



By the End of the Year 3000, iPhone Width Will Exceed 1 Meter, AI Predicts
Last Updated on December 2, 2021 by Editorial Team
Author(s): Michelangiolo Mazzeschi
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Data Science
Testing the prediction capabilities of AI. Full code available at my repo.
Join our FREE programming community on discord and meet other programmers in Python Kai!
AI is a wonder, there is no doubt. Since people understood its prediction capabilities, have been using it for good. So, here is the deal, I will actually pretend to be serious in this article and you will read pretending that whatever has been predicted by an AI will be a plausible scenario for the future.
How did we come to such drastic predictions? Is it going to be the end of the iPhone, and consequently of Apple, as we know it? Most importantly, how do we even create an AI that is specialized in predicting the iPhone size of a model of a certain date in time?
Gathering the data
The answer is quite simple, actually. We begin by collecting the data of every available iPhone model. Originally, the plan was to make a comparison of different models per company, showing the rate of growth of smartphones sizes over time. The data gathering, however, proved to be too challenging, and I had to limit myself to Apple products.
As you can see, the results are quite promising. Thanks to the change of route starting from blackberries, phones started becoming bigger rather than smaller. If that was the case, right now I would be writing about the estimation of when ant-man could have used his phone in the MCU quantum realm.

Preprocessing the data
Jokes apart (I doubt the content in question would get more serious), these are the size of the iPhone from the model 5.0 over the years. By copying and pasting the string from the website, this was the result.
str1 = 'iPhone 12 Pro Max,6.7in,160.8 x 78.1 x 7.4 mm,iPhone 12 Pro,6.1in,146.7 x 71.5 x 7.4 mm,iPhone 12 ,6.1in,146.7 x 71.5 x 7.4 mm,iPhone 12 Mini ,5.4in,131.5 x 64.2 x 7.4 mm,iPhone SE (2020),4.7in, 138.4 x 67.3 x 7.3mm,iPhone 11 Pro Max,6.5in, 158 x 77.8 x 8.1mm,iPhone 11 Pro ,5.8in,144 x 71.4 x 8.1 mm,iPhone 11,6.1in, 150.9 x 75.7 x 8.3 mm,iPhone XS Max,6.5in,157.5 x 77.4 x 7.7 mm,iPhone XS,5.8in,143.6 x 70.9 x 7.7 mm,iPhone XR,6.1in,150.9 x 75.7 x 8.3 mm,iPhone X,5.8in,143.6 x 70.9 x 7.7 mm,iPhone 8 Plus,5.5in,158.4 x 78.1 x 7.5 mm,iPhone 8 ,4.7in,138.4 x 67.3 x 7.3 mm,iPhone 7 Plus,5.5in,158.2 x 77.9 x 7.3 mm,iPhone 7 ,4.7in,138.3 x 67.1 x 7.1 mm,iPhone 6s Plus ,5.5in,158.2 x 77.9 x 7.3 mm ,iPhone 6s,4.7in,138.3 x 67.1 x 7.1 mm,iPhone SE / iPhone 5 / iPhone 5s,4.0in,123.8 x 58.6 x 7.6 mm'
Before processing the data, we need to make changes to its format. By using the following algorithm, I was able to split the data into a list of measurements.
the_list = str1.split(',')
list_of_groups = zip(*(iter(the_list),) * 3)
t = list()
for a in list_of_groups:
t.append(a)
t
Output:
[('iPhone 12 Pro Max', '6.7in', '160.8 x 78.1 x 7.4 mm'),
('iPhone 12 Pro', '6.1in', '146.7 x 71.5 x 7.4 mm'),
('iPhone 12\xa0', '6.1in', '146.7 x 71.5 x 7.4 mm'),
('iPhone 12 Mini\xa0', '5.4in', '131.5 x 64.2 x 7.4 mm'),
('iPhone SE (2020)', '4.7in', ' 138.4 x 67.3 x 7.3mm'),
('iPhone 11 Pro Max', '6.5in', ' 158 x 77.8 x 8.1mm'),
('iPhone 11 Pro\xa0', '5.8in', '144 x 71.4 x 8.1\xa0mm'),
('iPhone 11', '6.1in', '\xa0150.9 x 75.7 x 8.3 mm'),
('iPhone XS Max', '6.5in', '157.5 x 77.4 x 7.7 mm'),
('iPhone XS', '5.8in', '143.6 x 70.9 x 7.7 mm'),
('iPhone XR', '6.1in', '150.9 x 75.7 x 8.3 mm'),
('iPhone X', '5.8in', '143.6 x 70.9 x 7.7 mm'),
('iPhone 8 Plus', '5.5in', '158.4 x 78.1 x 7.5 mm'),
('iPhone 8\xa0', '4.7in', '138.4 x 67.3 x 7.3 mm'),
('iPhone 7 Plus', '5.5in', '158.2 x 77.9 x 7.3 mm'),
('iPhone 7\xa0', '4.7in', '138.3 x 67.1 x 7.1 mm'),
('iPhone 6s Plus\xa0', '5.5in', '158.2 x 77.9 x 7.3 mm\xa0'),
('iPhone 6s', '4.7in', '138.3 x 67.1 x 7.1 mm'),
('iPhone SE / iPhone 5 / iPhone 5s', '4.0in', '123.8 x 58.6 x 7.6 mm')]
Converting the data into a pandas DataFrame
To build a regression model, however, I will need to split the data into proper features. Because the years were not included in the original data, I had to search them and add them myself as an index.
import pandas as pd
df = pd.DataFrame(t)
df.columns = ['model', 'inches', 'size']
df['size'] = df['size'].apply(lambda x : x.replace(' x ', '_')[:-3])
df = pd.concat([df, df['size'].str.split('_', expand=True)], axis=1).drop(['size'], axis=1)
df.columns = ['model', 'inches', 'length', 'width', 'height']
year = [2012, 2014, 2014, 2016, 2016, 2017, 2017, 2017, 2018, 2018, 2018, 2019, 2019, 2019, 2019, 2020, 2020, 2020, 2020]
year.reverse()
df.index = year
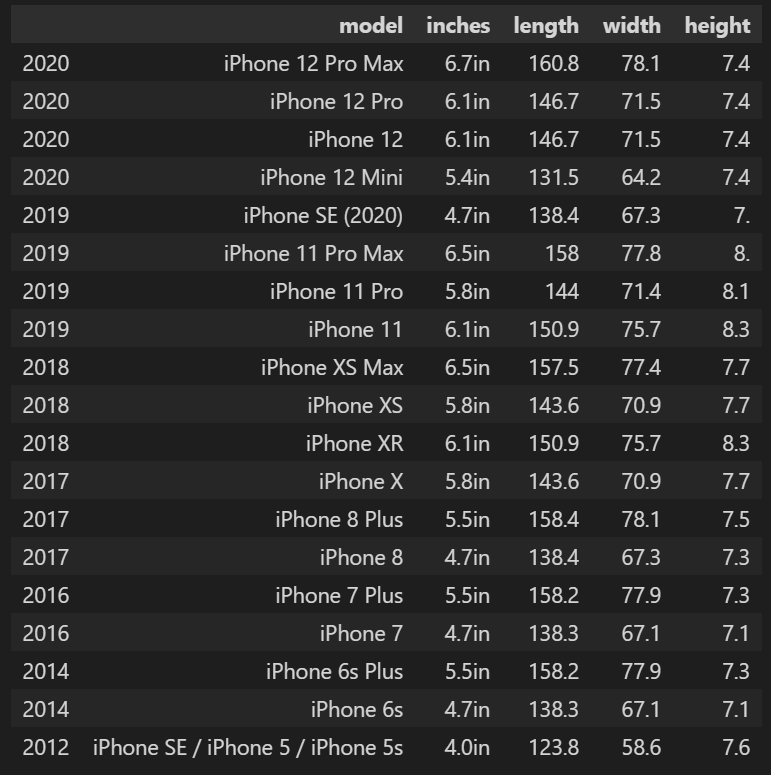
df
In the end, this is the final result:
Visualize trend
The data consists of 3 variables: time, width, and iPhone length. I decided to visualize it plotting it in 3D.

Creating the prediction model
The best approach to make this sort of prediction is using a regression model. I will use the year as a feature, and the iPhone measurements as labels, respectively X and y.
import numpy as np
from sklearn.linear_model import LinearRegression
X, y = pd.DataFrame(df.index), df[['length', 'width']]
reg = LinearRegression().fit(X, y)
reg.score(X, y)
Let us now make the prediction for the year 2700:
reg.predict(np.array([[2700]]))
Output:
array([[1013.11827778, 591.6195 ]])
The iPhone will have reached 1013mm x 592mm, reaching the 1-meter threshold! Outstanding!
By the End of the Year 3000, iPhone Width Will Exceed 1 Meter, AI Predicts was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

