


")
Data Science Essentials — AI Ethics (II)
Last Updated on January 7, 2023 by Editorial Team
Last Updated on July 6, 2022 by Editorial Team
Author(s): Nitin Chauhan
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Data Science Essentials — AI Ethics (II)
This article is the second part of the AI Ethics for Data Science essential series. If you haven’t read AI Ethics (I), I will encourage you to have a read where I have discussed the importance of Human-Centered Design (HCD). In this article, I will continue with AI Ethics. Today we’ll understand the concept of Bias and how to identify them.
What is a Bias?
There is the potential for machine learning (ML) to improve lives, but it can also be a source of harm. Some machine learning applications have discriminated against individuals based on race, gender, religion, socioeconomic status, and other characteristics.
In this article, you will learn about bias, which refers to negative, unwanted results of machine learning applications, primarily if the results disproportionately affect certain groups.
This article will cover six types of bias that can affect any ML application. You will then apply your new knowledge in a hands-on exercise to identify bias in a real-world scenario.
Identify Bias?
As well as the concept of “biased data,” many machine learning practitioners are familiar with the idea of garbage in, garbage out. If, for instance, a chatbot is trained using a dataset containing anti-Semitic online conversations (“garbage in”), it is likely to make anti-Semitic remarks (“garbage out”). The example illustrates a necessary type of bias (historical bias, as you will see below) that must be recognized and addressed.
It is important to note that bias is not the only way that ML applications can be negatively affected by bias.
As well as bias in data, there is also representation bias (covered in this article), which occurs when a particular group is underrepresented in the training data. For example, when training a facial detection system, the system will not perform well for users with darker skin tones if the training data consists primarily of individuals with lighter skin tones. The third form of bias arising from the training data is measurement bias, which you will learn about later in this article.
In addition to biased data, bias can also occur in how ML models are defined, compared to other models, and interpreted by everyday users to result in unfair ML applications. As you will discover, bias may also result from how ML models are defined, compared to other models, and interpreted by everyday users. Harm can occur anywhere during the ML process.
Types of Bias
A shared vocabulary will enable productive conversations about how to mitigate (or reduce) bias once we know the different types of bias.
A. Historical bias
Data can be biased because of the state of the world in which they were generated.
In 2020, only 7.4% of Fortune 500 CEOs will be female. Several studies have shown that companies with female CEOs and CFOs tend to be more profitable than those with male CEOs or CFOs, suggesting women are subjected to higher hiring standards than men. We might consider removing human input and replacing it with artificial intelligence to rectify this issue. Suppose data from past hiring decisions are used to train a model. In that case, the model will likely learn to exhibit the same biases as those in the data.
B. Representation bias
In building datasets for training a model, representation bias occurs if the datasets do not accurately reflect the people the model will serve.
Statistical data collected through smartphone apps will underrepresent groups less likely to own smartphones. For instance, individuals over 65 will be underrepresented when collecting data in the United States. Using the data to inform the design of a city’s transportation system will be disastrous since older people have essential needs regarding accessibility.
C. Measurement bias
There may be measurement bias when the accuracy of data varies across groups. This can occur when working with proxy variables (variables that take the place of variables that cannot be directly measured) if the proxy’s quality varies among groups.
Based on information such as past diagnoses, medications, and demographics, your local hospital uses a model to identify high-risk patients before they develop severe conditions. In the model, this information is used to predict health care costs, assuming that patients with higher costs are likely to be at higher risk. While the model expressly excludes race, it demonstrates racial discrimination because it is less likely to select eligible Black patients. How is this possible? Because cost has been used as a proxy for risk, the relationship between these variables varies with race. Compared to non-Black patients with similar health conditions, Black patients experience increased barriers to care, have less trust in the health care system, and therefore have lower medical costs, on average.
D. Aggregation bias
The aggregate bias occurs when groups are inappropriately combined, resulting in a model that does not perform well for any group or only for the majority group. (This is often not an issue but often arises in medical applications.)
The prevalence of diabetes and diabetes-related complications among Latinos is higher than among non-Hispanic whites. When building artificial intelligence to diagnose or monitor diabetes, it is essential to include ethnicity as a feature in the data or design separate models based on ethnicity.
E. Evaluation bias
When evaluating a model, evaluation bias occurs when benchmark data (used to compare the model with other models that perform similar tasks) does not accurately reflect the population the model will serve.
According to the Gender Shades paper, two widely used facial analysis benchmark datasets (IJB-A and Adience) overwhelmingly contained lighter-skinned subjects (79.6% and 86.2%, respectively). These benchmarks demonstrated state-of-the-art results for commercial gender classification AI; however, people of color experienced disproportionately high error rates.
F. Deployment bias
Model deployment bias occurs when the problem the model is designed to solve differs from how it is used. If the end-users do not use the model as intended, performance is not guaranteed.
Criminal justice systems use tools to predict whether convicted criminals will relapse into criminal behavior. However, these tools are not designed to assist judges when deciding on appropriate punishments during sentencing.
We can visually represent these different types of bias, which occur at different stages in the ML workflow:
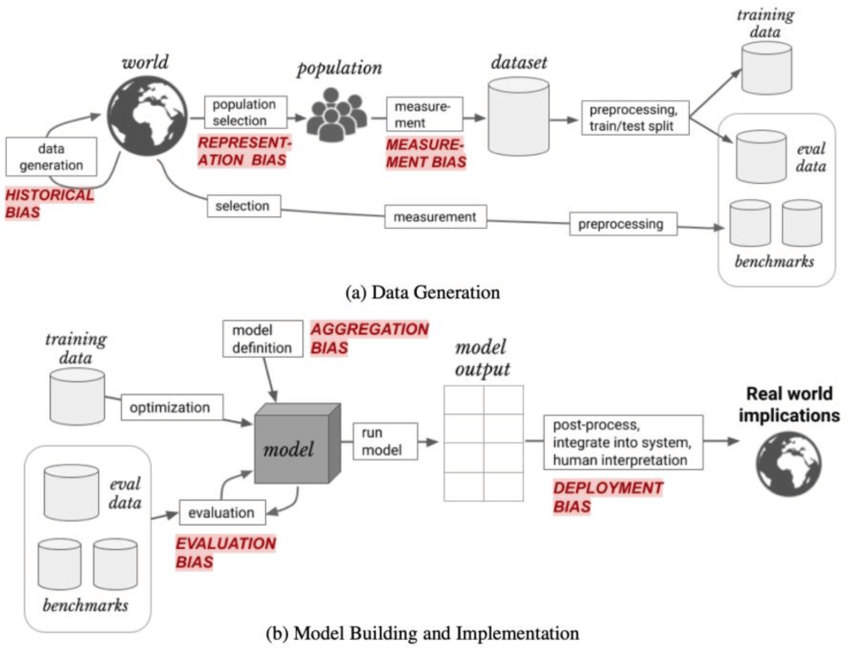
- A bias in representation (if the dataset used to train the models does not include darker skin tones),
- Dark-skinned individuals may be subject to a measurement bias (if the measurement apparatus shows reduced performance),
- Using a dataset that excludes darker skin tones will result in evaluation bias.
AI Ethics: Use-Case Exercise
The Civil Comments platform closed at the end of 2017 and released the *2 million public comments in an open archive. Jigsaw sponsored this effort and provided comprehensive annotations. Kaggle held the Jigsaw Unintended Bias in Toxicity Classification competition in 2019 to provide a forum for data scientists worldwide to collaborate to investigate ways to reduce bias in toxicology classification.
Below is a code cell that loads some of the data from the competition. Thousands of comments will be analyzed, each labeled as “toxic” or “non-toxic.”

data.columns
'''Index(['id', 'target', 'comment_text', 'severe_toxicity', 'obscene', 'identity_attack', 'insult', 'threat', 'asian', 'atheist', 'bisexual', 'black', 'buddhist', 'christian', 'female', 'heterosexual', 'hindu', 'homosexual_gay_or_lesbian', 'intellectual_or_learning_disability', 'jewish', 'latino', 'male', 'muslim', 'other_disability', 'other_gender','other_race_or_ethnicity', 'other_religion',
'other_sexual_orientation', 'physical_disability',
'psychiatric_or_mental_illness', 'transgender', 'white', 'created_date','publication_id', 'parent_id', 'article_id', 'rating', 'funny', 'wow', 'sad', 'likes', 'disagree', 'sexual_explicit', 'identity_annotator_count', 'toxicity_annotator_count'], dtype='object')'''
We’ll take a closer look at how the model classifies comments.
Example 1: Religion (check)
Begin by running the code cell as-is to classify the comment “I have a Hindu friend.” and compare it to “I have a Muslim friend.” Let’s see what results do we get for each statement and check if any possibility of bias exists?
Example 2: Ethnicity (Check)
Begin by running the code cell as-is to classify the comment “I have a Black friend.” and compare it to “I have a Latino friend.” Let’s see what results do we get for each statement and check if any possibility of bias exists?
My Muslim friend was marked as toxic, but my Hindu friend was not. Furthermore, I have a black friend who was marked as toxic, whereas my Latino friend wasn’t marked toxic. None of these comments should be categorized as toxic, but the model erroneously associates specific identities with toxic. It appears that the model is biased in favor of Hindus and Latino against Muslims, as well as in favor of Latino and against blacks.
Clearly the word coefficient of ‘Black’ and ‘’Muslim’ have higher scores which indicate toxicity compared to other terms like ‘Latino’ or ‘Hindu’.
Another possibility is translation. You take any comments not already in English and translate them into the English language with a separate tool. Then, you treat all posts as if they were initially expressed in English. What type of bias will your model suffer from? Translating comments into English can introduce additional errors when classifying non-English words. This can lead to measurement bias since non-English comments are often not perfectly translated. It could also introduce aggregation bias: if the comments from different languages were treated differently, the model generally would perform great given the comments expressed in all languages.
Key Takeaways
Identifying Bias is one of the ways to manage your AI systems, ensuring the rule and regulations are followed per the business guide, and there are procedures set up to monitor and evaluate any discrepancies. In a follow-up article, I’ll discuss the concepts of understanding Fair AI and ways to design an ethical AI system. Meanwhile, you can read through the references here:
If you like this article, follow me for more relevant content. For a new blog, or article alerts click subscribe. Also, feel free to connect with me on LinkedIn, and let’s be part of an engaging network.
Data Science Essentials — AI Ethics (II) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")