



Deep Learning Applied to Physics and Fluids
Last Updated on November 6, 2023 by Editorial Team
Author(s): Eduardo Vitalbrasil
Originally published on Towards AI.
Numerical simulations have been used for years to understand the behavior of physical systems; how the fluids interact with a structure, how a geometry is deformed under stress, or even the thermal distribution under heating conditions. Applied in the more diverse domains such as aero spatial, automobile, energy, etc., those calculations allow dimensioning prototypes and ensuring safe processes without having to build them. Notwithstanding, they can be computationally expensive and take many hours, days, or even weeks. That’s where Machine Learning, and specifically Deep Learning, shines, abbreviating the processing time to mere minutes!
Computational Fluid Dynamics simulations
A common numerical simulation can describe physical systems by solving a set of Partial Differential Equations (PDE), which typically have the form:
???? represent s the differential operator over the domain Ω ∈ ℝ , bounds ????Ω and parameters ???? . The solution ????(????, ????) of the system relies on spatial coordinates and time, with subscripts denoting partial derivatives. The set of equations can be solved by discretizing the physical domain into small parts (finite elements or finite volumes) to get a linearized system. This approach finds particular application in fluid dynamics.
In fluid dynamics, the system is represented mainly by the Navier-Stokes equations, a set of laws with no analytical resolution to describe the behavior of every fluid based on the mass and force balances. In a simpler 2D form, they can be described as:

Where ???? is the velocity along x-axis, ???? is the velocity in y, ???? is the pressure, ???? is the density and ???? is the viscosity.
Computational Fluid Dynamics (CFD) simulations consist of resolving the discretized linearized system along with its boundary conditions, such as the pressure and velocity at the limits of the domain, by iterative multigrid solution methods. Direct methods are impractical for real-world applications, where the inversion of the matrix for a 3D Cartesian and equally spaced grid (i³ elements) achieves i⁷ complexity.
Even with efficient solvers working in an HPC parallel environment, the computational cost of such operations can achieve long hours and become detrimental for a dynamic engineering process. The solution? As we see more and more, AI!
Surrogate models
When a possible input-output relationship is present, AI arises as a candidate to model such behavior. This scenario aligns perfectly with CFD, where the geometric setup, parametrized as a grid and its elements, in addition to the boundary conditions, can be linked to the output: the physical fields (pressure, velocity, etc.) in each point of the grid. The models built can act as meshless solvers which can replace traditional simulators with a lower computational cost.
In a general manner, we want to learn the mapping between the PDE parameters (????, ????, ????): ???? ∈ ℝⁿ and its solution ????(????, ????): ???? ∈ ℝⁿ . In other words, we aim to find the predictive function ????: (????, ????, ????) → ????(????, ????) where ???? is sometimes found to be constant (steady state analysis). Thus, we can imagine different ways to do that.
Simplified models
The easiest approach to model the relationship is to simplify it by reducing the dimensionality of the data. This method can be applied both to the input and the output. For instance, instead of using the full coordinates of grid points, we can represent the previously described geometry with a reduced set of parameters, denoted as ???? ∈ N U+007C ???? < n. A gear has a number of teeth, a primitive radius, a width, etc.
For the output, a viable choice is a global performance metric denoted as s(????) ∈ N. Examples are the forces acting on the prototype, the drag and lift coefficient, etc.
The upside of the simplifications is that it allows us to apply more basic and faster AI models. Even a linear/polynomial regression could be used with no bigger issues to learn the function ????: k → ????(k).
The downside is that, when reducing the dimensionality this way, there’s an intrinsic loss of information, and the models become less generalizable when facing data outside of the design space.
Volumetric models
Instead of reducing the dimensionality of the data, we can opt to work with the original volumetric grid (???? ∈ ℝⁿ), which introduces greater complexity and requires the utilization of Deep Learning techniques.
When dealing with an unstructured grid, a common approach involves interpolating it onto a uniform structured mesh. Essential features like freestream velocity and pressure can be embedded within each voxel, enabling corresponding predictions. Consequently, regions devoid of fluid are represented as null values, thereby encoding the geometry.
This voxel-based representation facilitates the use of a technique commonly employed in image recognition tasks: convolution. Convolutional Neural Networks (CNNs) can thus extract local and global features via their filtering approach. Varying scales of feature extraction can be achieved by integrating different stages, leading to increasingly intricate models, including u-nets and auto-encoders/decoders.
Instead of transforming the unordered data to the ordered shape of voxels/pictures, another solution involves actively encoding the coordinates. This permits data description in tabular format, where each point is associated with the corresponding simulation/example index. As we are going to see in the next section, this is what pytorch geometric does!
While it is theoretically plausible to train and apply a model to each point, this approach normally fails to capture inter-node relationships critical for determining local information. Enter Graph Neural Networks, constituting another class of models tailored to address this limitation.
Geometric models
In CFD we are often interested in determining the physical fields not in the volume but in the surface. This prompts a consideration of model-building strategies. While the voxelization method outlined earlier has shown promising results, its application to represent sparse point clouds corresponding to the geometry requires the creation of a uniform structured grid. However, this becomes impractical for intricate geometries, as it leads to either unnecessary computational costs due to encompassing irrelevant information around the shape, or a loss of valuable information due to a coarse grid.
A more efficient solution is offered by the field of Geometric Deep Learning, which is mostly known for its success in object recognition and semantic segmentation. This approach is closely linked to Graph Neural Networks and directly treats a Point Cloud — an unordered set of points — describing the data as a table of coordinates and indexes as we mentioned in the last section. Luckily, that’s exactly what we have with an unstructured mesh!
In order to do describe the data in such a format, we can use pytorch geometric, an extension of the state-of-the-art pythorch framework tailored for GNNS and geometric models. It also contains a series of graph datasets we can use, like AirfRANS⁴, a 2D NACA wings dataset for RANS simulations. Let’s briefly explore how this translates into actual code:
from torch_geometric.datasets import AirfRANS
from matplotlib import pyplot as plt
dataset = AirfRANS(root='/tmp/AirfRANS', task='full', train=True) # Downloads
example = dataset[0]
fig, ax = plt.subplots(figsize=(12,5))
ax.set_aspect('equal', adjustable="datalim")
# Scatters the Point Cloud using coordinates x, y and the Pressure as color
im = ax.scatter(*example.pos.T, s=0.5, c=example.y[:, 2])
fig.colorbar(im, ax=ax)
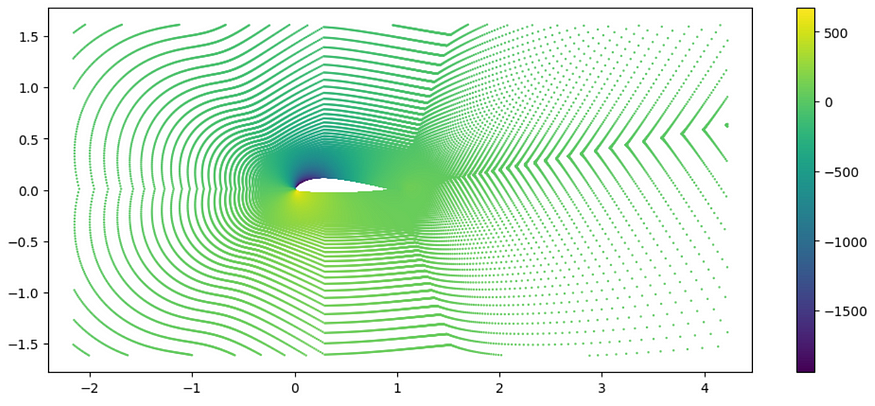
With a grasp of the dataset’s nature, the question arises: How can we train models using it? We transform it to the shape described above with a little help of Pytorch Geometric. The DataLoader allows us to loop through the dataset in mini-batchs thanks to the batch attribute, a vector that maps each node to its respective graph in the batch. . This proves crucial for employing aggregation functions in each simulation, as we’ll delve into shortly.
from torch_geometric.loader import DataLoader
# We are not differentiating train and test datasets, but only analysing the data
loader = DataLoader(dataset, batch_size=2) # Batch of 2 simulations
for data in loader: # Loops through the dataset, returning the batchs
print(data), print(data.batch)
break
>>> DataBatch(x=[351974, 5], y=[351974, 4], pos=[351974, 2], surf=[351974], name=[2], batch=[351974], ptr=[3])
>>> tensor([0, 0, 0, ..., 1, 1, 1])
Having established the data description, what types of models are suitable? Pytorch geometric offers a range of pre-designed neural layers and operations that can be very useful. One of the most traditional ones is, perhaps, PointNet¹. One of the pioneers of the field, this architecture proposed in 2017 introduced two major advantages that are until these days, very important.
The key to Pointnet’s success lies in its pooling operation. By condensing information of an entire simulation into a single vector, it captures global insights and enables the transition from multiple points to a singular global value. This effectively addresses the issue, for example, of applying a model to a single point and not being able to change the dimensions of the model. In other words, we’ll consider the dataset ???? = {Dᵢ U+007C i ∈ N, 1 ≤ i ≤ m}, m being the total number of simulations. We can define for each simulation Dᵢ the set of points X = {Xⱼ(pⱼ, fⱼ) U+007C j ∈ N , 1 ≤ i ≤ n}. The concatenated feature vector (pⱼ, fⱼ) ∈ ℝʰ U+007C h ∈ N. In this way, pooling performs the following transformation:

This is necessary for classification tasks where the Point Cloud should be reduced to a single value or vector. Another advantage of pooling is infusing global information into each point, useful in segmentation tasks. The global information vector can be concatenated to the feature vectors of each point, increasing its dimension. In this way, the model applied to each point will not only have its punctual information, but a general idea of the entire example. Formally, considering z as the total number of points in the unstructured dataset, the series of operations Pointnet architecture performs can be described, in a simplified way:


Where the same MLP is applied to each point/row and columns represent the features.
More complex models were proposed in the sequence. Pointnet++², for example, proposed the idea of using Pointnet at different hierarchy levels. This approach not only concatenates global features but also incorporates vectors representing smaller-scale phenomena. This proves particularly valuable when tackling CFD problems. For instance, in simulating an entire aircraft, distinct behaviors arise across different geometrical components. Wings exhibit different phenomena compared to turbines. Even on a finer scale, variations exist between the back and front of a wing, leading to characteristic pressure distributions.
Graph Neural Networks generalize the aforementioned concepts by dby depicting data as edges and vertices, reflecting relationships between nodes. In this way, it is equivalent to CNNs in a way that it aggregates local features but, instead of using a regular grid, it can be directly applied to an unordered set of points.
A typical GNN encodes a node as vertices (vⱼ = Xⱼ), having its coordinates as features. The edge represents the connectivity between nodes and encodes, for example, the distance between a specific one and its neighbors (or more complex formulas), e.g., E = {(vᵢ, vⱼ) U+007C ‖pᵢ, pⱼ‖₂ < r} being p the coordinates, v the neighbor's vertices i and j within a distance r.
Once this graph is computed, it undergoes iterative updates to propagate local information, generating non-linearity and increasingly complex embeddings. The more update steps are done, the more nodes acquire information from further reaches of the graph. Different graph architectures can be built by defining the update function, the number of updates, the way the graph is initially built, how the neighbors are computed, and many other possible intermediate procedures (for instance residual connections or even an attention mechanism). A simple updating procedure employs aggregating functions in a way:
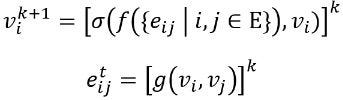
Where ???? is the aggregating function of a vertex in a neighborhood, updated by the non linear function ???? , and ???? the function to update the edges, like the Euclidian distance we defined above.
A generalizable model should also have the inductive characteristics of being invariant to rotation, translation, and permutation. A classic graph architecture is GraphSage³. Its light computational cost allows it to efficiently train on geometrical data with great success. It uses the formula above by specifying f as simple concatenating operation followed by a weight matrix multiplication with Wᵏ. Suggested aggregators, in its turn, are average or max pooling; while neighbors are uniformly sampled with fixed-size from the whole set.
Besides from the simpler models described, more complex and modern graph architectures have been developed in later years and are an promising field of research.
Represent the physics
Now that we have identified suitable models, the question arises: How can we effectively incorporate the unique characteristics of Physical Systems? One commonly used approach involves enforcing physical laws through soft constraints or penalization methods. Specifically, Physically Informed Neural Networks (PINNs) implement this strategy by penalizing the model using the residual of PDEs, thereby ensuring their accurate adherence. When referring to CFD, those are the Navier-Stokes equations. The partial derivatives in each equation can be computed from the model’s prediction by AD using the Deep Learning framework. Similarly, both Dirichlet and Neumann boundary conditions can be incorporated using the same methodology. Consequently, this approach leads to a refined format for the loss function:
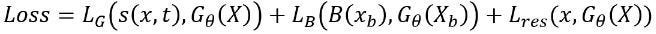
Where LG and LB represent, respectively, the loss of the data and the boundary conditions, constituting a supervised function with two arguments; Lᵣₑₛ is the residue function of the PDE; Xb and xb are the input data of the model and the PDE on boundary conditions points; B retrieves the boundary conditions values themselves; G???? is the forward function of the network with parameters ????.
Consequently, the model learns to respect both the pressure and velocity balance, and generalizes better to unseen data.
The loss expression highlights that PINNs can be used in a supervised approach, being data and physics driven. Notwithstanding, the LG term is optional, and the network can be trained in an unsupervised manner. This will have a much large space of solutions. As initial predictions are inherently random, optimizing the network proves challenging, and identifying an appropriate search objective remains an open question in Machine Learning. Various solutions can be imagined, from the alternative loss functions and optimization strategies to enforcing the boundary conditions by hard constraint, where a component of the network must directly meet the specified values.
High-frequency signals
Geometric Deep Learning models have encountered a challenge in terms of slow convergence and the struggle to learn high-frequency functions. This phenomenon is particularly prominent in fluid dynamics, especially when dealing with turbulent flows. To address this concern, the field of Implicit Neural Representations offers strategies that prove effective.
These transformations are rooted by the fact that deep networks are biased toward learning lower-frequency functions. Consequently, those techniques can be useful to improve the representation of higher frequency functions. An example is the expansion by Fourier features:

Employing this technique with Neural Networks facilitates learning high-frequency functions within low-dimensional problem domains like geometric contexts. Adjusting the frequency parameter allows for the manipulation of the spectrum of frequencies the model can grasp.
In practical terms, superior outcomes are achieved by setting aⱼ = 1 and selecting bⱼ from a random distribution. Fine-tuning can be performed on the standard deviation of this distribution, usually Gaussian. A broader distribution expedites convergence for high-frequency components, leading to improved results (notably in image-related tasks, resulting in higher definition). Conversely, an excessively wide distribution can introduce artifacts into the output (yielding a noisy image), presenting a trade-off between underfitting and overfitting.
A more modern approach can be achieved by using sinusoidal Representation Networks (SIRENs). They propose periodic activation functions in the form:
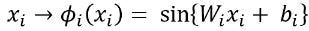
Beyond improving the high-frequency representation, SIRENs are also differentiable. That happens because the derivative of a SIREN is itself a SIREN, similar to how the derivative of the sine is a cosine: a phase-shifted sine. Not all common activation functions possess this quality; for instance, ReLU has a discontinuous derivative and zero second derivative throughout. Some other functions do present this desired capability, such as Softplus, Tanh, or ELU; however, its derivatives can be not well-behaved and fail to represent the fine details searched.
Therefore, they are well-suited to represent inverse problems, like the PDEs we are so interested in. Furthermore, SIRENs were proved to converge faster than other architectures.
To achieve the intended outcomes, an appropriate initialization scheme is essential. This initialization preserves the activation distribution throughout the network to ensure the final output remains independent of the number of layers. The solution lies in adopting a uniform initialization scheme in the following manner:
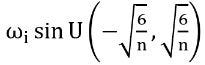
, so that the input to each unit is normally distributed with a standard deviation of 1. Moreover, the first layer of the network should span multiple periods over [-1, 1], which can be achieved using ω₀ = 30 in sin(ω₀ ⋅ ???????? + ????) ; this value should be changed depending on the modeled function frequency and the number of observations. The limitation of using a single frequency was later treated with the called Modulated SIRENs.
Conclusion
Hopefully, you now have a clearer understanding of how Deep Learning can create surrogate models for numerical simulations, even when dealing with unstructured and noisy data. Improving the network’s ability to generalize can be achieved through various techniques. These range from incorporating the physics of the underlying partial differential equations (PDEs) to using Implicit Neural Representation, among others we haven’t had a chance to explore. This dynamic research field is poised to expand significantly in the coming years as it becomes more reliable. Despite its name, this approach doesn’t seek to replace numerical simulations. Instead, it offers a quicker alternative that leverages simulations themselves and even experimental data. If we can combine fluid dynamics simulations, physical equations, and Deep Learning, why restrain to just one of them?
References
[1]: PointNet
C. R. Qi, H. Su, K. Mo, L. J. Guibas, PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation, arXiv:1612.00593 [cs]ArXiv: 1612.00593 (Apr. 2017). URL http://arxiv.org/abs/1612.00593
[2]: PointNet++
C. R. Qi, L. Yi, H. Su, L. J. Guibas, PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space, arXiv:1706.02413[cs] ArXiv: 1706.02413 (Jun. 2017). URL http://arxiv.org/abs/1706.02413
[3]: GraphSage
W. L. Hamilton, R. Ying, J. Leskovec, Inductive Representation Learning on Large Graphs, arXiv:1706.02216 [cs, stat]ArXiv: 1706.02216 (Sep. 2018). URL http://arxiv.org/abs/1706.02216
[4]: AirfRANS
F. Bonnet, A. J. Mazari, P. Cinnella, P. Gallinari, Airfrans: High fidelity computational fluid dynamics dataset for approximating reynolds averaged navier-stokes solutions (2023). arXiv:2212.07564.
[5]: Point-GNN
W. Shi, R. R. Rajkumar, Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud (2020) IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020): 1708–1716.
[6]: Scientific Machine Learning through Physics-Informed Neural Networks: Where we are and What’s next
S. Cuomo, V.S. Di Cola, F. Giampaolo, Scientific Machine Learning Through Physics–Informed Neural Networks: Where we are and What’s Next. J Sci Comput 92, 88 (2022). https://doi.org/10.1007/s10915-022-01939-z
[7]: Learning differentiable solvers for systems with hard constraints
G. Negiar, M.W. Mahoney, A.S. Krishnapriyan, Learning differentiable solvers for systems with hard constraints (2022). ArXiv, abs/2207.08675.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






