



Density-Based Clustering Algorithm from Scratch in Julia
Last Updated on July 25, 2023 by Editorial Team
Author(s): Jose D. Hernandez-Betancur
Originally published on Towards AI.
Let’s code in Julia as a Python alternative in data science
1. Introduction
Julia is a strong and dynamic programming language that, in the last few years, has increased its popularity in the data science (DS) and machine learning (ML) fields. Several DS and ML practitioners believe Julia will become the predominant language for DS. The reason is that Julia combined the flexibility and dynamism of interpreted programming languages like Python, the statistical power of R, and the performance and efficiency of compiled languages like C++ and Fortran. The above criteria make Julia an outstanding alternative for scientific computing.
I have hands-on experience, mainly with Python. My experience with Python ranges from data analysis to ML to web development. As a lifelong learner, I didn’t hesitate, and I started learning Julia so that I could have it in my DS and ML toolkit. I think that the best way to learn any programming language is by coding, coding, and coding. Thus, one can explore the documentation and, through debugging and error handling, excel at the different scenarios that may present themselves during scripting. Thus, by fostering Julia, I will write one of the state-of-the-art algorithms in DS for clustering, DBSCAN, which stands for Density-Based Clustering Algorithm.
If, after reading this post, I encourage you to explore Julia, you can find the link just below U+1F447.
The Julia Programming Language
Watch what unfolded at JuliaCon 2022 here. The latest developments, optimizations, and features happen right here, at…
julialang.org
2. Why Julia?
Julia is a great language for DS and ML. Just-in-time (JIT) compilation allows Julia for high-performance execution comparable to languages like C++ or Fortran. In addition, Julia's clean and expressive syntax makes it easy to read and write, which is great for the maintainability and reproducibility of DS projects. Something great about Julia is that it can interact with other well-known DS languages like Python, R, and C++, facilitating the integration of existing libraries and tools like PySpark. By the multiple dispatch feature, Julia’s functions can have different implementations based on the types and/or number of arguments provided (see the post by
Emma Boudreau about Multiple Dispatch in Julia).
Why Multiple Dispatch Is My Favorite Way To Program
An overview of the advantages of multiple dispatch, and why I love it so much.
towardsdatascience.com
Julia also offers built-in features for parallelism and distributed computing. Through multi-threading, the programs written in Julia can horizontally scale across multiple processors and machines, facilitating large-scale data analysis and ML tasks. Last but not least, Julia has a growing ecosystem of packages developed by several people.
Julia Ecosystems
Julia has a wide ecosystem of packages, maintained by a wide variety of people. In the best of academic ideals, Julia…
juliakorea.github.io
Using the package manager namedPkg, the installation and management of Julia packages are straightforward. Below, you can see the important libraries in Python and their corresponding libraries in Julia.
3. Overview of DBSCAN
Before exploring the implementation of DBSCAN in Julia from scratch, it is important to clarify the general idea behind this algorithm. For this post, I will provide the important concepts so that the Julia program works properly. If you would like to dive in, check the below paper U+1F447.
DBCAN is a density-based clustering algorithm, i.e., it analyzes the density of points in the dataset to identify clusters and noisy points.
3.1. General Uses
DBSCAN is an algorithm mainly used for clustering tasks and analysis. DBSCAN is also used to identify or detect outliers in datasets as part of the preprocessing stage in ML to enable filtering noise points that do not conform to the dense regions of datasets. It can also help perform spatial data analysis on geographical or location-based data, allowing for the detection of high data concentrations. In addition, if the goal is to detect anomalies, DBSCAN can help identify abnormal or potentially fraudulent behaviors. By grouping together similar-characteristic pixels, DBSCAN can be used for image segmentation in a high-dimensional feature space. In marketing and customer analytics, DBSCAN can aim at segmenting customers for business decision-making.
3.2. Important Concepts
Some concepts are important to successfully grasping DBSCAN implementation:
- ε: This is a hyperparameter that represents the maximum distance between two points so that they can be considered neighbors, i.e., ε is a distance-based threshold.
- MinPts: This is another hyperparameter representing the minimum number of points that are required to form or consider a dense region.
- Core points: If point A has at least MinPts points within ε (including itself), DBSCAN considers it a core point.
- Density-Reachable: Point A is density-reachable from a point B as long as there is a path of core points leading from B to A. Density-reachable points can be parts of the same cluster.
- Density-Connected: Two points A and B are density-connected if there is a core point C from which both A and B are density-reachable. Density-connected points belong to the same cluster.
- Expansion of Clusters: DBSCAN expands the clusters by finding density-reachable points starting from the center points and recursively expanding the clusters from there. It adds these points to the cluster until it finds no more density-reachable points.
- Noise Points: These points are neither core points nor density-reachable, i.e., they do not belong to any cluster.

The above figure depicts the basic concepts underlying DBSCAN that are important for its understanding and implementation in Julia. The picture shows an example with MinPts points equal to 4.
3.3. General Algorithm
The figure below depicts the DBSCAN clustering procedure. The procedure steps are the following:
- Step 1: Although the figure does not show it, ε and MinPts should be selected before starting the procedure. These are hyperparameters that a DS or ML practitioner has to tune after selecting an ML algorithm for representing its problem.

- Step 2: DBSCAN starts all the points x ∈ X (the training dataset) as unvisited.
- Step 3: DBSCAN marks the unvisited point x as visited and looks for its neighbors (i.e., N in the figure), considering ε. For the distance function, one can use, for example, Euclidean distance, Manhattan distance, Cosine distance, Hamming distance, Minkowski distance, or Jaccard Distance.
- Step 4: If the number of neighbors is greater than or equal to MinPts, x is made a core point and added to the cluster (i.e., x belongs to the set C); otherwise, DBSCAN marks x as a noise point.
- Step 5: The x’ ∈ N are explored. If x’ has not been visited, then it is marked as visited, and their neighbors (i.e., N’) are identified.
- Step 6: If N’ is greater than or equal to MinPts, DBSCAN adds the core point to the cluster and recursively expands from there (i.e., N ← N ∪ N’).
- Step 7: If x’ is not yet a member of any cluster, DBSCAN adds it to C (i.e., C ← C ∪ {x’}).
4. DBSCAN Implementation in Julia
The installation of Julia is beyond this post. You can explore the following references:
- For installation on any platform (e.g., Linux), check the following link:
Platform Specific Instructions for Official Binaries
The official website for the Julia Language. Julia is a language that is fast, dynamic, easy to use, and open source…
julialang.org
- For working with Jupyter notebooks, check out the following Medium post written by Dr Martin McGovern PhD FIA:
How to Best Use Julia with Jupyter
How to add Julia code to your Jupyter notebooks and also enable you to use Python and Julia simultaneously in the same…
towardsdatascience.com
For implementing DBSCAN in Julia, we will use LinearAlgebra , Plots, Random packages: Make sure they are in your environment. In case they are not, use Pkg:
using Pkg
Pkg.add("PackageName")
# or Pkg.add(["PackageName1", "PackageName2"])
Once you have both Julia and the required packages, you can write the following code with the DBSCAN implementation in Julia:
The above code snippet comprises four functions that are briefly explained below:
- The
euclidean_distancefunction calculates the Euclidean distance between two points using thenormfunction from theLinearAlgebrapackage. - The
region_queryfunction finds the neighbors of a given point within a specified distance threshold (epsilon). It iterates over all points in the dataset (data) and checks if the distance between the current point and the specified point (point_index) is less than or equal toepsilon. If it is, the point is considered a neighbor, and its index is added to theneighborsarray. - The
expand_clusterfunction expands a cluster by assigning cluster labels to points in the neighborhood of a core point. It starts by assigning the cluster label (cluster_id) to the core point (point_index). Then, it iterates over the neighbors of the core point and assigns the cluster label to each neighbor if it is currently labeled as noise or undefined. If a neighbor is undefined, it is recursively expanded by finding its neighbors and adding them to theneighborsarray. - The
dbscanfunction performs the DBSCAN algorithm on the given data. It initializes an array of cluster labels (cluster_labels) with zeros and iterates over each data point. If a point is not assigned to any cluster, it finds its neighbors using theregion_queryfunction. If the number of neighbors is less thanmin_pts, the point is marked as noise (-1). Otherwise, a new cluster is created, and theexpand_clusterfunction is called to expand the cluster.
For testing the code, we generated four synthetic clusters. We generated the clusters using random numbers from a standard normal distribution. ε = 2.0, and MinPts = 2. You can change the parameter values to explore different results.
Note that compared to Python, Julia has several similarities, transitioning from Python to Julia easier. For commenting the Julia functions is possible to use docstrings, but normally the comments are before the functions unlike Python. Unlike Python, the indexes in Julia are 1-based, i.e., the first element of an array has an index of 1. This differs from Python, where array indexes are 0-based.
Now, for running the code in a terminal or command line, save the dbscan_julia.jl file. Navigate to the directory or folder where you saved it. Now, like in Python, run the following command in your terminal:
julia dbscan_julia.jl
As mentioned earlier, you can use Julia notebooks in order to run your code iteratively, as normal in an exploratory stage or as a concept proof in DS and ML projects.
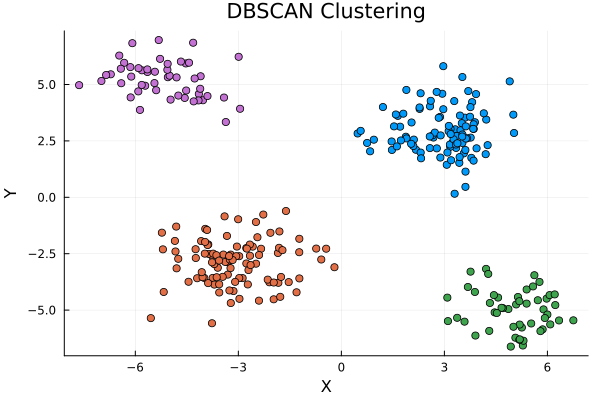
The above figure shows the four clusters generated using DBSCAN, which correspond to the four expected clusters generated using normally distributed random numbers. You can play with the two hyperparameters (i.e., ε and MinPts) in order to explore how the results change. Also, you can explore the built-in implementation of DBSCAN in Julia:
DBSCAN
Density-based Spatial Clustering of Applications with Noise (DBSCAN) is a data clustering algorithm that finds clusters…
juliastats.org
The above implementation includes an additional parameter that is not part of the vanilla DBSCAN: min_cluster_size . This parameter establishes the minimum size for a cluster, ensuring that only clusters with at least that value are considered. Thus, if min_cluster_size is too large, it may lead to underfitting, while if it is set too small, it can lead to overfitting.
Conclusion
Julia is a promising alternative to Python for DS and ML applications. We observed that Julia’s continuous adoption growth is a result of the overlap between R’s statistical computing capability, Python’s clear and expressive syntax, and high-performance compiled languages such as C++ and Fortran. In addition, we verified that Julia supports parallel computation for horizontally scalable ML projects and that its multiple dispatch feature enables Julia to utilize functions in various ways based on the parameter types and numbers. In addition, we investigate Julia by constructing DBSCAN from scratch, one of the most popular unsupervised learning algorithms for clustering. With the DBSCAN implementation, we could see how similar Julia is to Python, facilitating the transition of ML and DS practitioners from Python to Julia or even interoperability between the two.
If you enjoy my posts, follow me on Medium to stay tuned for more thought-provoking content, clap this publication U+1F44F, and share this material with your colleagues U+1F680…
Get an email whenever Jose D. Hernandez-Betancur publishes.
Get an email whenever Jose D. Hernandez-Betancur publishes. Connect with Jose if you enjoy the content he creates! U+1F680…
medium.com

Suggested Material
- Julia vs Python — Which Should You Learn?https://www.datacamp.com/blog/julia-vs-python-which-to-learn
- Clustering with DBSCAN, Clearly Explained!!! https://www.youtube.com/watch?v=RDZUdRSDOok
- Julia Scientific Programming https://www.coursera.org/learn/julia-programming
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

