


Data Science for Everyone: Getting To Know Your Data — Part 1
Last Updated on July 19, 2023 by Editorial Team
Author(s): Sumudu Tennakoon
Originally published on Towards AI.
Data Science, Education
The first article of “Data Science for Everyone”: an article series aimed at addressing data literacy in the community.
“Data Science” became one of the popular buzzwords in the technology world in the past decade. The professional role of a “Data Scientist” has been referred to as the “sexiest job in the 21st century” [1].
The advancement of the field and other related technologies like Machine learning, Artificial Intelligence, High-performance hardware/software Platforms for data applications paved the way to several new professional roles like Data Engineer, Machine Learning/AI Engineer, Machine Learning/AI Application Developer, etc.
“According to an IBM survey in the year 2017, the number of job openings in the field estimate to have 5-year growth of 28%, with over 61,000 forecasts for 2020.” [2]
So, what is Data Science? What is science has to do with data there? Is Data Science is actually a new field of study? How we can accurately describe the role of a Data Scientist? How is the role of a data scientist different from other related job roles? What makes the Data Scientist qualified to be recognized as a Scientist? are some of the questions where the answers we find are not always clear.
Everyone these days used to work with some form of data science methodology at work. Most of their professional and personal lives are impacted by data-driven products and tools (e.g. Social Media, Online Shopping, etc.). Therefore, at least a basic understanding of data science and related concepts is essential regardless of your educational level, background, or profession.
Before trying to understand what exactly is Data Science, let’s first understand what is Data and Science mean separately and how they are connected to serve the purpose. Data Science is not something that belongs only to Data Scientists, not even belongs only to computer and information technology (ICT) professionals. It is simply a broad field of intersecting with almost all the disciplines in both science and non-science areas.
“Data literacy” is the ability to read, understand, create, and communicate data as information. It will be an essential component of the literacy measurements in the world rapidly moving through the “digital transformation” era with its complexity is continuing to increase [3,4].
This article series will take a philosophical approach to connect the dots to construct a conceptual image to help everyone to get a better understanding of Data Science, related concepts, and the role of Data Scientist as a profession.
Data in your life
Whether you are a data professional or not, you should never underestimate your involvement with the data in your life. Every time you log in to the internet, do a web search, read some blog article, interact with others on social media, send or receive emails, order your groceries, buying an item, you access data from a massive data pool that existed globally. At the same time, you provide intentional and unintentional more data to the same pool.
Information you provided when creating your profile, the messages you send via chat, the photos you upload on social networks, the likes and comments you post on the messages of others, the emails you send are part of your intentional contribution. The unintentional contributions such as your current location tracked by the GPS of your phone, log in, and activity details recorded by social media and websites (which includes what device you use, which operating system you use, which browser you use, etc.), your shopping records.
This data on and originates from you primarily possed by companies such as social media, Internet service providers, numerous other marketing, and government institutes. You also consume their products and tools built using data science methodologies that use the enormous data pool mentioned above. That is how you get the next advertisement to play in your online video streaming, suggest who should you get connected next in social media, suggest the next item you need to buy from an online shop, next restaurant you want to visit, what is the shortest or fastest path to go to a location in the current traffic conditions, etc.
Data: Formulating the Concepts
Definitions
The word data is the plural form of the word datum, which has the meaning of a “single piece of information, as a fact, statistic, or code” [5]. Another definition is “something given or admitted especially as a basis for reasoning or inference” [6]
In simple terms, data can be defined as numbers, characters, words, sounds, or symbols that can use to describe, quantify, recognize physical or virtual entities.
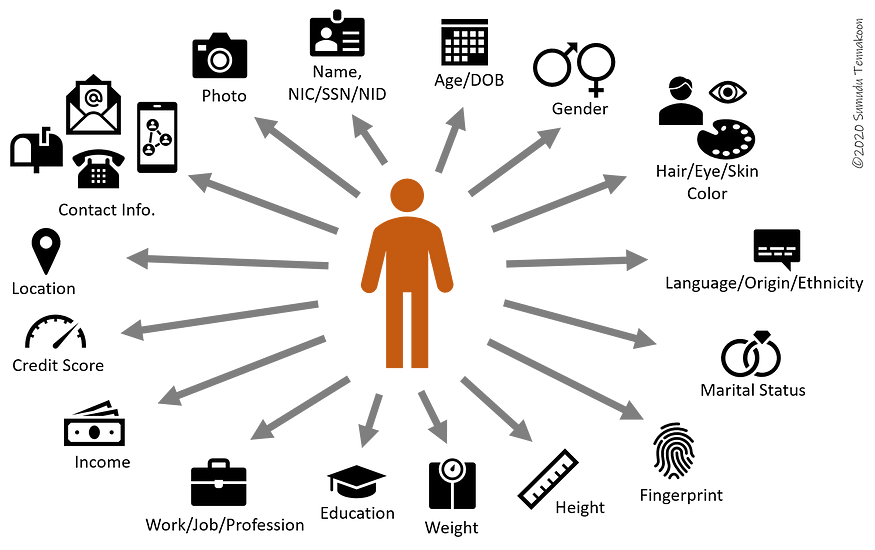
For example, if you can sufficiently describe a person with some data points (datums) such as name, date of birth, gender, appearance (colors and built), height, weight, etc. The same information can also be used to differentiate one person from another for recognition purposes.

Let’s look at this conversation between two people “That [tall] [boy] with [brown hair] working as a [barista] at [ABC Cofee Shop] helped me when my car broke down in front of his shop. I think his name is [James]”. The words within [] are the data points you may use to recognize the specific person in a normal conversation as well as in a systematic data application.
Data points are sometimes mentioned as features, data fields, characteristics, facts, and attributes. Which should be taken as the same concept at the high level.
A collection of data fields we can use to describe a person can be called a data model of a person. That becomes a record when the values are assigned to those fields. Similarly, we can represent other physical objects like vehicles, buildings, books using their data points which can describe their characteristics.
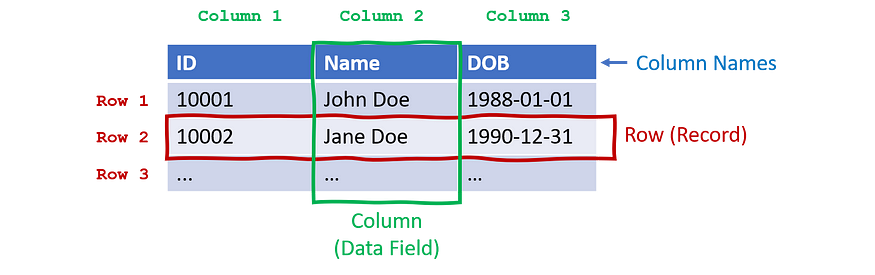
Several related records can be arranged into a structure such as a table or a list. Imagine a table containing data about 100 different people one row representing each person and each column used to store one data point.
Many related data structures are combined into one larger structure that becomes a database. Depending on the application, there are multiple types of databases and database management systems to choose from.
Data and Information
We looked at the basic concept of the data everyone should know. Let’s quickly look at another related concept always mention with the data. That is Information. Let’s try to understand the difference between information and Data.
As we discussed above, data comes with two main components, structure and context. Without them, data has no meaning or value.
When data is taken with structure, context, and meaning, we call it information.
Here is an example, you got some data: a list of values with different color names. It is certainly data but can it alone give you any context? Is that data meaningful or useful? The answer could be no for both the questions.
What if the same list is given with another data point for each color value: a car model and brand? The data now have some context and meaning. How about adding another data point: price? We now added some context to the data and can be used to derive useful information from it.
In the person data example illustrated in Figure 4, all the attributes “name”, “date of birth”, “height”, “weight”, etc. have no use unless they are connected to the person entity (arrows in the figure).
Data Organization
Based on how they are arranged, data collections can be categorized as structured, unstructured, and semi-structured.

The most traditional form of data collection is structured where the data is organized into tables which is easy to handle by both the human and machines. Structured data are easier to search and manage.
Unstructured data like images, videos, sound, and large text contents like books, letters, paragraphs are used by humans for many centuries of years even before the computer era. Managing and searching through unstructured data is quite cumbersome. According to a Forbes Technology Council post referring to Gartner, an “estimate that upward of 80% of enterprise data today is unstructured [7]”. Therefore, the research and development efforts in data science are heavy in this area.
With the advent of the internet and evolution of the computer technology, semi-structured data forms like mark-up languages, hierarchical data structures have become popular in storing and transmitting data. Semi-structured data considered self-describing data and it helps to store complex data that cannot easily organize into tables.

In the process of analyzing the data, unstructured data is converted into a structured or semi-structured form utilizing suitable data science methodologies.
Data types
Let’s now take a different perspective on understanding data.
Data can be represented in many different ways such as numbers, characters, symbols, pictograms, colors, signs, object arrangements, etc.

In digitally computerized data representation every other representation will melt down into numbers and ends up in the binary form when storing, transmitting, and computing.
We can find a system of data types used in computing such as boolean, integer, float, and characters, as primary types.
The derived types of these are strings, arrays, lists, sets, vectors, matrices, tensors, complex numbers, structure, enumerators, dictionaries, tables, and objects made possible the complex computing applications we all benefit from in this era.
A special data type is known as null, none or void depending on the programming language is used to represent “nothing”.
An in-depth discussion on the different data types and their uses is planned for a future article.

Data File Types
Traditionally you access data from printed materials, videos, display boards, etc. In a computer system, your data comes as files or streams. The common file types are text, binary, images/photos, audio, video, archive, compressed, database. A detailed discussion on these file formats and their uses is planned for a future article.
Data Encoding
The data you accessed is not always stayed in the same format as it presented to you. We learned the ultimate form of data will be binary (1/0) in the digital systems. However, there are intermediate representations used when storing and transmitting data.
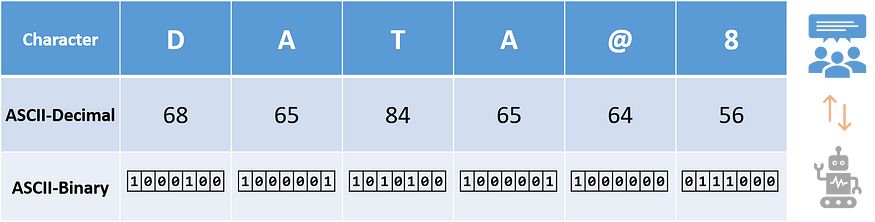
When data is moving from one location to another their representations can also change. We call that encoding and decoding with reference to one representation. One of the common encoding schemes is the American Standard Code for Information Interchange (ASCII) [8] which use to represent characters (letters, digits, and special signs). Figure 10 illustrates the encoding of the text “DATA@8” into ASCII. The universally accepted encoding scheme for the same purpose is known and UNICODE [9].
Encoding should not be confused with encryption, which hides data content from unintended parties. A detailed discussion on encoding-decoding, encryption-decryption, and their uses are planned for a future article.
Analog vs. Digital Data
In nature, the data exist in analog form and we need to convert them into machine recognizable binary form to be used with digital computing machines. The term “digitization” is used to name this conversion process [10]. In electronics, this is sometimes called analog to digital encoding.
Some examples of digitization are scanning a paper document to create its digital copy, recording a sound from your mobile phone mic, recording your walking track using GPS data.
When the digitally stored data need to serve as an analog output, digital to analog conversion is used. You are using this analog to digital conversion and vise versa in your personal devices such as mobile phones, video displays, sound recorders, cameras, music players, etc.

Qualitative and Quantitative nature of data
Each data measurement can also be classified as qualitative and quantitative and their subclasses by the nature of values they can take.

Data is a broad concept that can be examined from a variety of perspectives. The more you combine those different perspectives, you will get a better grip of the data you are dealing with. Therefore, the concepts we discussed above are crucial at every stage in the data science workflow. They are also important at any time you engage with the data or data-driven applications.
Measuring Data
Data is quantifiable. The smallest unit of digital data is called a bit, which is also used as a scale to measure data. A single bit can store a value of either 0 or 1.
In the data encoding example, we showed that ASCII uses 7 bits which makes 2⁷ = 128 possible combinations. In other words, 128 different characters can be represented using an ASCII value.
A group of 8 bits (octet) is considered as one byte which is the fundamental unit of measuring data. The symbol defined by the International System of Units (SI) is B. To measure large quantities of data the SI prefixes such as Kilo (K), Mega (M), Giga (G), etc. are used [11]. The use of these prefixes must not be confused with the binary interpretation of prefixes used in many applications like Ki, Mi, Gi, etc.[12,13]

Data visualization
You have seen charts, plots, and various infographics condensing data and information into graphical representations. Visualization is a very efficient way of communicating data.
It is also important in the early stages of data science workflow to understand the data, and various quality control measures before moving into the later stages. Some argue data visualization is both an art and science. An in-depth discussion on data visualization methods and their uses are planned for a future article.

Data Life Cycle
Like we humans, animals, plants, and everything in the universe, data also go through a life cycle.
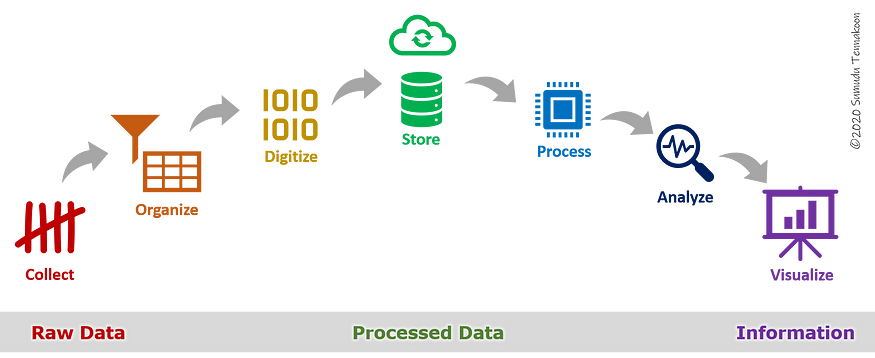
In a computerized process, data is going through a lifecycle we can generalize into six simple steps as outlined below. Collect, Organize, digitize, store, process, analyze, visualize.
Most of these terms are self-explanatory but we will be discussing these steps in detail at a later time. Data moving through this cycle starting with raw data getting processed and become information we can use to generate useful insights. There is a missing piece in this picture is data disposal when the data is no longer needed. That will be something to discuss in detail in a future article.
Data are generated by many different natural and artificial(human-made) sources but never collected by themselves. One or more receptors sensitive to the data source is used to observe, measure, and record the raw data. A receptor can be a person, sensor, recording device, computer input device, or node in a communication network.
During the organizing step, collected raw data goes through validation, filtering, transformations, structuring, connecting different sources, separating into different structures, etc. Digitization of the data is sometimes done before organizing the data to get the support of the digital computational tools in that process.
The value of data comes when it is converted into information. In that process, the data is analyzed, interpreted with aggregation or summarization usually accompanied by graphical representations to tell the story out of the data. A detailed discussion on data visualization is a topic for a future article in the series. In short, collected data is the input which is not useful in the raw form and the information is the usable output product from this cycle.
Example: Census Data
Let’s take the example of the census happening once every decade. This process involves a massive amount of fieldwork in data collection and technical work in organizing, storing, processing, analyzing, and interpreting.
Traditionally each household is provided with a form to fill out their basic data and submit to the Census Bureau before the counting day. This process is now turned into an online task via web form. The census takers visit each house during the counting day and verify the reported numbers (if any) via in-person interviews [16]. The collected data has to go through the data life cycle outlined.
The final output from this process will be used for many different applications in governing, funds allocation, deciding on the number of representatives for each area, economic decision-making, etc. The analysis reports are available to the public as well. The diagram below illustrates the process conceptually and at a very high level.

Moving forward
This article has laid the foundation for understanding some fundamental concepts of data. The next articles will continue discussing the characteristics and changes of data followed by the discussion of how the data being used in our daily lives and how it helped to shape our human civilization by advancing our knowledge, science, and technology.
Getting To Know Your Data — Part 2 (Seeing Data Through the “ Data Iris”)
The second article of “Data Science for Everyone,”: an article series to address data literacy in the community.
pub.towardsai.net
Acknowledgments
The author would like to thank a number of content creators in the data science and machine learning topics not limited to online learning platforms and blogs for making available insightful resources to explore and learn this fascinating subject of Data Science.
Disclaimer
The views and opinions expressed in this paper are those of the author and do not represent those of the employer or other institutions related to the author. This article is part of a broader publication aimed at addressing data literacy in the community. The author has put a good amount of effort into researching the topics discussed, simplifying the technical jargon to increase the understanding of the content, finding relevant references to ensure the validity of the facts presented. Discussion, criticism, alternative thoughts, and suggestions are welcome.
References
[1] Davenport, Thomas H., and D. J. Patil. “Data Scientist: The Sexiest Job of the 21st Century.” (October 2012). Harvard Business Review 90, no. 10 : 70–76.
[2] IBM Cloud Education, “Data Science”.(May 2020). IBM Cloud Learn Hub.
[3] Baykoucheva, Svetla. “Managing Scientific Information and Research Data”. (2015). Waltham, MA: Chandos Publishing. p. 80. ISBN 9780081001950. [via Wikipedia]
[4] Carlson, Jake; Johnston, Lisa. “Data Information Literacy: Librarians, Data, and the Education of a New Generation of Researchers”. (2015). West Lafayette, Indiana: Purdue University Press. p. 15. ISBN 9781557536969. [via Wikipedia]
[5] Definition of Datum: https://www.dictionary.com/browse/datum (retrieved on 12/10/2020)
[6] Definition of Datum: https://www.merriam-webster.com/dictionary/datum (retrieved on 12/10/2020)
[7] Rizkallah, Juliette. “The Big (Unstructured) Data Problem”. (June 2020). Forbes Technology Council.
[8] “ASCII”. Wikipedia. (retrieved on 12/17/2020)
[9] “The Unicode Standard”. Unicode Inc. (retrieved on 12/17/2020)
[10] Gupta, Mark Sen. ”What is Digitization, Digitalization, and Digital Transformation?”. (March 2020). ARC Advisory Group Blog.
[11] “IEC 80000–13:2008 Quantities and units — Part 13: Information science and technology”. International Organization for Standardization (ISO). (2008). (via Wikipedia on 12/17/2020)
[12] NIST. “Prefixes for binary multiples”. The NIST Reference on Constants, Units, and Uncertainty. (retrieved on 12/17/2020)
[13] “1541–2002- IEEE Standard for Prefixes for Binary Multiples". (2009). IEEE. doi:10.1109/IEEESTD.2009.5254933. ISBN 978–0–7381–6107–5. (via Wikipedia on 12/17/2020)
[14] Gershon, Nahum; Page, Ward. “What storytelling can do for information visualization”. (2001). Communications of the ACM. 44 (8): 31–37. doi:10.1145/381641.381653.
[15] Tennakoon, Maheesha. Data Visualization using Python (unpublished).
[16] “Census”. Wikipedia. (retrieved on 12/10/2020)
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

