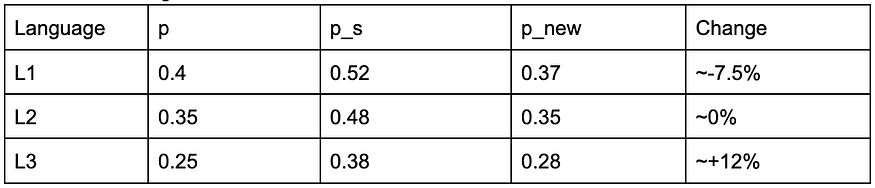
Let us look at an example. The following is the table with different languages.

Below, we can see how the distribution across languages shifts after smoothing across the different languages in the dataset.

Does smoothing help with the balancing challenge?
For most languages, exponential smoothing would slightly tweak the sampling probabilities. It would slightly decrease the probability of sampling a high-resource language and slightly increase the probability of sampling a low-resource language. For extremely low resource languages (probability < 1%), this amplifies their probability of selection the most, increasing it many folds. While fixing the representation problem, it also ensures no significant drop in performances across the most prevalent languages while significantly improving the performance of low-resource languages.
Let us understand the effect based on a few examples:
Scenario 1
An increasing sampling of low resource language L3 multiple folds. We will use a smoothing factor of 0.5.

Scenario 2
Slightly tweaking low resource languages and slightly tweaking high resource languages. We will use smoothing factor of 0.7
Conclusion
Outside of NLP models, models that are built for multiple locales of users, also called multi-locale models, can benefit from exponential smoothing for sampling from different locales. Handling multiple languages and locales is a necessity with more and more products going global. This article summarizes one of the most commonly used language balancing techniques used in NLP tasks. This technique is, in fact, also used in the multilingual BERT model pre-training as well. These principles will give you peace of mind that your training data is well-balanced for the development of multilingual models.
References
- Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
- https://en.wikipedia.org/wiki/Exponential_smoothing
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")