



Data Transformation and Feature Engineering: Exploring 6 Key MLOps Questions using AWS SageMaker
Last Updated on July 7, 2023 by Editorial Team
Author(s): Anirudh Mehta
Originally published on Towards AI.
This article is part of the AWS SageMaker series for exploration of ’31 Questions that Shape Fortune 500 ML Strategy’.
What?
The previous blog post, “Data Acquisition & Exploration: Exploring 5 Key MLOps Questions using AWS SageMaker”, explored how AWS SageMaker’s capabilities can help data scientists collaborate and accelerate data exploration and understanding.
This blog post will focus on key questions related to Data Transformation and Feature Engineering and explore how AWS SageMaker can help address them.
▢ [Automation] How can the transformation steps be effectively scaled to the entire dataset?
▢ [Automation] How can the transformation steps be applied in real-time to the live data before inference?
▢ [Collaboration] How can a data scientist share and discover the engineered features to avoid effort duplication?
▢ [Reproducibility] How do you track and manage different versions of transformed datasets?
▢ [Reproducibility] Where are the transformation steps and associated code stored?
▢ [Governance & Compliance] How do you track the lineage of data as it moves through transformation stages to ensure reproducibility and audibility?
Use Case & Dataset
-We will reuse the Fraud Detection use-case, dataset generator, and generated customer & transaction dataset.
Transform with SageMaker Wrangler
[U+2713] [Automation] How can the transformation steps be effectively scaled to the entire dataset?
U+26A0️ ㅤThe Data Wrangler’s free tier provides only 25 hours of ml.m5.4xlarge instances per month for 2 months. Additionally, there are associated costs for reading and writing to S3.
In the previous article, we discussed how SageMaker enables data scientists to quickly analyze and understand data. We were able to identify feature correlations, data imbalance, and datatype requirements.
To prepare the data for models, a data scientist often needs to transform, clean, and enrich the dataset. Fortunately, SageMaker’s data-wrangling capabilities allow data scientists to quickly and efficiently transform and review the transformed data.
This section will focus on running transformations on our transaction data.
Data flow
The data preparation pipeline in SageMaker is visualized as a directed acyclic graph called Data Flow. It connects different datasets, transformations, and analysis steps as defined.
During the exploration phase, we imported transaction data and generated an insight report. The same can be observed in the data flow graph.
The data flow UI offers options to add transformations, such as join and concatenate. We will explore these options in the next steps.
Data Enrichment
To begin, we will enhance the transaction data by merging it with customers’ billing address information. Why? This will allow us to validate transaction locality and flag transactions occurring outside of the customer’s state as fraudulent.
I have already imported the customer.csv from the S3 bucket.

Drop Unnecessary Column
During the exploration phase, we discovered that the “transaction_id” column is not correlated with the occurrence of fraud.
Additionally, for customer billing data, we are only considering “state” information. Let’s drop the unnecessary columns. Why? Reduce noise and dimensionality, simplify the analysis, and optimize storage.

Calculated field
In our fraud scenario, we are only interested in the time of day when a transaction occurs, and not the specific date or month. Let’s extract the time information as a calculated feature. Why? Improved feature correlation.
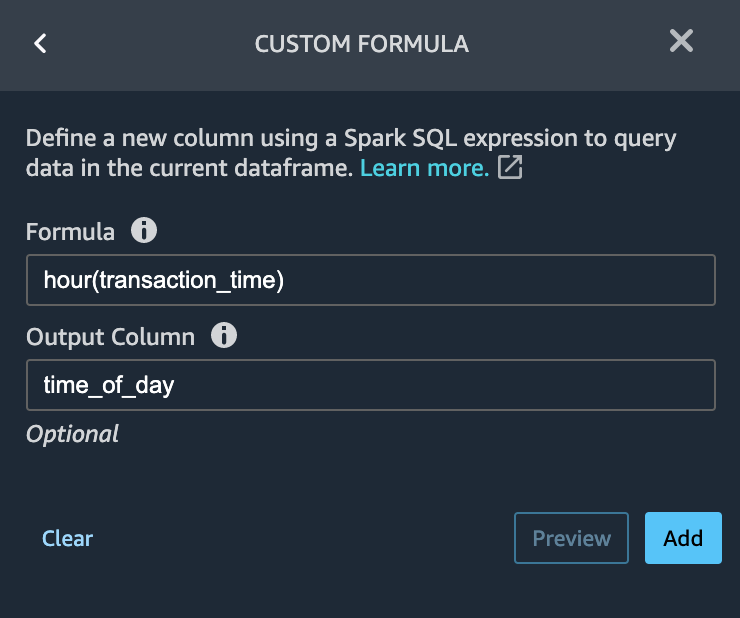
Rebalance
The transaction data has an uneven distribution, with significantly more non-fraud records than fraud records. This class imbalance can adversely affect the learning process of our model. To address this issue, let’s try to rebalance the data for training. Why? Avoid model bias.

As demonstrated, SageMaker Data Wrangler enables easy data transformation through intuitive UI controls. I highly recommend further exploration to discover transformation for your needs.
Discover with SageMaker Feature Store
[U+2713] [Reproducibility] How do you track and manage different versions of transformed datasets?
In the previous section, we performed several preprocessing steps on our data to generate output suitable for our model. This transformed data can serve as input to multiple models, making it a valuable feature within the dataset.
AWS SageMaker Feature Store provides an effective way to store, track, and share these features. Thus, eliminating the need for repetitive data processing. Additionally, the same feature can serve both training (Offline mode — batch, recent & historic data) & inference (Online mode — real-time, low-latency access, recent data).
Let’s look at how we can store our transformed transaction data as an online feature.
Create Feature Group
The transformed dataset contains multiple features, which SageMaker stores together as a Feature group. Let’s create one for our dataset.

The Create Feature Group wizard automatically attempts to infer the details of the feature group from the input data source. However, as observed above, it doesn’t support all data types such as timestamps or booleans. Therefore, before proceeding, we need to transform these into supported data types.
To do this, change the data type of the ‘fraud’ and ‘transaction_time’ columns to ‘float’ using the built-in transformation and restart the process.

Publish to Feature Group
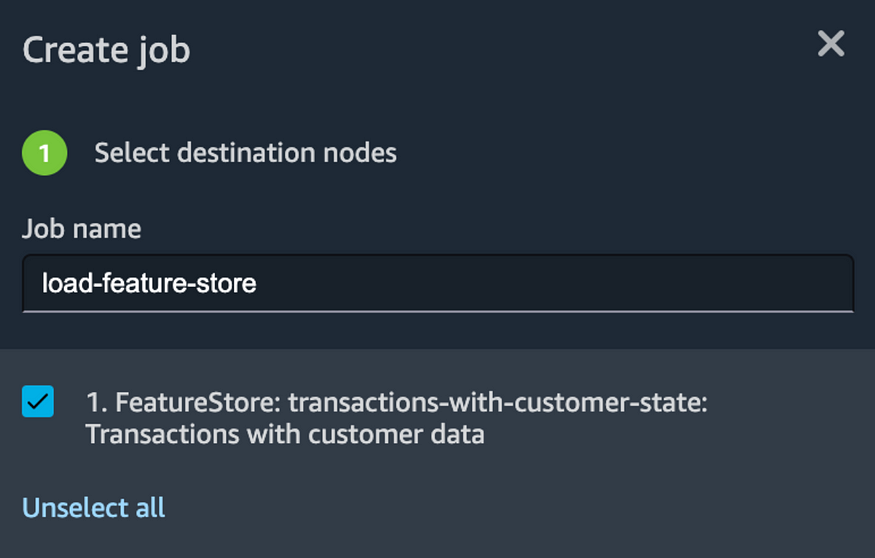
After a feature group is created, you should be able to add it as a destination.

Create a Job to load the feature store.
U+26A0️ ㅤYou may need to raise a quota increase request for “ml.m5.4xlarge instance for processing”.
Alternatively, you can load programmatically using PutRecord.
# Create a record
aws sagemaker-featurestore-runtime put-record
--feature-group-name transactions-with-customer-state
--record FeatureName=state,ValueAsString=TX
FeatureName=transaction_state,ValueAsString=TX
FeatureName=amount,ValueAsString=311
FeatureName=transaction_time,ValueAsString=1687287431 // Set it to current time for online mode
FeatureName=fraud,ValueAsString=0
FeatureName=time_of_day,ValueAsString=10
FeatureName=customer_id_0,ValueAsString=10
# Fetch record
aws sagemaker-featurestore-runtime get-record
--feature-group-name transactions-with-customer-state
--record-identifier-value-as-string 10 // customer_id_0
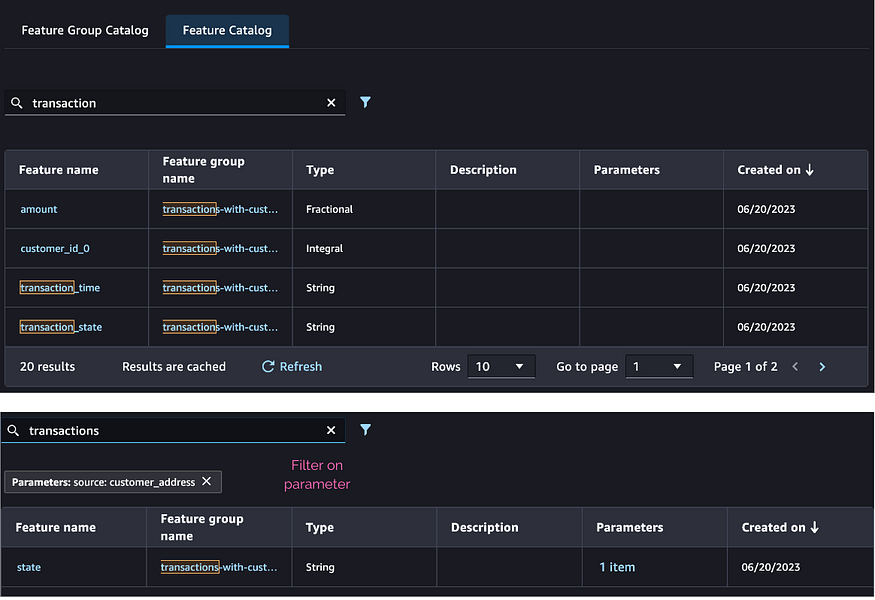
[U+2713] [Collaboration] How can a data scientist share and discover the engineered features to avoid effort duplication?
The Feature Store indexes features, and the associated parameters, allowing team members to easily search and discover them.
Track with SageMaker Lineage
[U+2713] [Governance & Compliance] How do you track the lineage of data as it moves through transformation stages to ensure reproducibility and audibility?
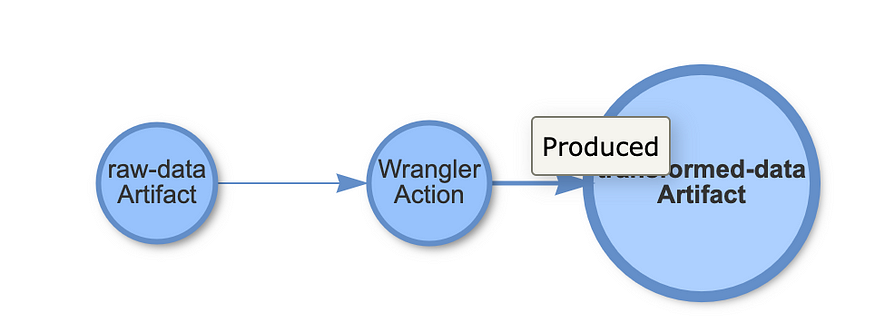
In the previous blog post on data exploration, we create a SageMaker artifact to capture details about the source data. In this blog post, we ran multiple transformations and pre-processing steps on that data. Now, the question arises: how can data scientists discover the transformations that are being applied to raw data?
To begin, let’s define input and output artifacts, as well as a wrangler transformation action in the Lineage Store.
# Create Artifact - Raw Data
aws sagemaker create-artifact --artifact-name raw-data
--source SourceUri=s3://my_bucket/raw.csv
--artifact-type raw-data
--properties owner=anirudh,topic=mlops
--tags Key=cost_center,Value=research
{
"ArtifactArn": "arn:aws:sagemaker:us-east-1:removed:artifact/24c7ff167309de3b466aab30f95a8810"
}
# Create Artifact - Transformed Data
aws sagemaker create-artifact --artifact-name transformed-data --source SourceUri=s3://my_bucket/transformed.csv --artifact-type transformed-data --properties owner=anirudh,topic=mlops --tags Key=cost_center,Value=research
{
"ArtifactArn": "arn:aws:sagemaker:us-east-1:removed:artifact/3ac1d219b2e4e9df89c149a92f4b2a2f"
}
# Create Action - Transform via Wrangler
aws sagemaker create-action
--action-name wrangler
--source SourceUri=s3://my_bucket/transform.flow
--action-type Wrangler
--status Completed
{
"ActionArn": "arn:aws:sagemaker:us-east-1:removed:action/wrangler"
}
# Create Association - "Wrangler" Applied to "Raw Data"
aws sagemaker add-association
--source-arn arn:aws:sagemaker:us-east-1:removed:artifact/24c7ff167309de3b466aab30f95a8810
--destination-arn arn:aws:sagemaker:us-east-1:removed:action/wrangler
--association-type AssociatedWith
# Create Association - "Wrangler" Produces "Transformed Data"
aws sagemaker add-association
--source-arn arn:aws:sagemaker:us-east-1:removed:action/wrangler
--destination-arn arn:aws:sagemaker:us-east-1:removed:artifact/3ac1d219b2e4e9df89c149a92f4b2a2f
--association-type Produced
Now that we have stored lineage, we can query it to understand what operations were performed on our raw data.
# Query Lineage for raw data
aws sagemaker query-lineage
--start-arns arn:aws:sagemaker:us-east-1:removed:artifact/24c7ff167309de3b466aab30f95a8810
--include-edges
{
"Vertices": [
{
"Arn": "arn:aws:sagemaker:us-east-1:removed:artifact/24c7ff167309de3b466aab30f95a8810",
"Type": "raw-data",
"LineageType": "Artifact"
},
{
"Arn": "arn:aws:sagemaker:us-east-1:removed:artifact/3ac1d219b2e4e9df89c149a92f4b2a2f",
"Type": "transformed-data",
"LineageType": "Artifact"
},
{
"Arn": "arn:aws:sagemaker:us-east-1:removed:action/wrangler",
"Type": "Wrangler",
"LineageType": "Action"
}
],
"Edges": [
{
"SourceArn": "arn:aws:sagemaker:us-east-1:removed:action/wrangler",
"DestinationArn": "arn:aws:sagemaker:us-east-1:removed:artifact/3ac1d219b2e4e9df89c149a92f4b2a2f",
"AssociationType": "Produced"
},
{
"SourceArn": "arn:aws:sagemaker:us-east-1:removed:artifact/24c7ff167309de3b466aab30f95a8810",
"DestinationArn": "arn:aws:sagemaker:us-east-1:removed:action/wrangler",
"AssociationType": "AssociatedWith"
}
]}
You can visualize this using Visualizer Python Script.
[U+2713] [Reproducibility] Where are the transformation steps and associated code stored?
SageMaker provides native integration with Git. You can initialize a repository in the studio directly or clone an existing one within SageMaker Studio. After this, you can perform all git operations like commit, pull, push, and more, directly from SageMaker Studio.

Scale with SageMaker Pipeline
[U+2713] [Automation] How can the transformation steps be applied in real-time to the live data before inference?
SageMaker Data Wrangler offers a convenient option to export data flows as SageMaker pipelines(via Jupyter Notebook) and also as serial inference pipelines (via Jupyter Notebook) for data processing during inference.
This inference pipeline includes two containers: the Data Wrangler container for pre-processing and transforming data, and the model container for training or inference combined into a single serving endpoint.
U+26A0️ As of today, the inference export operation doesn’t support join operations in the data flow.

We will explore this further in an upcoming blog on inference.
U+26A0️ Clean-up
If you have been following along with the hands-on exercises, make sure to clean up to avoid charges.
In summary, AWS SageMaker capabilities like Wrangler, Feature Store, and more simplify the complex tasks of data transformation and feature engineering for data scientists.
In the next article, I will explore how SageMaker can assist with Experiments, Model Training & Evaluation.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

