


Enhancing E-commerce Product Search Using LLMs
Last Updated on August 11, 2023 by Editorial Team
Author(s): Hang Yu
Originally published on Towards AI.
Applying LLMs to make E-commerce search engines robust to colloquial queries
In recent years, web search engines have been quickly embracing Large Language Models (LLMs) to increase their search capability. One of the most successful examples is Google search powered by BERT [1]. Comparatively, many E-commerce platforms are relatively more conservative in applying this emerging technique in their product search. In this article, I will demonstrate how LLMs can be applied to benefit the understanding capability of E-commerce product search when it encounters search queries that are colloquial and implicit.
Problem Statement
Despite the pioneers like Amazon [2], many E-commerce platforms are still heavily relying on traditional retrieval techniques like TFIDF and BM25 for product search. Such sparse methods usually require customers to type explicit queries that match the product information and mostly struggle to achieve good relevance for queries that are colloquial and implicit. In consequence, the search engine either returns no result or results with low relevance ignoring the existence of the relevant ones, which harms the customer experience and business metrics.
For instance, Ebay is returning “No exact matches found” for the query “What are the best gifts for boys under 5?”. Although the “Results matching fewer words” solution avoids the “no result” situation, its search relevance has got the obvious potential to be improved.

People might argue that it’s rare for such queries to occur. However, it’s not uncommon that many opportunities and advancements are actually driven by the use cases that are underestimated in the beginning.
LLM-based Solution
Today, thanks to the fast development of LLMs, one can quickly build prototypes without worrying about the effort needed to build in-house solutions from scratch. This enables my quick discovery to tackle the problem.
As depicted in the image below, the idea is pretty straightforward. The LLM is leveraged to translate the raw query to an enhanced query that aims to contain the explicit product information for search. Potentially, the product range covered in the enhanced query could be broad for the raw query that is implicit and fuzzy. In consequence, sending the enhanced query directly to the keyword-based search engine will likely lead to poor results due to its ambiguity and uncertainty. As a solution, LLM embedding is adopted to address the semantic complexity. Specifically, the enhanced query is projected into the embedding space that contains the preprocessed product embeddings. Next, the product retrieval is done by comparing the similarity between the query embedding and product embeddings, which then generates the top-k products as search results.
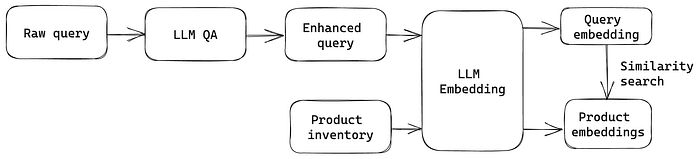
There is a wide range of techniques to implement the idea as there exist many options for each step. Here, I provide one example implementation based on Hugging Face and LangChain. The actual code is hosted on the Github repo below, with the details explained as follows.
ML_experiments/LLM_search_exp.ipynb at main · simon19891101/ML_experiments
Contribute to simon19891101/ML_experiments development by creating an account on GitHub.
github.com
Generate the enhanced query
First, the recently announced Llama 2 is adopted as the LLM to generate the enhanced query for a given raw query. As demonstrated below, the Hugging Face pipeline is used, considering its simplicity. It’s worth noting that the pipeline itself is enough to accomplish the task so the use of LangChain is totally optional. The prompt template adopted here aims to generate relevant and diverse product names to address the fuzziness of the raw query.
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model, use_auth_token=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
do_sample=False,
top_k=1,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200
)
from langchain.llms import HuggingFacePipeline
from langchain import PromptTemplate, LLMChain
template='''[INST] <>
Only tell me the product names. The answer should only include ten names.
<>
{prompt}[/INST]'''
prompt_template = PromptTemplate(template=template, input_variables=["prompt"])
llm = HuggingFacePipeline(pipeline=pipeline)
llm_chain = LLMChain(prompt=prompt_template, llm=llm)
Create product embeddings
Next, the sentence transformer and FAISS in LangChain are used to create and store the product embeddings based on the product titles in the inventory. Here, due to the lack of access to actual search engines, the offline Ebay product dataset “products.csv” is adopted as the mockup of the E-commerce product inventory. This dataset contains approximately 3,000 products covering a wide range of categories.
Ebay UK products dataset — dataset by opensnippets
Ebay UK e-commerce products free dataset
data.world
import pandas as pd
products = pd.read_csv('products.csv', usecols=['name'])
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name='sentence-transformers/all-MiniLM-L6-v2',
model_kwargs={'device': 'cpu'})
product_names = products['name'].values.astype(str)
product_embeddings = FAISS.from_texts(product_names, embeddings)
Product retrieval
When it comes to retrieval, the same sentence transformer model that encodes the products is used again to generate the query embedding for the enhanced query. Finally, the top-10 products are retrieved based on the similarity between the query embedding and product embeddings.
raw_query = 'example query'
enhanced_query = llm_chain.run(raw_query)
product_embeddings.similarity_search_with_score(enhanced_query, k=10)
Showcase
To demonstrate the effectiveness of this approach, let’s look at the above-mentioned query “What are the best gifts for boys under 5?” and compare the LLM enhancement with the original Ebay search results presented in Figure 1.
First, after receiving the raw query, Llama 2 generates 10 products as instructed by the prompt template. They look pretty impressive for boys’ gift ideas although a better product-level granularity is expected.

Next, let’s have a look at the similarity match in the embedding space. What are retrieved from the product inventory mockup are not bad at all in comparison with the results of the real-world Ebay search engine in Figure 1. Due to the limited product range of the inventory mockup, the comparison is somewhat unfair but we are still able to observe the significant difference before and after applying LLM. Overall, the retrieval in embedding space achieves both relevance and diversity.

Final thoughts
After conducting the initial discovery, it is obvious that LLMs are a powerful tool to enhance the product search of E-commerce platforms. For this task, there are many future explorations to conduct, including prompt engineering for generating queries, product embeddings with enriched attributes, online latency optimization for LLM query enhancement, etc. Hope this blog could inspire the E-commerce platforms that need solutions to improve product search.
References
[1] Nayak, P. (2019) Understanding searches better than ever before, Google. Available at: https://blog.google/products/search/search-language-understanding-bert/ (Accessed: 09 August 2023).
[2] Muhamed, A. et al. (no date) Web-scale semantic product search with large language models, Amazon Science. Available at: https://www.amazon.science/publications/web-scale-semantic-product-search-with-large-language-models (Accessed: 09 August 2023).
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

