



Demystifying Information Extraction using LLM
Last Updated on January 5, 2024 by Editorial Team
Author(s): Aditya Mohan
Originally published on Towards AI.
Information extraction is the process of automating the retrieval of specific information related to a specific topic from a collection of texts or documents. This generally involves the use of natural language processing techniques. Using natural language processing to extract information often results in building complex logic that is sometimes very specific and does not generalize well.
Okay… but what complex logic are we talking about?
Complex logic can invlove techniques like trying to design modules that would parse a certain types of documents. One would have to go through a number of documents to get a general understanding of the layout and then try to come up with modules that relied on key-value pair extraction from OCR services like AWS Textract, or designing extraction logic based on natural language using complex regular expressions or just simply searching in the spatial locality of certain keywords for their corresponding values. These approaches though successful are not very immune to changes in document structure.
With the advent of large language models (LLM) that are trained on a corpus of millions of documents and texts, it has become considerably easier to solve this problem. Large language models can easily extract information regarding attributes given a context and a schema. In most simple cases, they do not require additional fine-tuning for the task and can generalize well. The kinds of documents that can be better analyzed with LLMs are resumes, legal contracts, leases, newspaper articles, and other documents with unstructured text.
Further, to democratize access to LLM capabilities, OpenAI has made APIs available that can be used to generate results from their LLM products like GPT 3.5 and GPT 4.
In this article, I will talk about what a very basic information extraction pipeline might look like and how, using modern Python frameworks like LangChain and Streamlit, one can easily build web applications around LLMs.
Methodology
Optical Character Recognition
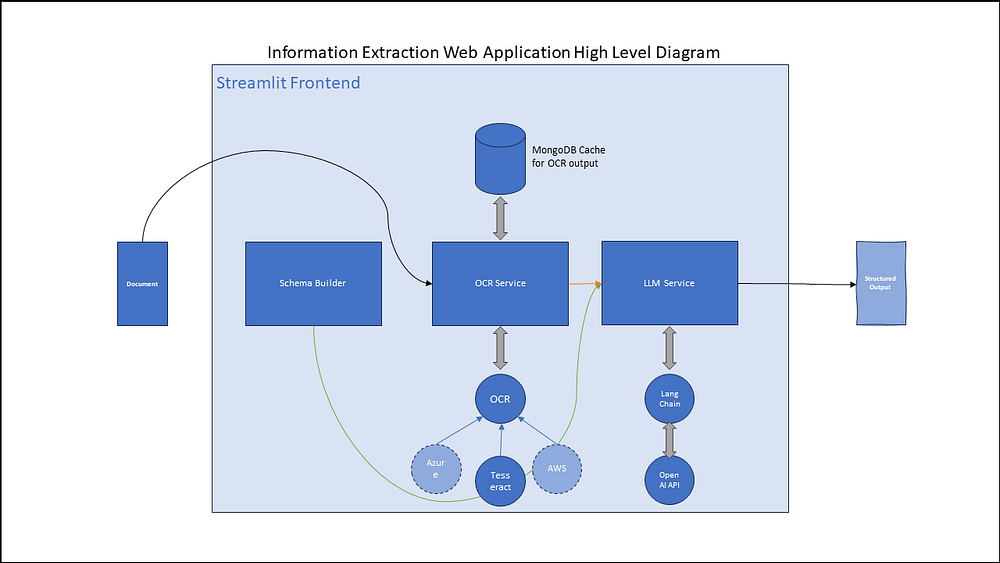
Extracting text in a machine-readable format from an image is called Optical Character Recognition (OCR). The first step in any information extraction product or service is to extract the text from the document. The document can be a PDF file or scanned/captured images. Ultimately, the PDF is converted to a collection of images where each page is converted to a single image. Therefore, the OCR model works with only images natively.
There are many paid and open-source OCR services available. In this article, I use an open-source project called Tesseract to perform OCR and retrieve the text.
The OCR class in the project is a Python Protocol that can be extended to implement different paid OCR services like Tesseract, AWS Textract, Azure Vision APIs, etc.
Extending OCR with Tesseract
Likewise, the same OCR Protocol can be extended to implement other classes for OCR products like AWS Textract and Azure Vision.
LangChain Extraction and Schema Builder
Schema Builder
To get a structured output from the LLM. A schema is a collection of properties. The schema will output the results in the format provided. Each property in the schema has three attributes that need to be defined: name of the property, type of the property, and whether the property is required or not.
Once the schema is built, it can be used to generate a structured output from the LLM.
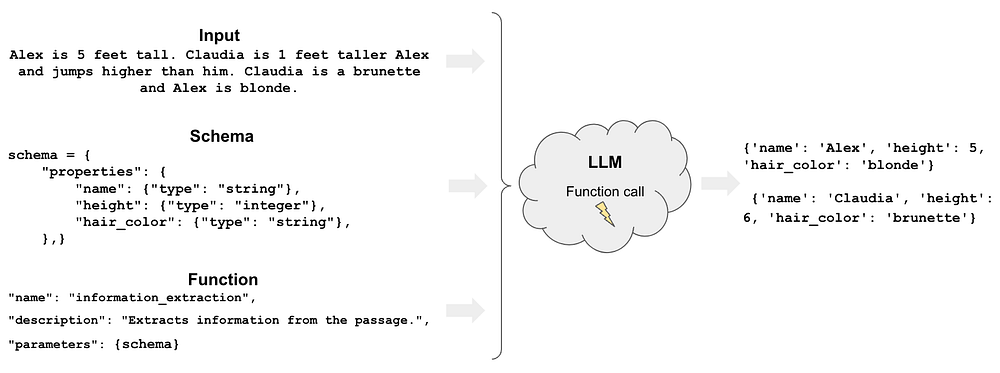
In the above image, the input acts as a context for the LLM. The schema provides the format in which the output is to be formatted and also specifies the fields required to be extracted and their corresponding data types. The possible data types supported by LangChain are “string” and “integer”. Once we have the context and the schema, these can be fed to the LLM to generate the response.
LangChain
LangChain is a framework for developing applications that harness the power of language models. It enables applications that:
- Are context-aware
- Reason
In this article, functions in LangChain that are related to Extraction have been used. It can be used to get structured model output with a specified schema.
So, the pipeline is something like this, we get the text in a machine-readable format from the OCR module, and we also build the schema to specify the structure of our output.
The text output by the OCR is the context, and the schema builder helps prepare the schema in the required format. Once we have both of these, then we use the create_extraction_chain function from LangChain to generate the output.
Streamlit Frontend
What is Streamlit?
All machine learning applications require an interactive web application that can make it easier to present their results and performance. Streamlit is a free, open-source, all-python framework that enables data scientists to quickly build interactive dashboards and machine learning web apps with no front-end web development experience required.
Just to showcase how easy it is to build interactive apps with Streamlit and Langchain, here is a code snippet and the generated web app.

Do try out more examples of Streamlit apps on your data and read their documentation and tutorials to learn more. This entire information extraction application was designed using Streamlit!
Streamlit * A faster way to build and share data apps
Streamlit is an open-source Python framework for machine learning and data science teams. Create interactive data apps…
streamlit.io
State Machine
So one thing to note about Streamlit is that whenever someone “interacts” with the app, the script is re-executed top to bottom. So here, interacting means clicking a button or moving the slider. Therefore, to build Streamlit applications that have multiple stages, it is beneficial to use a state design pattern while writing the code.

Above is the state diagram and the transitions that have been used throughout the code for this information extraction application. To obey the rules of the State Design Pattern a Python package called Transitions has been used which provides a lightweight state machine implementation. But one can implement their own state machine as well.
The App
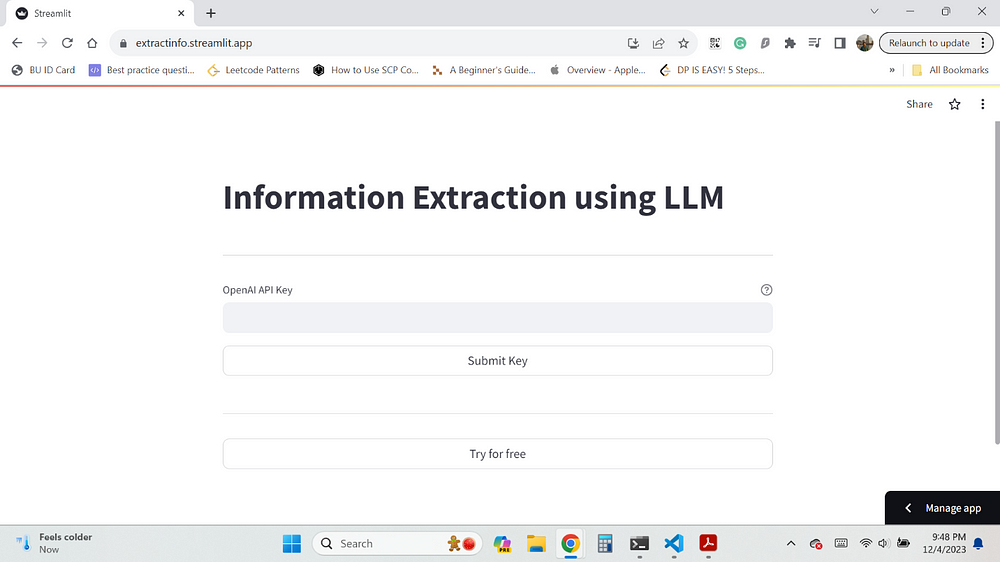
Welcome Screen
Prompting you to enter the OpenAPI key to proceed further. I also provide a functionality to try for free up to five times.
File Upload Screen
Waiting to upload the files either images or PDFs to be uploaded. Multiple files can also be uploaded. The application supports JPG, PNG, and PDF file formats.

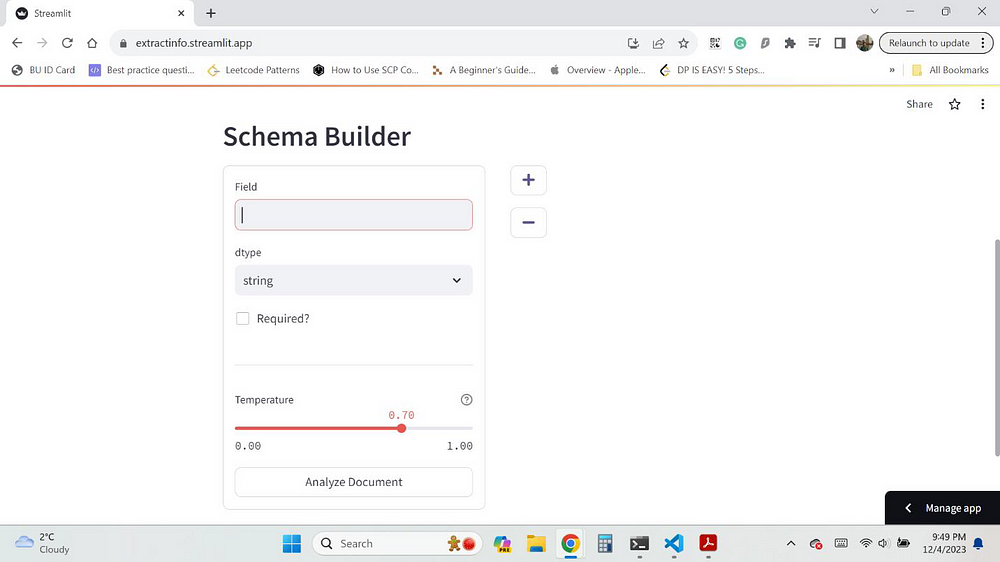
Schema Builder Screen
Here, the schema can be built to receive the structured output from the OpenAI extraction API.
LLM Output Screen
The final output screen displays the output from the extraction API as a data frame. Each file uploaded is analyzed and its output is shown as a separate tab. The sidebar also shows the original schema, and it can be changed to re-analyze all the documents.
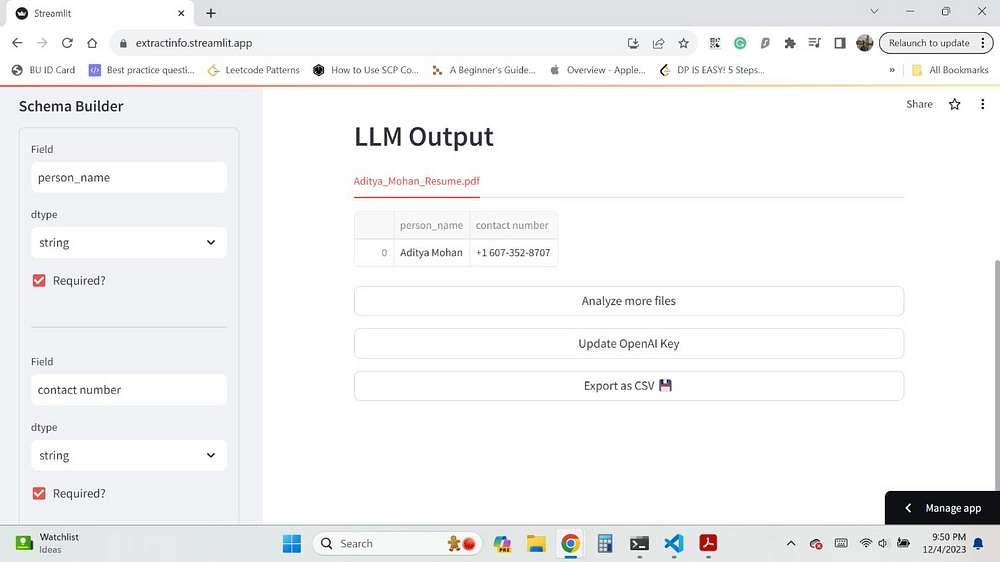
So, in this example, I upload my resume as the document to be analyzed by the system. Since my resume contains my name, address, and other contact details. Therefore, to extract them, I specified the fields “person name” and “contact number” to be extracted during the Schema Builder stage.
So, as you can see in the LLM output screen, the columns of the data frame are the fields I specified, and the values are the ones output by the OpenAI LLM.
GitHub Repos
Here, I’ve included the links to the two repositories containing this application's code. I created an OCR API using Flask and a separate Streamlit App repository.
OCR Repo — https://github.com/mohan-aditya05/text_analysis_ocr_service
App Repo — https://github.com/mohanbing/st_doc_ext
Conclusion
This application effectively showcases the power of large language models and how they can generalize well on different documents. The information extraction task has been made quite easy with the help of LLMs. Also, using Streamlit, one can easily develop a very modern-looking frontend with just the knowledge of Python and no prior frontend experience. It is the perfect framework for building proof-of-concept and small applications around a machine-learning model.
CAUTION!!!
It is not prudent to think that just using LLM will help you conquer all information extraction problems. LLMs like ChatGPT are meant to understand the natural language. They might not work well with documents that contain only key-value pairs or tabular information with no real linguistic relationship between different tokens. For processing these kinds of documents, it still might be better to use other traditional information extraction techniques. However, with the arrival of GPT 4, which supports vision, this problem might be solved as well.
References
- https://python.langchain.com/docs/get_started/introduction
- https://streamlit.io/
- https://github.com/tesseract-ocr/tesseract
- https://mermaid.js.org/
- https://platform.openai.com/docs/models
- https://flask.palletsprojects.com/en/3.0.x/
- https://www.mongodb.com/
- https://www.digitalocean.com/products/droplets
- https://github.com/pytransitions/transitions
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


