


Decoding Handwritten Digits: The Fascinating World of Machine Learning
Last Updated on April 12, 2023 by Editorial Team
Author(s): Surya Maddula
Originally published on Towards AI.
Images used in my articles are Properties of the Respective Organisations and are used here solely for Reference, Illustrative and Educational Purposes Only. [Images Source: Google (Aside from some images, in whose case, the source is mentioned explicitly below the image)
Introduction
What is Handwritten Digit Recognition?
Handwritten Digit Recognition is pretty self-explanatory, especially with the name; it is the process of classifying handwritten digits into their respective numerical values. Basically, if there’s an input of handwritten digits, we can convert them into their respective keyboard number.

This problem is a simple example of pattern recognition and is widely used in Image Processing and Machine Learning.
In this article, we will explore the concept of Handwritten Digit Recognition in detail, from its mathematical foundations to its implementation using code to its accuracy.

The Math Behind Handwritten Digit Recognition
The Math behind Handwritten Digit Recognition involves several procedures, which are —
- Image Processing
- Feature Extraction
- Classification.
Let’s explore each point in detail —
Image Processing
The first step in Handwritten Digit Recognition is to get an image of the handwritten digit.
This image is a 2D array of pixel values. Each pixel represents a small part of the image. Image processing techniques enhance the image quality to make it suitable for further processing. Some of these techniques include smoothing, edge detection, and thresholding.
Smoothing involves reducing the noise in the image. This can be done using a filter that averages the pixel values in a small radius around each pixel.
Using Edge Detection, we can identify the edges in the image. This can be done using techniques such as the Sobel Operator, which computes the gradient of the image.
Thresholding is another Image Processing Technique that divides the image into regions based on pixel values.
Ex: we can apply a threshold value such that all pixels with a value above the threshold are classified as foreground pixels (belonging to the digit). In contrast, all pixels with a value below the threshold are classified as background pixels (not belonging to the digit). Such are some of the use cases.
Feature Extraction
Feature Extraction is basically extracting relevant information from the pre-processed image that can be used for classification. This can include various aspects and features of the digit, such as shape, size, and orientation.
Global Features are features that describe the overall characteristics of the digit, such as its size, aspect ratio, and centroid location. On the other hand, local features describe the regional characteristics of the digit, such as the number of loops, corners, and endpoints in the numeral. Finally, texture features describe the texture of the digit, such as the presence of patterns, ridges, and lines.
Feature Extraction Techniques also include using mathematical operations such as Fourier Transform and Principal Component Analysis (PCA), which transform the image into a set of numerical features that we can use for classification.
Classification
In Classification, we use an ML Algorithm to classify the digit based on its features. The algorithm can be trained on a dataset of labeled digit images, which allows it to learn to recognize the patterns in the images.
Artificial Neural Networks (ANNs) are machine learning models that can be used for HDR. ANNs consist of layers of interconnected nodes, which process and transmit information. ANNs can be trained to recognize patterns in the numerical features extracted from digit images.
Support Vector Machines (SVMs) are another ML models that can be used for HDR. SVMs can be trained to separate the digit images into their respective numerical classes based on their features.
And Decision Trees are a type of machine learning model that uses a tree-like model of decisions and their possible consequences to predict the class labels.
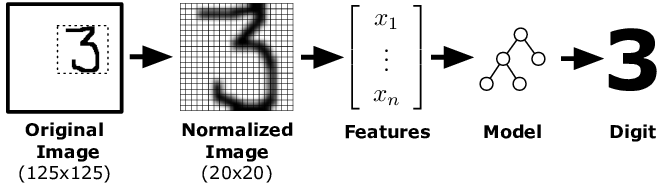
Pre-Processing Techniques for Handwritten Digit Recognition
Pre-processing is the first step in Handwritten Digit Recognition, which enhances the image quality and makes it suitable for further processing. Here are some pre-processing techniques.
Noise Reduction
While reducing noise, we remove random pixel value variations caused by lighting, scanner noise, or pen pressure. We can use techniques such as median filtering, Gaussian filtering, and wavelet de-noising to remove noise.
Contrast Enhancement
Contrast Enhancement involves increasing the contrast of the image to improve the visibility of the digit. We can use techniques such as histogram equalization, adaptive histogram equalization, and contrast stretching to enhance contrast.
Image Normalization
Image normalization involves standardizing the size and orientation of the image to reduce the variability in the digit images. This can include scaling, rotating, or translating the image to make it uniform.

The Modified National Institute of Standards and Technology (MNIST) Dataset.
What is the MNIST Dataset?
The MNIST Dataset is a widely-used benchmark dataset in Handwritten Digit Recognition. It consists of a collection of 70,000+ images of handwritten digits labeled with their corresponding numerical values. The dataset is divided into 60,000 training images and 10,000 testing images.
It was created in 1998 by Yann LeCun, Corinna Cortes, and Christopher J.C. Burges and has since become a standard benchmark for evaluating HDR algorithms. It is widely used in research and industry, leading to many advances in Pattern Recognition and Machine Learning.
It’s a set of images, with each image being 28 pixels wide and 28 pixels high. The images are centered in a fixed-size frame and normalized to have zero mean and unit variance. The pixel values range from 0 (black) to 255 (white) and are represented as integers.
As is any dataset, this dataset as well is divided into two parts: the training set and the test set. The training set consists of 60,000 images, while the test set consists of 10,000 images. The digits in the test set are from different writers than those in the training set, which ensures that the algorithms are tested on unseen data.
Implementation of Handwritten Digit Recognition
(I used jupyter notebook as my playground)
Now that we understand some basics about recognizing handwritten digits let’s implement them. We will use Python and the scikit-learn ML library.
First, Let’s import the necessary libraries for this —

Now, we’ll load the MNIST dataset —

Then, we’ll extract the specific features & labels from MNIST —

We split the dataset into training & testing datasets now —

Now, create an instance of the MLPClassifier class, which is an implementation of an ANN.

Then we train the model —

And finally, we evaluate the model based on its testing data —

And the Output —
(I put all the code above into one terminal for this one)
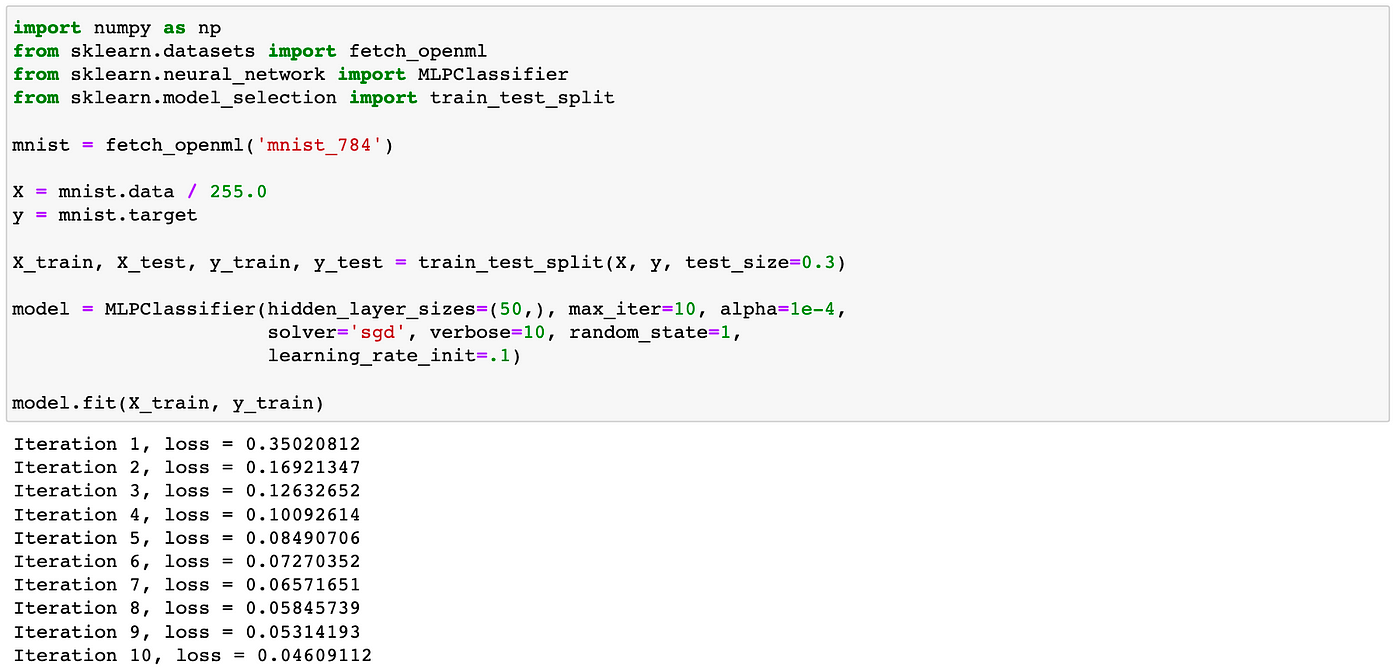
In the code snippet, the maximum number of iterations is specified by the max_iter parameter when creating an instance of the MLPClassifier. Since the value is 10 for max_iter, we got 10 iterations, as shown above. It means that the MLP classifier was able to converge to a solution within the maximum number of iterations allowed, which is 10 in this case.

We got the Accuracy here as 0.97. What is that?

What does Accuracy: 0.97014 mean?
It means that the model achieved an accuracy of 97%, which refers to the accuracy score obtained by the MLP classifier on the testing data. This means that the model was able to correctly predict the numerical value of 97% of the testing images.
Accuracy measures how well the model can correctly predict the numerical value of the testing images. It is calculated as the ratio of correctly classified instances to the total samples in the testing set. In this case, an accuracy score of 97% means that the model could accurately predict the numerical value of 97% of the testing images.
This level of accuracy is generally very good for Handwritten Digit Recognition. It indicates that the model can effectively learn the patterns and features of the handwritten digits input and make accurate predictions, hence the 97%.
Conclusion
In this article, we delved into Handwritten Digit Recognition, the process of identifying numerical values from handwritten digits. We began by defining the problem and its applications in image processing and machine learning. We then explored the mathematical foundations of Handwritten Digit Recognition, which involves using algorithms and statistical models to identify patterns and features in the numerical data.
We discussed the two main stages of the Handwritten Digit Recognition process: preprocessing and classification. Preprocessing involves transforming the raw image of a handwritten digit into a set of numerical features that can be used for classification. This is done using image normalization. Classification involves using a mathematical model or algorithm to determine the numerical value of the digit based on the extracted features.
We then explained how Handwritten Digit Recognition could be implemented using code. Specifically, we used Python and the scikit-learn ML library to load and preprocess the MNIST dataset of handwritten digit images. Next, we split the dataset into training and testing sets and then trained an MLP classifier on the training data. Finally, we evaluated the model’s performance on the testing data and got an accuracy of 97%, which means that the Model was able to correctly predict the numerical value of 97% of the testing images.
Notes —
I used Jupyter Notebook as my playground here, but feel free to use any other playground you’re comfortable with as well.
I’m also attaching my video explanation for the same project, so check that out if you feel like you want a detailed, step-by-step verbal description!
That’s it for this time; thanks for Reading and Happy Learning!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


