



Data Science Essentials — MLOps
Last Updated on July 3, 2022 by Editorial Team
Author(s): Nitin Chauhan
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Data Science Essentials — MLOps
In any organization, whether a startup or a large corporation, you will encounter challenges in evaluating, versioning, and managing machine learning models. And this exposure will not be limited to those at senior levels.
This article aims to explain Machine Learning Operations MLOps. It will simplify the vast and fascinating world of Machine Learning Operations and its associated infrastructure. This article will better understand how machine learning models are deployed in production, the stages, the process, and the tears involved.
Why MLOps?
Creating a Machine Learning model that can predict what you want it to anticipate from the data you have supplied is relatively easy. However, the creation of an ML model which is dependable, fast, accurate, and can be used by many users is more challenging.
The necessity of MLOps can be summarized as follows:
- An individual cannot keep track of the massive amount of data required by machine learning models.
- The parameters we tweak in ML models are often difficult to track. Small changes can have a substantial impact on the results of the model.
- It is necessary to keep track of the model’s features; feature engineering plays a significant role in determining the model’s accuracy.
- It is not the same as monitoring a deployed software application or web application when monitoring an ML model.
- The art of debugging a machine learning model is highly complex.
- Since models are based on real-world data, they must constantly be updated as the real-world data changes. We must keep track of new data changes and ensure the model is updated accordingly.
What’s MLOps?
An ML model is deployed to a production environment using a series of processes or sequences of steps referred to as Machine Learning Operations. Before a machine learning model is ready for production, several steps must be taken. These processes ensure that your model is scalable and performs accurately for a large user base.
How’s MLOps different from DevOps?
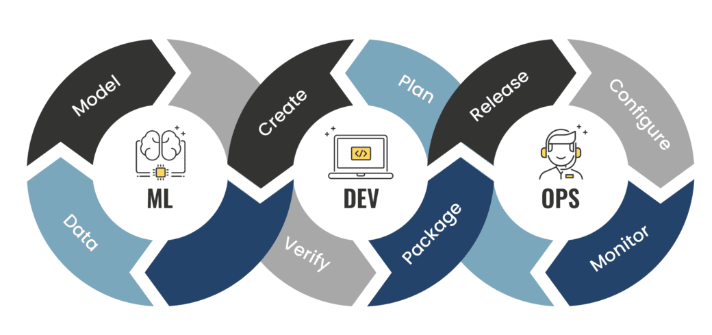
ost of you will be familiar with DevOps, which refers to building and deploying software applications. You may be wondering how MLOps differs from DevOps.
For the development of software applications, the DevOps stages are intended. This cycle continues until you have completed the application. You plan the features, write code, build the code, test it, prepare a release plan, and deploy the app. Monitoring the infrastructure where the app is deployed is also part of this process.
Stages of MLOps
A. Planning: Our scope of work involves defining the project and evaluating whether Machine Learning can be used to solve the problem. We perform requirements engineering and verify that relevant data is available.
B. Data Preparation: In data engineering, data is collected, baselines are established, and the information is cleaned, formatted, labeled, and organized.
C. Modeling: We now proceed to the coding part of the process. In this step, we create the machine learning model. In this stage, we train the model with the processed data, perform error analysis, define error measurement, and track the model’s performance.
D. Deployment: Depending on the requirements, we deploy the model in the cloud or on edge devices. An edge-based model could be packaged using an API server that exposes REST or gRPC endpoints, a Docker container deployed on cloud infrastructure, a serverless cloud platform, or a mobile application.
The monitoring infrastructure is required to maintain and update the model once the deployment has been completed. This stage consists of the following components:
- Monitor the infrastructure we deploy — for load, usage, storage, and health. This provides information about the system in which the machine learning model is installed.
- Analyze the model to determine if it is performing as expected, valid for real-world scenarios, and showing a loss, bias, and data drift.
This lifecycle applies to most ML uses since some models may require learning from the inputs and predictions of users.
ML Environment
This step involves gathering data from a variety of different sources. ML models require a large amount of data to learn. Data collection entails consolidating all kinds of raw data about the problem. For example, image classification may require you to collect all available images or scrape the web for images. For voice recognition, you may need to collect many audio samples.
- The Data Verification step aims to ensure that the collected data is accurate, reliable, reflects the real world, is in a consumable format, and properly structured.
- The Feature Extraction process determines the most important features to predict a result. Alternatively, the model may not require all the data to discover patterns; some columns or parts of the data may not be used. Some models perform better when a few columns are dropped altogether. We usually rank the important features, including those with high importance, and those with lower or near zero importance are removed.
- In this step, protocols for communication, system integration, and the communication between various components in the pipeline are defined, as well as how the pipeline components interact.
- The initial source of your data pipeline should be connected to your database, then machine learning models to be connected to the database with proper access, your model to expose prediction endpoints in a particular manner, and your model inputs to be formatted in a specific style. All the system’s necessary configurations must be finalized appropriately and documented.
- As we progress through the coding process, we develop a base model that can learn from the data and predict. Many machine learning libraries are available with support for multiple languages. Ex: Tensorflow, Python, Scikit-Learn, Keras, Fast-AI, etc. Once we have a model, we improve its performance by tweaking hyperparameters and modifying it using different approaches until your model beats the baseline model or score.
Business Use-Case

- In the first step, we collect information about Nick’s apple farm. The pictures of the good apples, the ok apples, and the bad apples will be collected. The excellent town folk will then be asked to send pictures of the apples they purchased from Nick. This step is the EDA and the compilation of data.
- Our collection of pictures has been assembled. Several hundred pictures have been labeled with Nick’s help. This step involves checking the resolution of the images, setting a standard resolution, discarding low-quality photos, and changing the contrast and brightness of the pictures to make them more readable.
- As a next step, we will train a TensorFlow model to classify the images. Consider using a sequential neural net with ReLU activation, with one input layer, two hidden layers, and one output layer. This is a simple convolution neural net. We divide our image dataset into training and testing sets, provide the training data as input to ConvoNet, and the model is trained. This step is called Model Training.
- We evaluate the model once it has been trained by using the test dataset and comparing the prediction with the actual result to determine if it was accurate. This step is called Model Evaluation.
- The model analysis consists of tweaking the hyperparameters to increase their accuracy, retraining the model, and re-evaluating it. This iteration is repeated until the model meets Nick’s needs.
- This is deploying the ML Engine so that Nick can use it for her daily work. We deploy a server in the cloud with prediction APIs and create an app or website where she can upload images and receive real-time results.

As you can see in the diagram below, all the work has been completed manually, from data preparation to deployment. This process of MLOps is called Traditional ML Pipeline. We have completed our deployment, but all the work must be done manually.
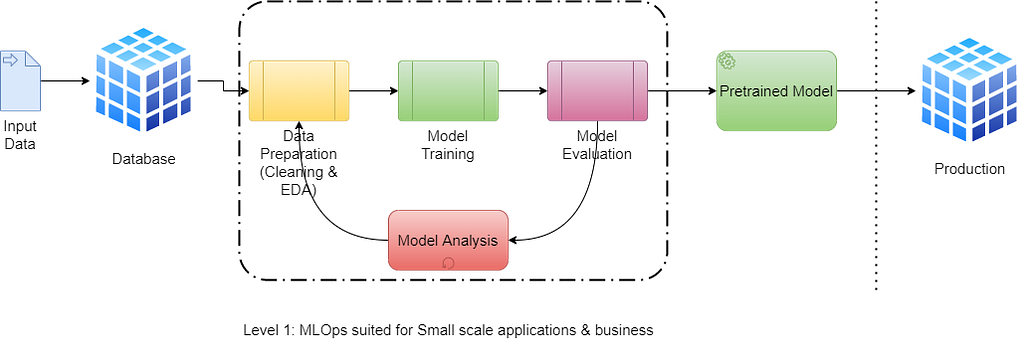
Challenges
An individual data scientist or machine learning engineer can also achieve this level of MLOps. This is good enough to test the model in your development environment.
Here are a few questions we should ask ourselves:
- Would your model be able to replicate the result with different varieties of apples?
- Is your model capable of retraining when new data is added?
- Can you scale your model so hundreds of thousands of people can use it simultaneously?
- When you deploy models across a large region or even across the globe, how do you keep track of them?
Automated ML Pipelines
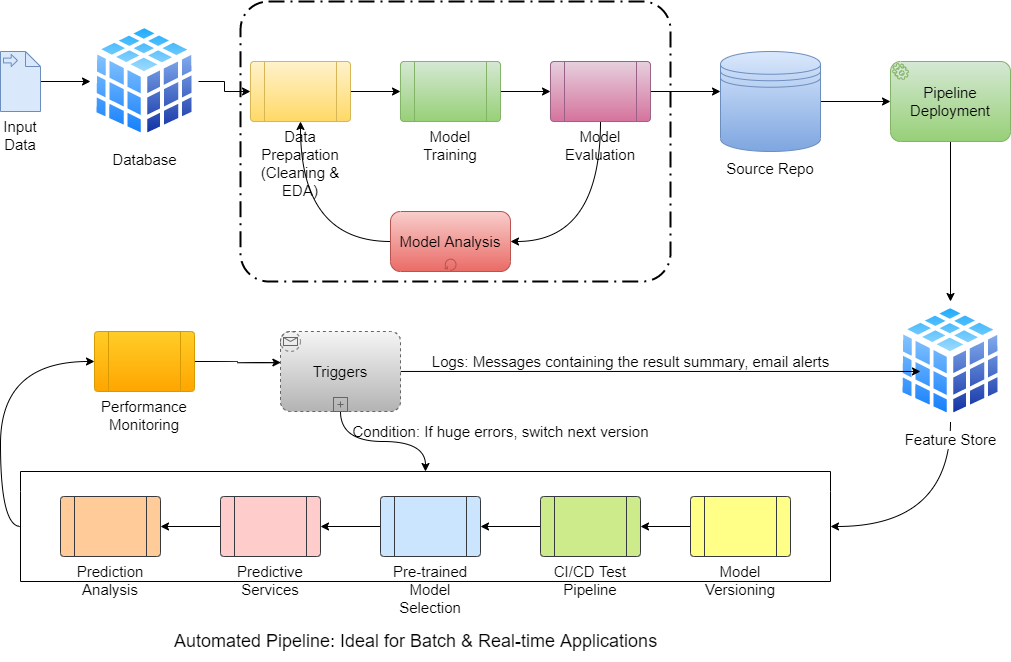
An Automated ML Pipeline is a solution for a scaled-up data product that facilitates using either a batch or real-time streaming application. The main difference from the traditional ML pipeline is the addition of the following components:
- Source Repo: This will act as a central repo for all your models developed by either one developer or a team of developers, each working on a feature set.
- Feature Store: This acts as central storage for all the features computed during the EDA & Feature Engineering process. These will also contain any results and logs generated by the application.
- Pipeline Set: A combination of model versioning, CI/CD testing, predictive services, and prediction analysis. Consider this as a similar approach to real-time logging software applications.
- Performance Monitoring: Monitors the performance of the deployed ML model against the real-time or batch feed on the production environment and send trigger messages containing log or alert messages in any drop in performance is noticed.
Key Takeaways
It’s quite evident from the examples and techniques discussed above how MLOps improves the quality of a data solution. In startups with a smaller team, the traditional ML approach would work fine until there’s a scope to scale it up. Generally, developing an in-house solution requires additional resourcing; however, various platforms provide an automated solution without increasing the resources. Here are a few examples to check out:
- Azure MLOps: https://azure.microsoft.com/en-us/services/machine-learning/mlops/
- AWS Sagemaker: https://aws.amazon.com/sagemaker/mlops/
- GCP MLOps: https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
If you like this article, follow me for more relevant content. For a new blog, or article alerts click subscribe. Also, feel free to connect with me on LinkedIn, and let’s be part of an engaging network.
Data Science Essentials — MLOps was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


