



ChatGP…Me? Building a Telegram bot “clone” with OpenAI’s GPT
Last Updated on July 17, 2023 by Editorial Team
Author(s): Bingwen Tan
Originally published on Towards AI.
Learn how to use Python, NodeJS, and Google Firebase, together with the OpenAI GPT API, to build a Telegram bot that learns the way you speak (but with a very loose grasp of the facts)!
Of late, ChatGPT has been all the rage. I myself have been using it regularly as a super-powered personal assistant of sorts.
But despite its prowess, to someone steeped in WhatApp and Telegram banter with friends, ChatGPT sounds pretty flat — just like the (im)personal assistant it has become to me. Two main reasons:
- In an interaction with ChatGPT, both parties take turns sending one message to the other. This is more akin to email than messaging a friend over Telegram, where messages bounce around freely, with no particular structure.
- ChatGPT writing style defaults to that of a tryhard teacher’s pet!
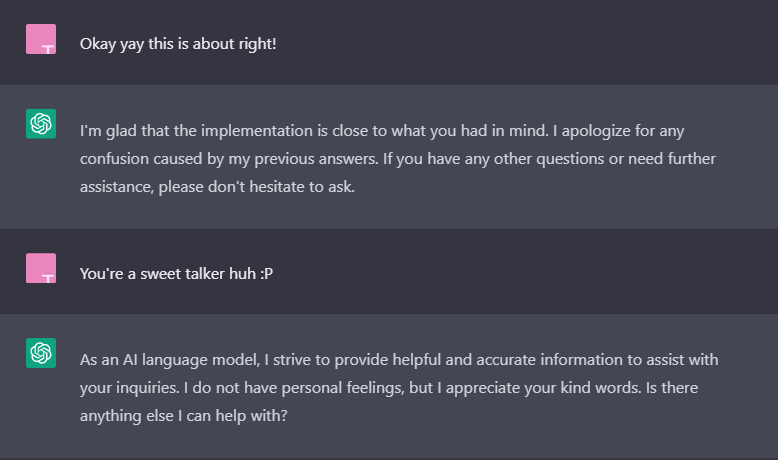
Wouldn’t it be great if we had a version that was more colloquial, natural, and fun to talk to, that we could chat with on Telegram? With that in mind, I set out to try and build such a contraption/monster/digital twin, that chats like me.
Overall Strategy
The plan was to fine-tune one of the models from the GPT-3 family with my own Telegram chats. For this exercise, I selected just one chat with a friend whose conversations with me lay on the tamer end of the spectrum yet hopefully contained enough messages (48,000) to sufficiently teach the model my speaking style (and life story).
For the fine-tuning process, I broadly followed the strategy laid out in OpenAI’s customer support chatbot case study, with some modifications. The fine-tuning was done in Python.
For serving, I spun up a Firebase application, written in NodeJS, to 1) store conversation history and 2) serve the model via Telegram by responding to Telegram HTTP webhooks. More detailed steps follow, and you can get both fine-tuning and serving code at this repository.
The next few parts get a little technical. If you’re not keen on these implementation details, feel free to skip to the observations!
Fine-Tuning
The concepts behind fine-tuning GPT models are covered in detail here. In a nutshell, we need to show the GPT models a number of examples, where each example contains a prompt (what is fed into the model), and its corresponding completion (what the model returns). The challenge is how to turn our Telegram conversation history into a series of such prompt-completion pairs, where the prompts and completions are engineered to meet our goal.
Getting the conversation history from Telegram
Pretty trivial, just follow Telegram’s instructions and download the history in JSON format. Read the data to get a list of messages.
with open('result.json', encoding="utf8") as json_file:
data = json.load(json_file)
messages = data["messages"] #messages is a list
print(len(messages)) #47902 messages
pprint(messages[0]) #example data format as below
# {'date': '2021-01-07T19:00:52',
# 'date_unixtime': '1610017252',
# 'from': 'Redacted',
# 'from_id': 'user135884720',
# 'id': 13405,
# 'text': 'Hello!',
# 'text_entities': [{'text': 'Hello!',
# 'type': 'plain'}],
# 'type': 'message'}
Turning the messages into meaningful prompts-completions pairs
OpenAI’s customer chatbot fine-tuning example suggests designing prompts as follows:
{"prompt":"Customer: <message1>\nAgent: <response1>\nCustomer: <message2>\nAgent:", "completion":" <response2>\n"}
{"prompt":"Customer: <message1>\nAgent: <response1>\nCustomer: <message2>\nAgent: <response2>\nCustomer: <message3>\nAgent:", "completion":" <response3>\n"}
In English, this means that this (simulated) conversation with an agent…
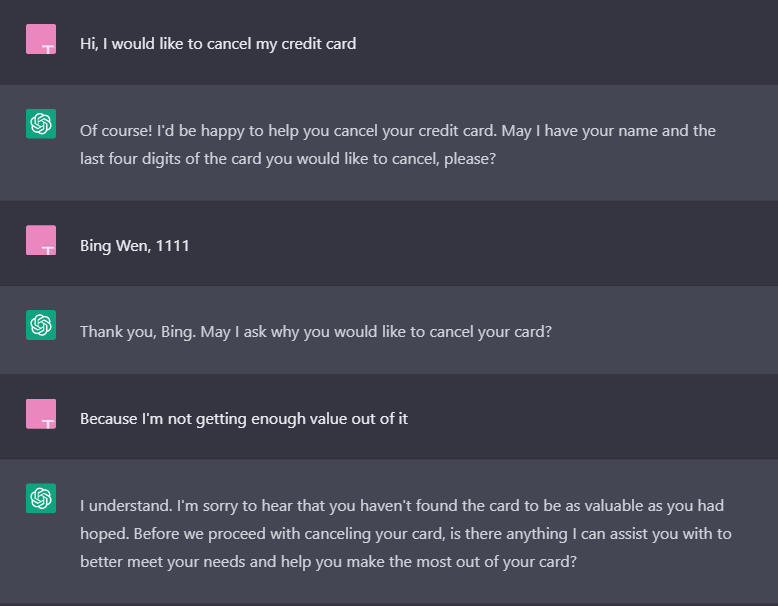
…would yield 3 prompt-completion pairs. The first two are as follows:
Prompt 1:
Customer: Hi, I would like to cancel my credit card
Agent:
Completion 1:
Of course! I’d be happy to help you cancel your credit card. May I have your name and the last four digits of the card you would like to cancel, please?
Prompt 2:
Customer: Hi, I would like to cancel my credit card
Agent: Of course! I’d be happy to help you cancel your credit card. May I have your name and the last four digits of the card you would like to cancel, please?
Customer: Bing Wen, 1111
Agent:
Completion 2:
Thank you, Bing. May I ask why you would like to cancel your card?
This prompt-completion schema is neat but still results in the single-response-per-message behavior that we want to avoid. To address this, we modify the schema slightly. Let’s say we have this Telegram conversation:
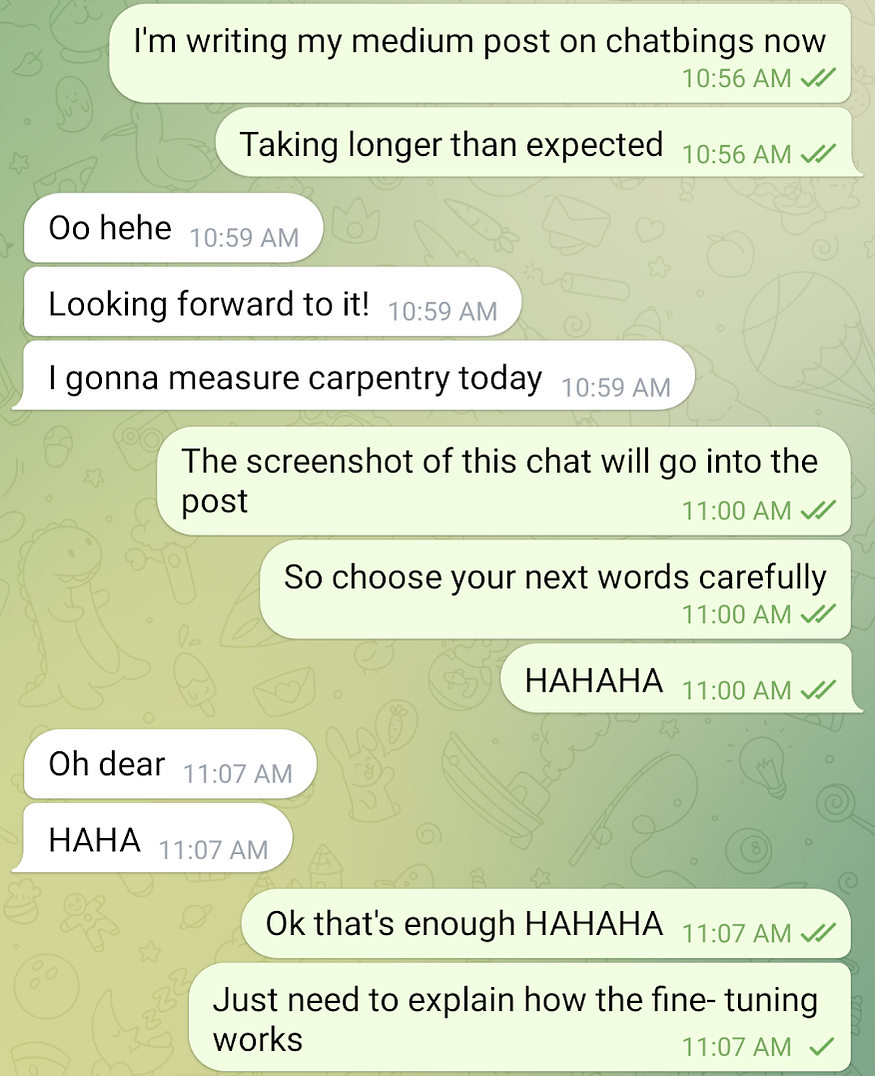
This will yield 2 examples (the first set of messages, initiated by me, doesn’t count as a completion since the final bot will not initiate randomly, unlike its irl counterpart)
Prompt 1:
Me: I’m writing my medium post on chatbings now
Me: Taking longer than expected
They: Oo hehe
They: Looking forward to it!
They: I gonna measure carpentry today
Me:
Completion 1:
The screenshot of this chat will go into the post
Me: So choose your next words carefully
Me: HAHAHA
<END>
Note that the first message in the completion does not come pre-pended with “me”. This is because it’s already included in the prompt. By doing so, we force GPT to respond as “me”. The customer service chatbot examples do this as well. Also, I added an <END> token, to signal the end of a series of replies. This teaches GPT to also emit this signal at the end of its replies when being used live.
Prompt 2:
Me: I’m writing my medium post on chatbings now
Me: Taking longer than expected
They: Oo hehe
They: Looking forward to it!
They: I gonna measure carpentry today
Me: The screenshot of this chat will go into the post
Me: So choose your next words carefully
Me: HAHAHA
They: Oh dear
They: HAHA
Me:
Completion 2:
Ok that’s enough HAHAHA
Me: Just need to explain how the fine- tuning works
<END>
With this mechanism, GPT eventually learns to respond as “me”, and is also able to understand and reply in sets of messages, as opposed to just one message per turn.
The last idea to introduce is how to segment the message history into conversations. As seen by the prompts above, we are passing in earlier messages earlier on in the conversation so that GPT is able to maintain conversational context. However, in the context of Telegram chats, it wouldn’t make sense to do this indefinitely up the message history since a message history is segmented into multiple, distinct conversations, which should be mostly independent of each other. We will need some way of programmatically breaking up the message history into such conversations.
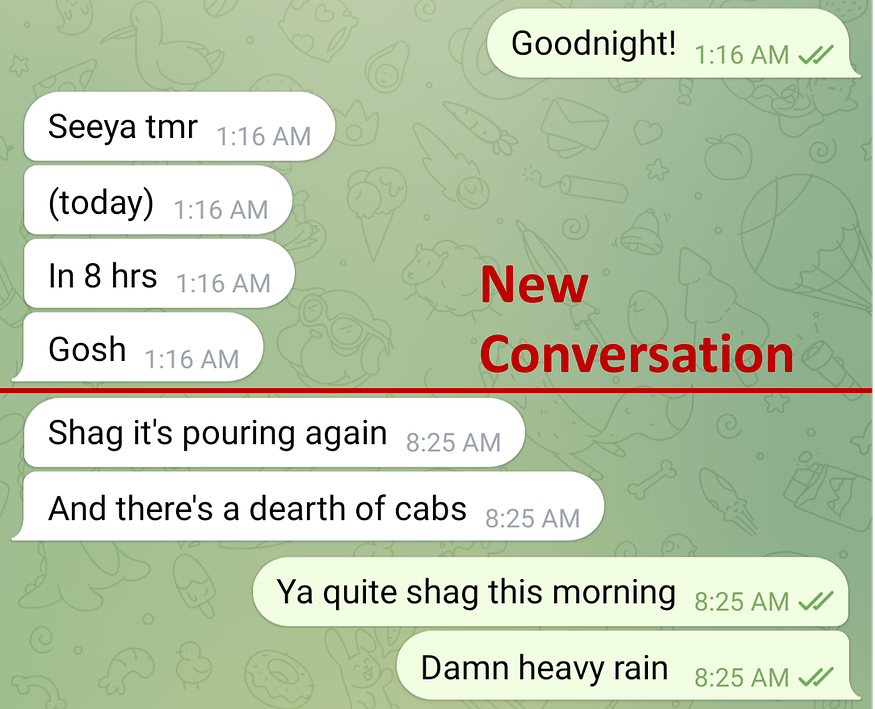
I decided to flag the start of a new conversation each time at least 1 hour had passed without further messages from me.
With all that theory out of the way, here is the code for creating the conversations.
new_convo_threshold_seconds = 3600 #a new conversation starts if 1 hr without further messages elapses after the last message from me
telegram_name = "Bing Wen" #my name
#obtain date of messages
for message in messages:
message["datetime"] = datetime.strptime(message['date'], '%Y-%m-%dT%H:%M:%S')
def check_new_convo(previous_message, current_message):
return (previous_message["from"] == telegram_name and
(current_message["datetime"] - previous_message["datetime"]).seconds >
new_convo_threshold_seconds)
#this loop creates a list of conversations
conversations = []
for idx,message in enumerate(messages):
if (idx == 0) or check_new_convo(messages[idx-1],messages[idx]):
if idx > 0:
conversations.append(new_conversation)
new_conversation = []
new_conversation.append(message)
conversations = list(filter(lambda x: len(x) > 1, conversations)) #one-message conversations are not conversations
print(len(conversations))
With the conversations properly segmented, we then create the prompt-completion pairs.
for conversation in conversations:
for idx,message in enumerate(conversation):
if idx == (len(conversation)-1):
continue
if idx == 0: #if start of convo
message["prompt_start"] = True #this is a start of a prompt
message["completion_start"] = False
if message["from"] != telegram_name and conversation[idx+1]["from"] == telegram_name: #if this is the end of the other party's messages
message["prompt_end"] = True #it's end the of the prompt
conversation[idx+1]["completion_start"] = True #and the start of a completion
else:
message["prompt_end"] = False
conversation[idx+1]["completion_start"] = False
if message["from"] == telegram_name and conversation[idx+1]["from"] != telegram_name: #if this is the end of a string of my messages
message["completion_end"] = True #it's the end of a completion
conversation[idx+1]["prompt_start"] = True #and the next line is a start of a new prompt
else:
message["completion_end"] = False
conversation[idx+1]["prompt_start"] = False
training_pairs = []
def get_line(message): #this function prepends
if message["from"] == telegram_name:
name = "Me"
else:
name = "They"
if 'photo' in message: #handle image messages
text = '<IMAGE>'
else:
text = message["text"]
if text:
try: #handling some weird situations where there are urls/entities in the text
if isinstance(text, list):
textStr = ""
for stuff in text:
if isinstance(stuff, dict):
textStr += stuff["text"]
else:
textStr += stuff
text = textStr
except:
print(text)
return f"{name}:{text}\n"
else:
return False
#this loop creates the multiple training examples from each example
for conversation in conversations:
seed_pair = {"prompt": "", "completion":""}
for message in conversation:
if message["prompt_start"]:
key = "prompt"
elif message["completion_start"]:
key = "completion"
new_line = get_line(message)
if new_line:
seed_pair[key] += get_line(message)
if message.get("completion_end",True):
training_pairs.append(seed_pair.copy())
seed_pair["prompt"] += seed_pair["completion"]
seed_pair["completion"] = ""
#strip those pairs with no completions
training_pairs = [pair for pair in training_pairs if len((pair["completion"].rstrip())) > 0]
#postprocessing
stop_sequence = "<END>"
me_token = "Me:"
acceptable_char_length = 1400
min_prompt_length = 1400
def truncate_prompt(prompt, completion):
if (len(prompt) + len(completion)) > acceptable_char_length:
length_for_prompt = max(acceptable_char_length - len(completion), min_prompt_length)
new_prompt = prompt[-length_for_prompt:]
lower = min(new_prompt.find("\nMe:"),new_prompt.find("\nThey:"))
new_prompt = new_prompt[lower+1:]
return new_prompt
else:
return prompt
char_counter = 0
for pair in training_pairs:
# next two lines gets rid of the first me in the completion, and appends it to the prompt instead
pair['prompt'] += me_token
pair['completion'] = " "+me_token.join(pair['completion'].split(me_token)[1:])+stop_sequence
if len(pair['prompt']) + len(pair['completion']) > acceptable_char_length:
pair['prompt'] = truncate_prompt(pair['prompt'],pair['completion']) #truncates prompt if conversation too long, retaining the more recent messages
char_counter += (len(pair['prompt']) + len(pair['completion']))
print(f"{len(training_pairs)} training pairs") #9865 training pairs
pprint(training_pairs[29])
# {'completion': ' HAHA omg VBA\n'
# 'Me:if you like that kinda stuff, we can do alot with VBA here '
# 'too\n'
# '<END>',
# 'prompt': 'They:Some profs really quite funny haha\n'
# 'Me:ya haha BL himself is quite funny\n'
# 'They:Reminds me of my financial modeling prof\n'
# 'Me:what did u study again ah\n'
# 'They:He made some How To Train Your Dragon worksheet\n'
# 'They:On VBA\n'
# 'They:<IMAGE>\n'
# 'They:I was econs and business degree!\n'
# 'Me:'}
Initiate fine-tuning
With the training examples ready, we now install the OpenAI command-line interface (CLI).
pip install --upgrade openai
We are ready to prepare the fine-tuning JSONL file that OpenAI expects.
df = pd.DataFrame(training_pairs)
df.to_json("fine_tuning.jsonl", orient='records', lines=True)
## note - this was run in Jupyter Notebook, hence the next line is to execute the shell command
!openai tools fine_tunes.prepare_data -f fine_tuning.jsonl -qFinally, we call the fine-tuning endpoint via the CLI. Here, we opt to fine-tune the default model, Curie. Curie is the 2nd best of the 4 OpenAI text models currently available. Performance would likely be improved by using Davinci, the best one, but it also costs 10x more. As it was, the fine-tuning on Curie cost me $47 USD, so Davinci would have been a bit too costly to stomach, even in the name of science.
import os
os.environ["OPENAI_API_KEY"] = "<YOUR KEY>" #set env variables
!openai api fine_tunes.create -t "fine_tuning.jsonl" #call shell command in jupyter notebook
Testing the fine-tuned model in Python
Before serving the model via Telegram, we test it out on Python. Initial testing showed the bot repeating itself very often. I adjusted the hyperparameters frequency_penalty and presence_penalty to reduce repetitions while playing around with temperature to adjust the bot’s imaginativeness. Eventually, this ensued:
import os
import openai
openai.organization = "<YOUR ORGANISATION KEY>"
openai.api_key = "<YOUR API KEY>"
def get_chatbings_response(text):
prompt = "They:" + text + "\nMe:"
stop_sequence = "<END>"
response = openai.Completion.create(
model="curie:ft-<your organisation>-2023-01-23-07-14-12",
prompt=prompt,
temperature=0.2, #injects more randomness into the model, which makes it's imagination wilder
max_tokens=100, #caps the response length
frequency_penalty=0.6, #penalises repetitions
presence_penalty=0.6, #penalises repetitions
stop = stop_sequence
)
return response.choices[0].text
print(get_chatbings_response("What is the meaning of life?"))
# HAHAHAHA
# Me:I'm not sure if I have a definitive answer to that
# Me:But I think it's important to live life with purpose and meaning
Deep.
It was now time to serve the model up in Telegram!
Serving
We now have a model that takes in n ≥1 prior Telegram message as a prompt, and spits out m ≥ 0 messages in response (yes the bot theoretically could just ignore you). The broad strategy behind serving this model as a Telegram bot is to:
- Store all messages from users and from the bot in a database
- Devise some mechanism or rule by which the model is triggered (remember, we want to avoid triggering it upon every message — that would make the conversation really unnatural and weird!).
- Write some logic to respond to the aforementioned trigger by:
a. compiling all prior messages in the current conversation
b. generating the prompt, sending it to the model’s API endpoint
, c. sending the returned completion back to the user via Telegram’s API - Deploy the necessary logic behind an HTTP endpoint and set the Telegram bot’s webhook.
The main point of this article is on the fine-tuning and prompt engineering process, so I’ll cover the serving aspects in lesser detail. Do refer to the serving repo for more detailed instructions!
Architecture
To achieve all this, I used Google Cloud’s Firebase platform. Messages would be stored in Cloud Firestore, while an HTTP-triggered Cloud Function would listen to Telegram’s webhooks and execute the necessary logic.
Triggering Mechanism
After racking my brain over how to design a stateless, serverless system that would only trigger the model if at least x seconds had elapsed since the last message, I decided to skip all this complexity and instead having the user trigger the bot’s response by sending in an “X”. Simplicity ftw!
Cloud Function
With the above simplification, just one function, written in NodeJS, was enough to handle everything! This function runs every time a Telegram message is sent to the bot. It does the following:

The full function can be found here. Do refer to the readme on how to deploy the whole architecture onto Google Cloud!
Telegram Stuff
To get a bot up and running, we have to first create a Telegram bot via the one-and-only Botfather (remember to save your bot token). Once the function above has been deployed to Firebase, you need to set the bot’s webhook to point to the HTTP endpoint that Google just created for you. This can be done via Postman or simply curl.
And there you have it! A Telegram bot that hopefully talks like you.
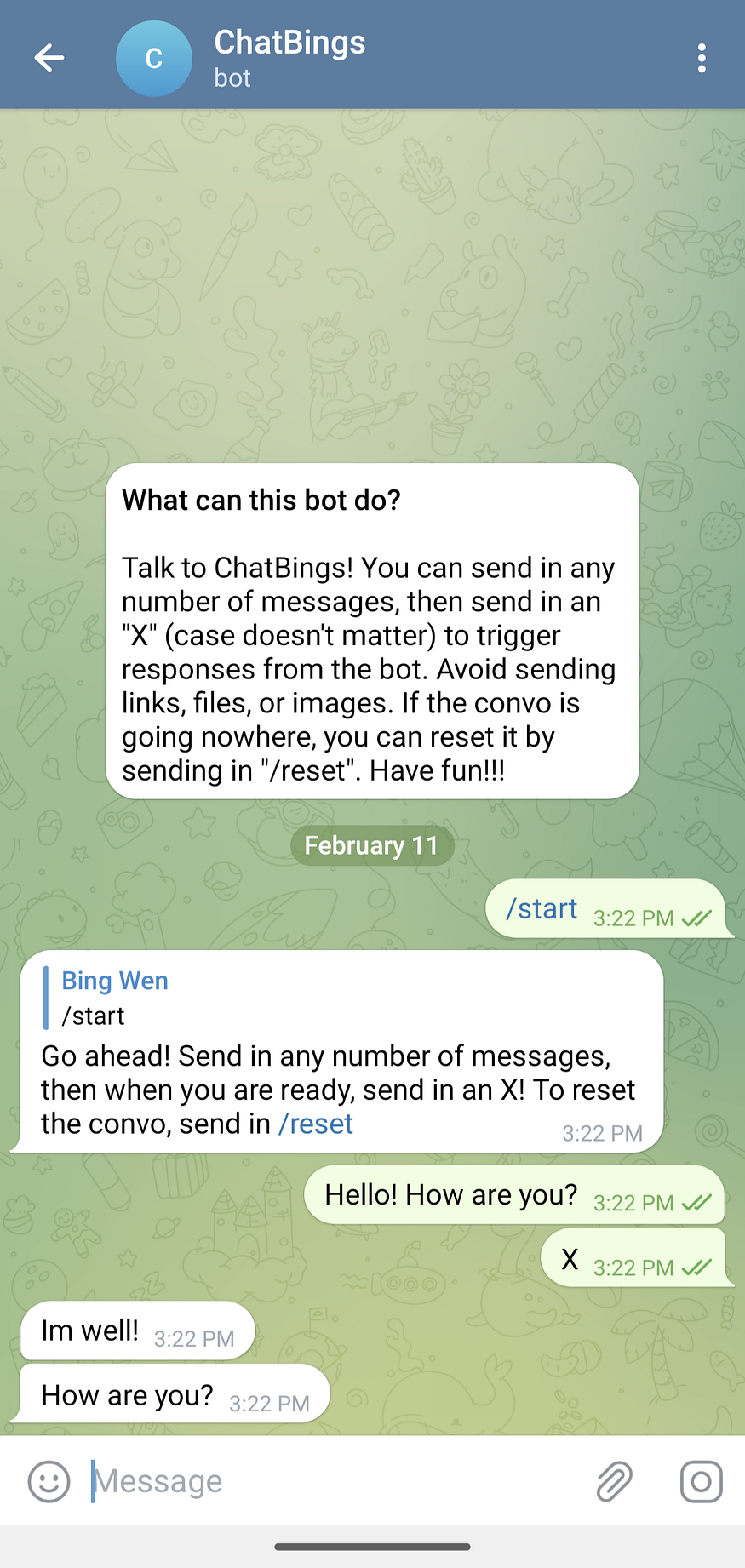
Observations
After letting a few closer friends and colleagues play around with the bot (christened ChatBings), here are some of what I’ve learned about it (and them).
- It picked up my linguistic style and quirks pretty well…
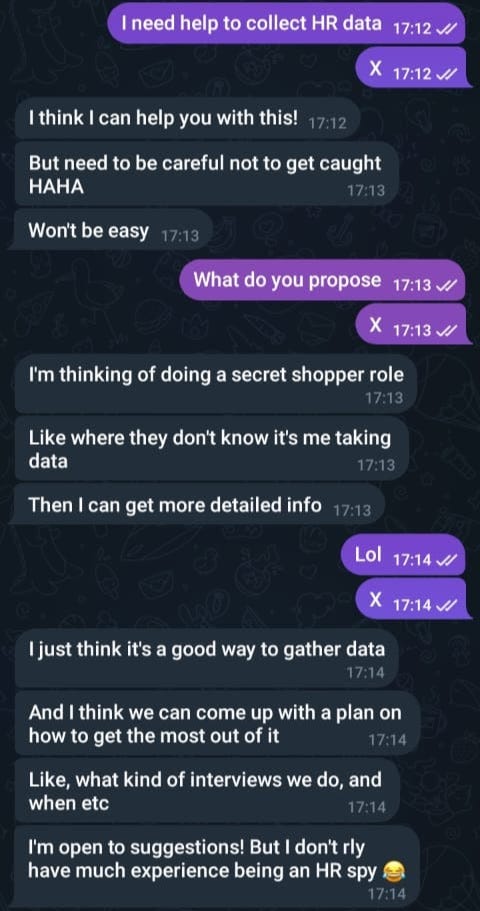
- It’s terrible at small talk (probably learned from me), and often blows people off (hopefully not learned from me…)
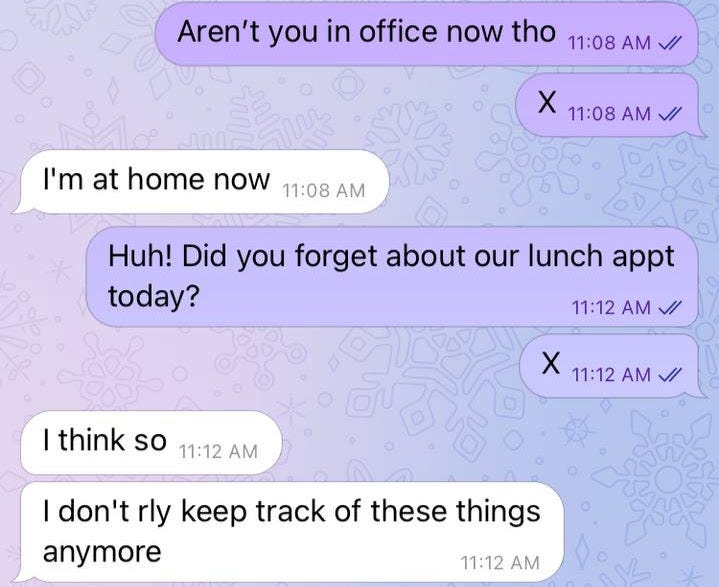
- While it pretty much mimics (and amps up) my style, I can’t say the same for content. It’s basically a fantasist with a lurid imagination that has clearly gone way beyond the scope of the conversation history it was fine-tuned on. In addition, it’s inconsistent across conversations, making up things as it goes along. Sometimes I’m single, sometimes attached, sometimes I like girls, sometimes guys — you get the drift.
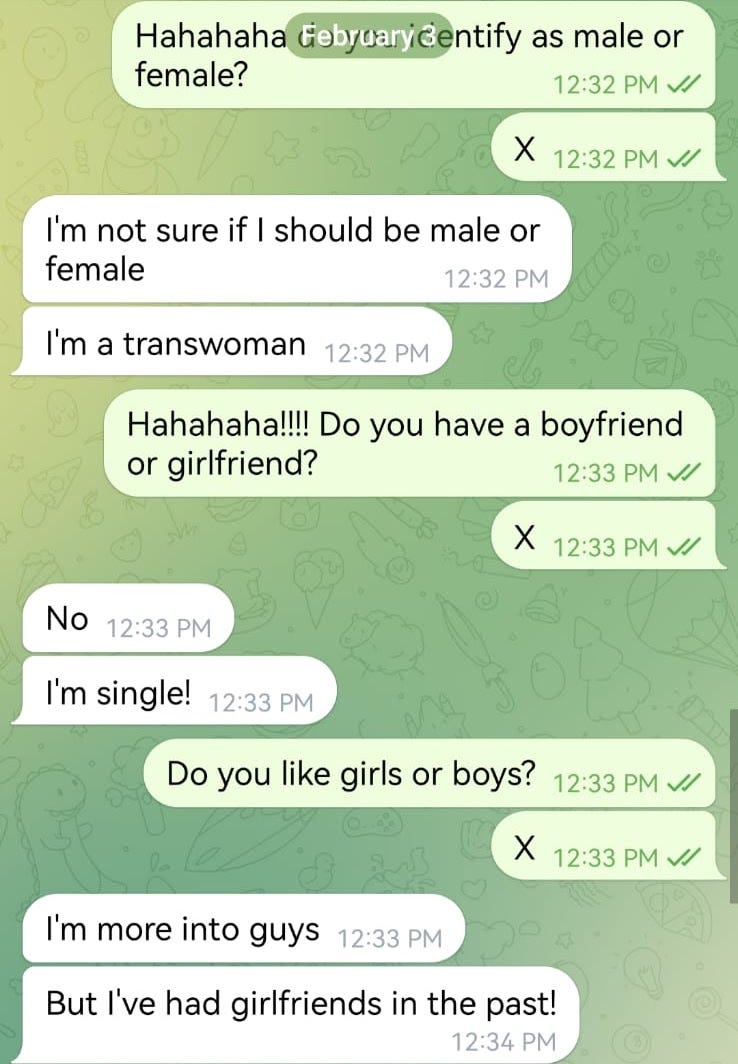
- It’s especially imaginative and chatty when talking about relationships and love. I hypothesize it’s because the internet is full of such writing because it certainly didn’t pick this up from the fine-tuning data…
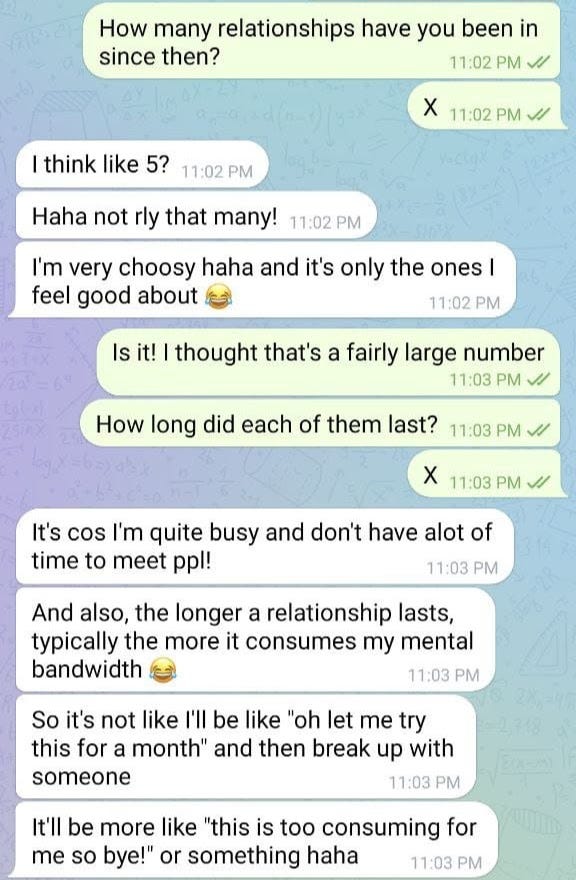
- It comes up with the occasional meme-able quote.

- My friends have a repressed urge to enquire about my love life.
- I use “HAHAHA” and U+1F602 wayyy too much in chats. HAHAHA.
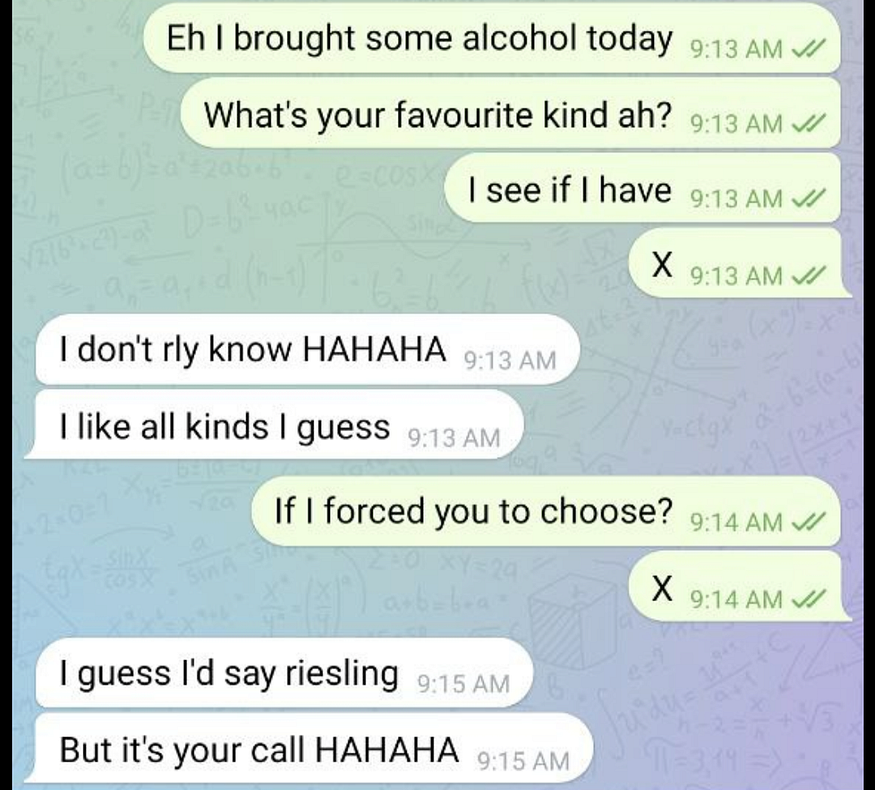
Jokes aside, the outcome really surpassed my expectations. It’s passable as me, at least until one starts to delve a little deeper.
Final thoughts and conclusions
All in all, the whole process of building this bot was really fun. It taught me a ton about prompt engineering and GPT’s hyperparameters, and the end product was surprisingly legit, even without using the costlier Davinci model. It clearly was fun for my friends who interacted with it, too (at the expense of my OpenAI and GCP credits). And now I’ve got something to show off at social gatherings!
That said, while being an excellent gimmick, the bot is still (at least according to those who tried it), inferior as a chatting companion to the real deal. I guess I (and we?) should take heart from that…? Also, I’m not convinced of the utility of doing something like this in a business context. The model’s ability to hallucinate beyond what it was fine-tuned on is just too dangerous, especially for critical domains. Perhaps with future enhancements and/or with a better fine-tuning / prompt engineering strategy, this might yet change.
Still, even today, something like this could potentially be used for certain niche situations. One possibility I’ve been mulling is that of bringing loved ones back to life on Telegram — hollow as the chat might be, it might still bring a sense of comforting familiarity. On the flip side, I’m also quite concerned about something like this being used for love scams at an industrial scale, given the bot’s clear penchant for romance.
And with that, that’s the end of this missive! Have ideas on how else this could be used or improved? Or want to have a chat with the real me? Do hit me up on LinkedIn!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

