



COVID-19: Face Mask Detection Using Deep Learning and OpenCV
Last Updated on July 20, 2023 by Editorial Team
Author(s): Ravideep Singh
Originally published on Towards AI.
Computer Vision, Deep Learning, Data Science in the Real World
Construct a CNN model and check whether a person is wearing a mask or not in real-time
COVID-19 has affected the whole world very badly. It has a huge impact on our everyday life, and this crisis is increasing day by day. In the near future, it seems difficult to eradicate this virus completely.
To counter this virus, Face Masks have become an integral part of our lives. These Masks are capable of stopping the spread of this deadly virus, which will help to control the spread. As we have started moving forward in this ‘new normal’ world, the necessity of the face mask has increased. So here, we are going to build a model that will be able to classify whether the person is wearing a mask or not. This model can be used in crowded areas like Malls, Bus stands, and other public places.
Let’s get started with our Face Mask detector:
Step 1: Import libraries to be used:
import cv2,os
import numpy as np
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout, Conv2D, Flatten, MaxPooling2Dfrom keras.callbacks import ModelCheckpoint
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
from keras.models import load_model
Step 2: Add data path and label the categories:
For building this model, We will be using the face mask dataset provided by Prajna Bhandary. It consists of about 1,376 images with 690 images containing people with face masks and 686 images containing people without face masks.
#use the file path where your dataset is stored
data_path = r'C:\Users\admin\Desktop\face mask detection\face-mask-detector\dataset'categories = os.listdir(data_path)
labels = [i for i in range(len(categories))]label_dict = dict(zip(categories,labels))
print(label_dict)
print(categories)
print(labels)
Output:-

Step 3: Make lists for data and target:
img_size = 150
data = []
target = []for category in categories:
folder_path = os.path.join(data_path,category)
img_names = os.listdir(folder_path)
for img_name in img_names:
img_path = os.path.join(folder_path,img_name)
img = cv2.imread(img_path)
try:
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
resized = cv2.resize(gray,(img_size,img_size))
data.append(resized)
target.append(label_dict[category])
except Exception as e:
print("Exception: ",e)
The lists which are formed (data and target) are converted into NumPy arrays for easier data pre-processing. The data array is reshaped so that it can be given to Neural Network Architecture as an input. After that, these are saved as a .npy file.
data = np.array(data)/255.0 #data values are normalized#reshaping of data data = np.reshape(data,(data.shape[0],img_size,img_size,1))target = np.array(target)
new_target = np_utils.to_categorical(target)#saving the files np.save('data',data)
np.save('target',new_target)
Step 4: Build a Neural Network model:
First, we will load the data from the files that we created in the previous step. Then we are making a Neural network using Convolutional and MaxPooling layers. At last, the output is flattened and fed into a fully connected Dense layer with 50 neurons and finally into layers with 2 neurons as it will output the probabilities for a person wearing a mask or not, respectively.

data = np.load('data.npy')
target = np.load('target.npy')model = Sequential()
model.add(Conv2D(200,(3,3),input_shape=data.shape[1:]))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))model.add(Conv2D(100,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(50,activation='relu'))
model.add(Dense(2,activation='softmax'))model.compile(optimizer='adam', loss='categorical_crossentropy', metrics = ['acc'])model.summary()
Summary of the model is given below:

Step 4: Split the data and target and fit into the model:
The data and targets are then split into training, and testing data be keeping 10% of data as testing and 90% as training data.
train_data, test_data, train_target, test_target = train_test_split(data, target, test_size=0.1)
A checkpoint is created, which will save the model, which will have the minimum validation loss. Then the training data is then fitted in the model so that predictions can be made in the future.
checkpoint=ModelCheckpoint('model-{epoch:03d}.model', monitor='val_loss', verbose = 0, save_best_only = True,mode='auto')history = model.fit(train_data,train_target,epochs = 20, callbacks = [checkpoint], validation_split = 0.2)
After fitting the model, plot the accuracy and loss chart for training and validation data
plt.plot(history.history['acc'],'r',label='training accuracy')
plt.plot(history.history['val_acc'],'b',label='validation accuracy')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show()plt.plot(history.history['loss'],'r',label='training loss')
plt.plot(history.history['val_loss'],'b',label='validation loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend()
plt.show()

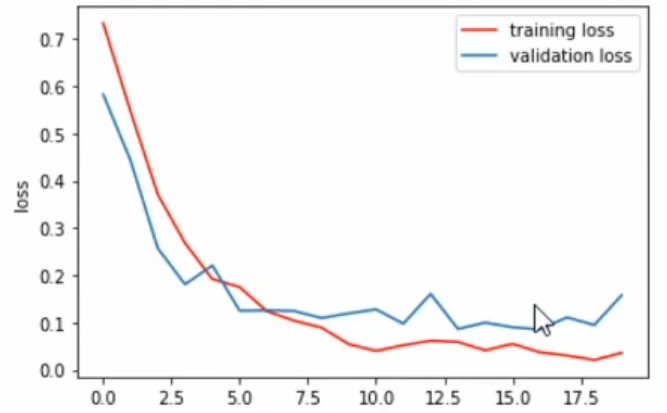
We can see some signs of overfitting that you can solve by tuning the parameters. Otherwise, this model will also work well in real-time.
NOTE:- Instead of making your own Neural network arch, you can use the arch available on the internet like ResNets, MobileNetV2, etc. They will certainly perform well.
Now, evaluate the model on test data:
print(model.evaluate(test_data,test_target))
Output:

We can see that the model is about 93% accurate on testing data with 0.309 loss.
Now we are good to apply this model in real-time.
Step 6: Using the model in real-time through webcam:
Firstly, load the model that was saved as the best model through a callback. Now we will use Haar Cascade Classifier to find the face in each frame of the video(use the path where you have stored your XML file). Also, make a label and color dictionary for two different classes i.e., mask and no mask.
You can download the XML file from the following link.
model = load_model('model-017.model') #load the best modelfaceCascade=cv2.CascadeClassifier(r'C:\Users\admin\Desktop\capstone\HaarCascade\haarcascade_frontalface_default.xml')video_capture = cv2.VideoCapture(0) #starts the webcam
labels_dict = {0:'NO MASK',1:'MASK'}
color_dict = { 0:(0,0,255),1:(0,255,0)}
In an infinite loop, capture each frame from the video stream and convert it into grayscale for better processing and apply the cascade to find the ROI (Region of Interest), in our case- faces. Resize and normalize each ROI image and give it to the model for prediction. Through this, you will get the probabilities for both mask and no mask. The one with a higher probability is selected. A frame is drawn around the face, which also indicates whether a person has worn a mask or not. To close the webcam, press the Esc button.
while(True):
ret,frame = video_capture.read()
gray = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(gray,1.3,5)
for x,y,w,h in faces:
face_img = gray[y:y+w,x:x+h]
resized = cv2.resize(face_img,(img_size,img_size))
normalized = resized/255.0
reshaped = np.reshape(normalized,(1,img_size,img_size,1))
result = model.predict(reshaped)
label = np.argmax(result,axis=1)[0]
cv2.rectangle(frame,(x,y),(x+w,y+h),color_dict[label],2)
cv2.putText(frame,labels_dict[label],(x,y-10),cv2.FONT_HERSHEY_SIMPLEX,0.8,(255,255,255),2)
cv2.imshow('Video',frame)
key=cv2.waitKey(1)
if(key==27):
break;
cv2.destroyAllWindows()
video_capture.release()

HURRAY !! We have developed a model that can depict whether a person has worn a mask or not. These types of models can be implemented in public places that would help the authorities to monitor the situation easily. I hope you enjoyed making this model and would love to see more in the future…. 🙂
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

