



Classification Using Monk AI by Using a Slice of the Dataset
Last Updated on July 20, 2023 by Editorial Team
Author(s): Shubham Gupta
Originally published on Towards AI.
Classification Using Monk AI by Using a Slice of the Dataset
In Machine Learning, Classification is a process of categorizing a given set of data into classes. It can be performed on both structured or unstructured data.
In this, I predicted a class of given data points. The classes are often referred to as target, label, or categories. The main goal is to identify which class or category the new data will fall into.
First, I tried to train the model on the dataset that I took, but as the dataset was quite large, it was a time-consuming process. Therefore I used a different approach. I trained it on some parts of the dataset using Monk AI.
One can also get to know whether their hyperparameters are allowing the network to converge or not.
There are various architectures available for Classification, But I used Densenet-121 whose architecture is given in the following figure:
For this task, I used iWildCam 2020 — FGVC7 Dataset, which is available for download on Kaggle on the given link. The dataset contains images of animals taken from camera traps across the globe, and the main objective is to classify the images.
Before we start, we need to install the MONK library and the requirements for the densenet-121 model.

· If you are using Colab, install using the commands below:
!cd monk_v1/installation/Misc && pip install -r requirements_colab.txt
· If you are using Kaggle, install using the commands below:
!cd monk_v1/installation/Misc && pip install -r requirements_kaggle.txt
· Select the requirements file as per OS and CUDA version when using a local system or cloud
!cd monk_v1/installation/Linux && pip install -r requirements_cu9.txt
This is the sample image from the dataset: –


Looks Cute!
Now we will import prototype to use gluon backend
The next step is to create and manage experiments.

In the next step, we will load the data and the model.

After loading the data and the model, use the following command to get the sample from the dataset, for instance, I have taken 3% of the whole dataset.
The sample dataset will be saved in CSV format, and the file name will be sampled_dataset_train.csv.

Now create and manage experiments and load the data and the model.

The model will run 6 times, and in each iteration, we will see how the accuracy of the model is improving.
For corrupt images, use the following command:

This command will help in finding the corrupt images in 3% of the dataset.
We can see, there are no corrupt images in 3% of the dataset.
In the next step, we will train the model on the training dataset.

The model will be trained on the training dataset.
After the training is done, we can run inferences on test images.

After running inferences, select any image and run inference on that image.
We will get the prediction of that image, which will give the category of the animal in that image.
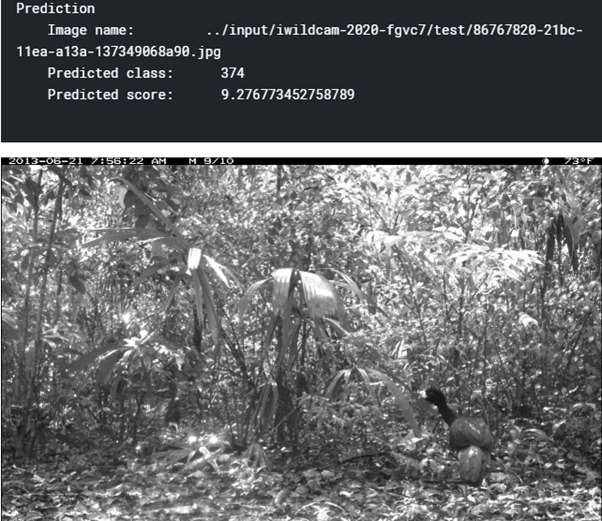
This model gives a decent accuracy on 3% of the dataset.
All the code in this article resides on this Github link
shubham7169/MonkAI
import NumPy as np # linear algebra import pandas as PD # data processing, CSV file I/O (e.g. PD.read_csv) import…
github.com
References
Monk AI GitHub repo — https://github.com/Tessellate-Imaging/monk_v1
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

