



Can Julia replace Python? A Data Comparison
Last Updated on February 24, 2022 by Editorial Team
Author(s): Vivek Chaudhary
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Can Julia replace Python? A Data Comparison
Creators of Julia language claims Julia to be very fast, performance-wise as it does not follow the two language theory like Python, it is a compiled language whereas Python is an amalgamation of both compilation and interpretation. It would be interesting to dig deep to understand how both of these languages behave behind the scenes but the objective of this blog is not to get into the theoretical details of the differences.
As a Data Engineer, my innate behavior is to understand how Julia behaves when it is bombed with GBs or TBs of data sets. As I am talking about GBs or TBs of data sets so obviously I can not straight away compare Python with Julia or even the rich Pandas library, as all of us know the processing will never complete as python is quite slow. So the scope of this blog is to draw parallels between Julia and PySpark, I know for some this is unfair but pardon me. The inspiration behind the blog is the Twitter podcast on Julia that took place in Jan 2022.
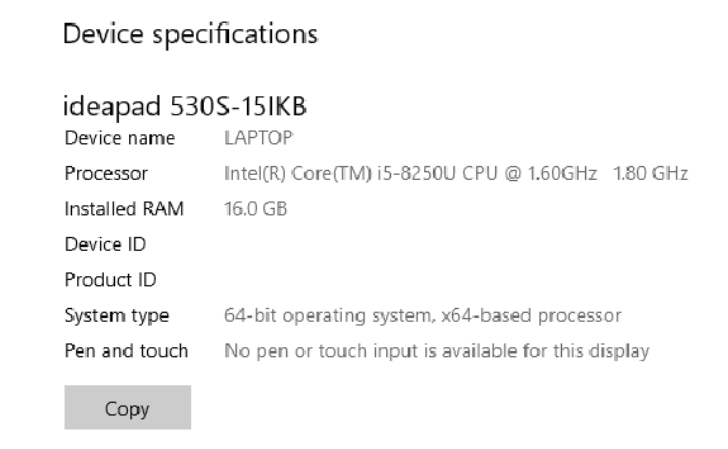
#Note: I have done this R&D on my personal laptop so that performance of both languages can be measured on same grounds.
My System configuration:
Softwares used in Demo:
I have used a CSV file of 6.5 GB in size, python 3.6 and spark 2.3.3, and Julia 1.7.1 all of the software is installed on my local system.
In this analysis, no data manipulation has been performed, just basic R/W operations to keep it simple and straight.
- Pyspark
#import libraries and connect to spark session
from datetime import datetime
t1 = datetime.now()
import findspark findspark.init(‘D:\spark-2.3.3-bin-hadoop2.7’) import pyspark from pyspark.sql
import SparkSession
print(‘modules imported’)
spark= SparkSession.builder.appName(‘BigData’).getOrCreate()
print(‘app created’)
#read the source dataset
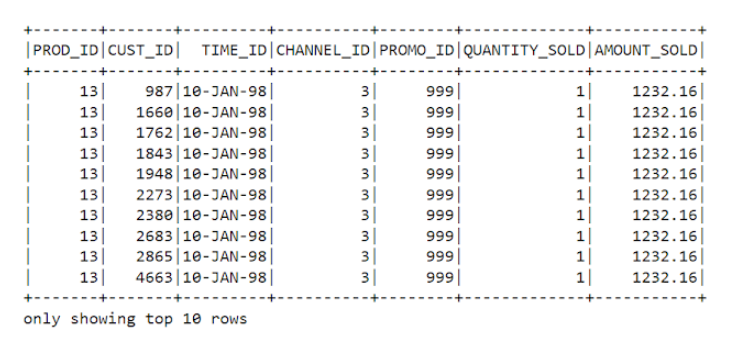
sales_df= spark.read.csv(r”D:\python_coding\Sales Data\sales_data.csv”, inferSchema=True)
sales_df.show(10) #write dataset to target csv file sales_df.write.format(‘csv’) \
.option(‘header’,’true’) \
.save(‘D:\python_coding\Sales Data\spark_emp.csv’, mode=’overwrite’)
t2 = datetime.now()
print(str((t2 — t1).total_seconds() * 1000) + ‘ milliseconds’)
#Time taken by Pyspark for Read Write operation of 6.5GB csv file: 344340.066 milliseconds
Output:
2. Julia
#import libraries
using CSV
using DataFrames
using Dates
d1=now()
#read the source dataset
sales=CSV.read("D:\\python_coding\\Sales Data\\sales_data.csv",DataFrame)
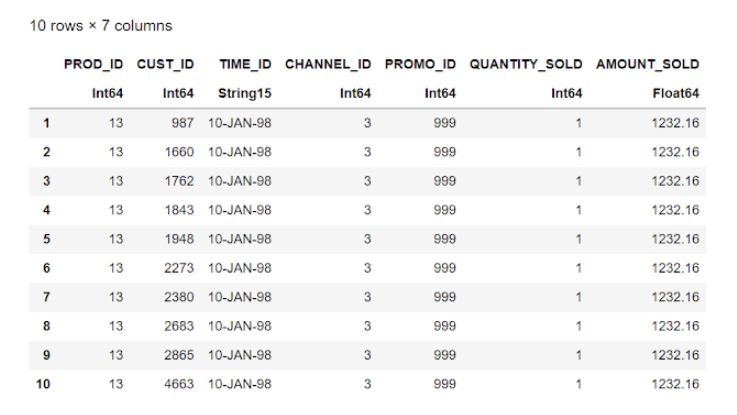
#print first 10 rows of julia dataframe
first(sales,10)
#write dataframe as csv file
CSV.write("D:\\python_coding\\Sales Data\\julia_sale.csv.csv", sales)
d2=now()
print(d2-d1)
#Time taken by Julia for Read Write operation of 6.5GB csv file: 453396 milliseconds
Output:
The Time taken by Julia to process 6.5GB of data is around 453396 milliseconds, whereas the processing time for Pyspark is 344340.066 milliseconds.
Time Difference is around 109,055.934 milliseconds or 109.055934 seconds or 2 mins approximately, which seems to be quite good because Julia has almost approached the performance speed of parallel computing framework Pyspark.
And who knows what is there in the womb of the future, someday Julia may become an alternative to Spark to process big data. Anything is possible and possibilities are endless.
I hope I have put my point in a rational manner with facts and figures for this particular use case. In case I missed out on anything, please share your feedback and I would be very happy to include the points.
To Summarize:
- Software used: Python 3.6, spark 2.3.3, and Julia 1.7.1.
- The data set size is 6.5GB.
Github link for Notebook and Dataset: https://github.com/viv07/PythonDataEngg/tree/main/PythonVSJulia
Courtesy: https://letscodewithvivek.blogspot.com/2022/02/julia-vs-python-data-comparison.html
Please follow me on blogspot @ https://letscodewithvivek.blogspot.com/
Programming was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

