



Credit Card Fraud Detection in R: Best AUC Score 99.2%
Last Updated on July 24, 2023 by Editorial Team
Author(s): Mishtert T
Originally published on Towards AI.
Fraud U+007C Anomaly Detection
Light GBM Model & Synthetic data points in an imbalanced dataset

What’s Light GBM
Light GBM is a high-performance gradient boosting (GBDT, GBRT, GBM or MART) framework and is used for classification, machine learning, and ranking related tasks.
Light GBM grows tree vertically while other algorithm grows trees horizontally.
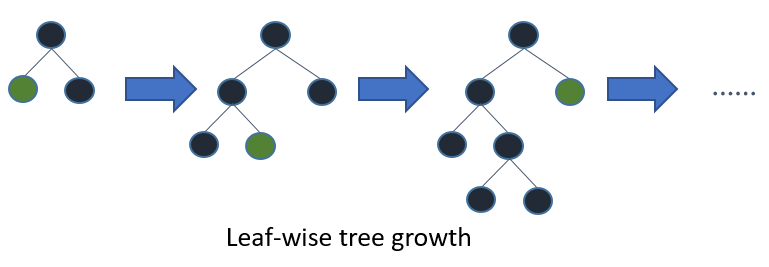
Light GBM grows tree leaf-wise while other algorithm grows level-wise. Leaf with max delta loss grows. By growing the same leaf, a leaf-wise algorithm can reduce more loss than a level-wise algorithm.
Light GBM is gaining attention because of its speed (the name Light in Light GBM implies speed) and known to use low memory with focus on accuracy and supports GPU learning.
Advantages:
- Faster training speed and Higher efficiency
- Low memory usage
- Better accuracy
- Parallel and GPU learning support
- Large scale data handling with ease.
Generally, it’s not advisable to use Light GBM for small datasets due to overfitting concerns.
In this article, Light GBM on SMOTE dataset used to explore how AUC improves vs. original imbalanced dataset.
About the data
Data used for this example is from Kaggle — Credit Card Fraud Detection
The datasets contain transactions made by credit cards in September 2013 by European cardholders. This dataset presents transactions that occurred in two days, where we have 492 frauds out of 284,807 transactions.
The dataset is highly unbalanced, the positive class (frauds) account for 0.172% of all transactions.
It contains only numerical input variables which are the result of a PCA transformation. Unfortunately, due to confidentiality issues, original features and more background information about the data was not provided.
Features V1, V2, … V28 are the principal components obtained with PCA, the only features which have not been transformed with PCA are ‘Time’ and ‘Amount’. Feature ‘Time’ contains the seconds elapsed between each transaction and the first transaction in the dataset.
The feature ‘Amount’ is the transaction Amount, this feature can be used for example-dependant cost-sensitive learning. Feature ‘Class’ is the response variable and it takes value 1 in case of fraud and 0 otherwise.
Accuracy of the model
Given the class imbalance ratio, It is recommended to measure the accuracy using the Area Under the Precision-Recall Curve (AUPRC). Confusion matrix accuracy is not meaningful for unbalanced classification. that Area Under the Precision-Recall Curve (AUPRC)
I have captured AUC here for this article for explanation purposes.
Load Libraries & Read Data
library(tidyverse) # metapackage with lots of helpful functions
library(lightgbm) # loading LightGBM
library(pROC) # to use with AUC
library(smotefamily) #create SMOTE dataset
library(RColorBrewer)#used for chart
library(scales) #used for chart
Reading the data and a quick check shows that the data is imbalanced as claimed with >99% data tagged as not fraud and <1% tagged as fraud transactions.

Not much of EDA was performed since the data has been anonymized and doesn’t contain any explainable features except for Time (between transactions which cannot be used meaningfully in my opinion), Amount & Class.
So it was decided to directly get into training the model and to predict with the test set.
First, the model was trained and tested with original imbalance data to understand the performance.
Light GBM Parameters for Original Data
Parameter tuning or whole set of available parameters for Light GBM are not discussed here since it’s not in scope of this article
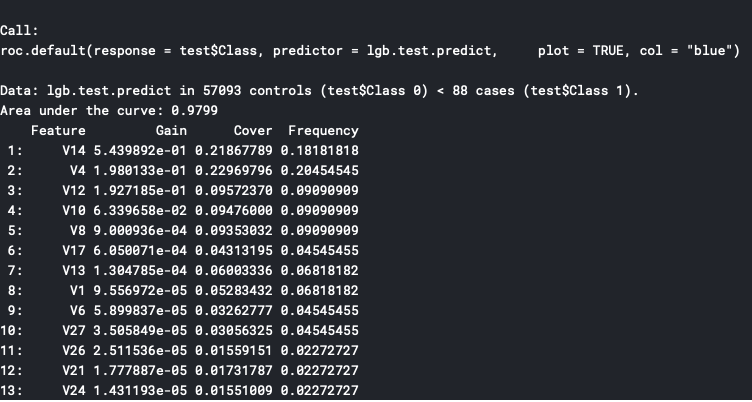
Selected “auc” as metric since confusion matrix may not be the right measure for accuracy for this dataset.

with simple parameter tuning, we were able to get 97.99% AUC with 13 features selected as important
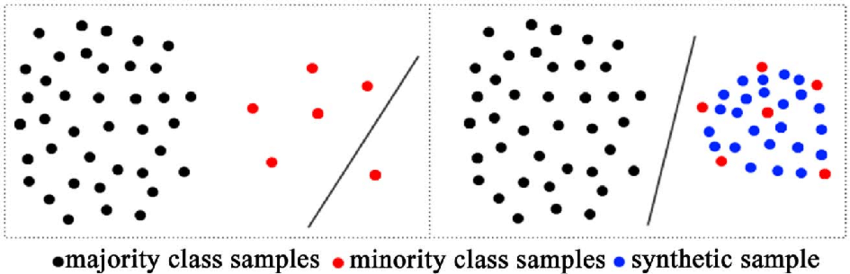
Synthetic Minority Oversampling Technique (SMOTE)
A statistical technique for increasing the number of cases in your dataset in a balanced way. The module works by generating new instances from existing minority cases that you supply as input. Newbies can read here for better understanding.
Creating data using SMOTE Technique

In the above picture, the first line of the code says that we expect non-fraud transaction data to be of 65% of overall transactions and rest 35% to be fraud transactions.
After generating new synthetic data points, the dataset contains ~35% of transactions tagged as fraud vs. the <1% transactions in the original dataset
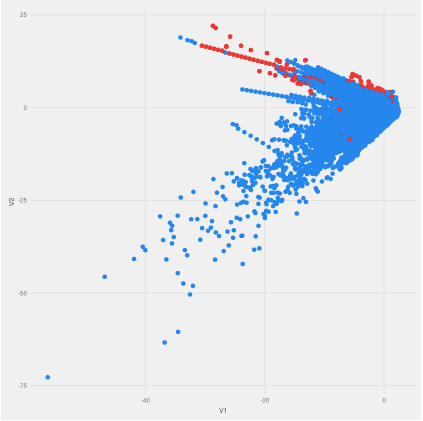
Visual Representation of Original data (Left) & with and SMOTE Implementation (Right)
After SMOTE implementation, it can be seen that more synthetic data has been generated in the neighborhood of the actual fraud transactions if you had seen the above code line, we had selected K=5 which would explain the concentration of new data points around the original ones.

Light GBM Parameters & Model Training with SMOTE Data

Parameter tuning was a little different than what was used for the original data to boost the AUC.

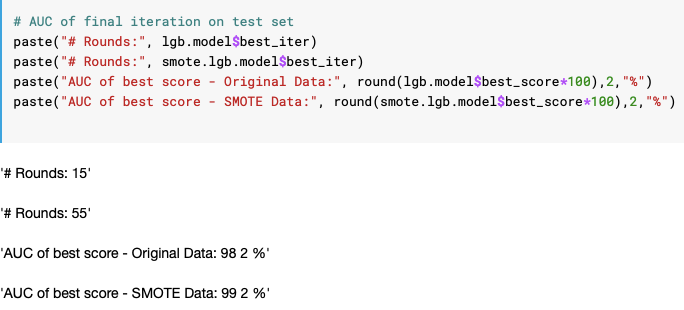
“The result was AUC of 98.21% with best score of 99.2% and 7 features captured as importance vs. 13 features for the original data.”
Feature importance Comparison
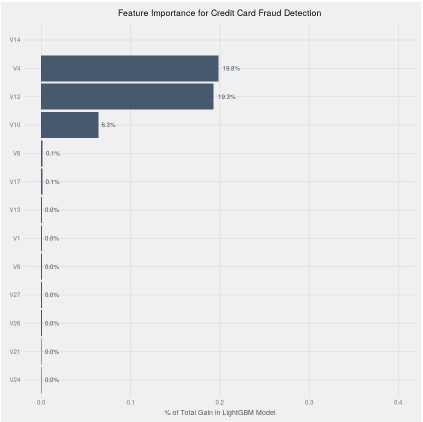

Comparison of AUC & Iteration & Best Score
The best AUC score for SMOTE data was 99.2% vs. 98.2%
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

