


Building a Classification Model To Score 80+% Accuracy on the Spaceship Titanic Kaggle Dataset
Last Updated on July 17, 2023 by Editorial Team
Author(s): Devang Chavda
Originally published on Towards AI.
This article will walk you through detailed forward feature selection steps and model building from scratch, improving it further with fine-tuning.
Data pre-processing of spaceship-titanic kaggle dataset for achieving 80+% accuracy.
Data cleaning and feature engineering are crucial steps in the data pre-processing pipeline that significantly impact…
medium.com
We will be building a model in 3 trenches:
- Building a model with only numerical features.
- Building a model with only categorical features.
- Building a model with all features combined.
NUMS = ['RoomService', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck','Num',
'Expenditure','Group_size','Expenditure']
TARGET = ['Transported']
# only numerical feature dataframe
nums_df = df[NUMS+TARGET]
df[NUMS].head(3)
Let’s find out which features have the most importance in order to classify a data point, we will be using the forward feature selection method.
Forward feature selection: Step-by-step process of adding features to improve a model’s performance, starting with none, to identify the most relevant ones.
def evaluate_model_kfold_classification(X,y,k,clf):
#kfold base
X = X.fillna(0)
kf = model_selection.KFold(n_splits=k,shuffle=True)
accuracies = []
for fold, (train_index,validation_index) in enumerate(kf.split(X=X)):
train_x = X.loc[train_index].values
train_y = y.loc[train_index].values
validation_x = X.loc[validation_index].values
validation_y = y.loc[validation_index].values
clf.fit(train_x,train_y)
preds = clf.predict(validation_x)
accuracy = metrics.accuracy_score(validation_y, preds)
print(f"Fold={fold}, Accuracy={accuracy}")
accuracies.append(accuracy)
return sum(accuracies)/len(accuracies)
def feature_selection_classification(X,y,k,model):
good_features = []
average_eval_metric = 0 #only positive evalution metrics , loss metric where inverse is good cant work in this code
best_feature= None
for feature in list(X.columns):
score = evaluate_model_kfold_classification(X[[feature]],y,k,model)
if score > average_eval_metric:
best_feature = feature
average_eval_metric =score
print("best feature-->",best_feature)
features = list(X.columns)
features.remove(best_feature)
best_feature_order = [best_feature]
best_feature_order.extend(features)
print("best feature order -->",best_feature_order)
good_features = []
average_eval_metric = 0 #only positive evalution metrics , loss metric where inverse is good cant work in this code
scores_progression = {}
for feature in best_feature_order:
good_features.append(feature)
score = evaluate_model_kfold_classification(X[good_features],y,k,model)
scores_progression['U+007C'.join(good_features)] = score
if score < average_eval_metric:
good_features.remove(feature)
else:
average_eval_metric = score
return good_features,scores_progression
The code performs feature selection for classification. It iterates over features, evaluates their impact on the model, and selects the best ones based on evaluation metrics.
Here I am using logistic regression as my base model to select the best features. Why logistic regression: when we did t-sne analysis on this dataset, we found out that data points are separated in a way where drawing a boundary will be easier,
# here any classification model can be chosen in order to get best features
clf = LogisticRegression()
good_features , score_progression = feature_selection_classification(df[NUMS],df[TARGET],5,clf)
score_progression


Now measure accuracy with all numeric features vs with only good features, which we have derived with feature selection.
print("******************with all features******************")
clf_all = LogisticRegression()
print(evaluate_model_kfold_classification(df[NUMS],df[TARGET],5,clf_all))
print("\n")
print("******************with only good features******************")
clf_good = LogisticRegression()
print(evaluate_model_kfold_classification(df[NUMS],df[TARGET],5,clf_good))
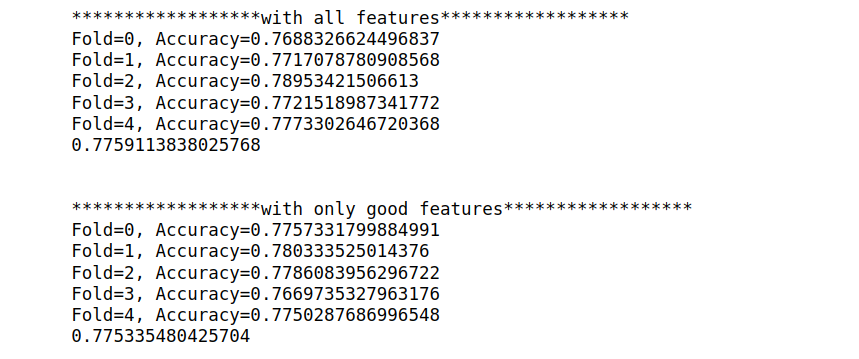
Woohoo!! Our First accuracy score is ~0.78, that’s a good score and can be improved further with fine-tuning or selecting different models.
Let us try out different models to see which one is best suitable for our case.
#different classification models
def get_classification_models():
dtree = tree.DecisionTreeClassifier(random_state=42)
lr = LogisticRegression()
svm_ = svm.SVC()
sgd = SGDClassifier(loss="hinge", penalty="l2", max_iter=5)
knn = KNeighborsClassifier(n_neighbors=3)
naive_bayes = GaussianNB()
gbc = GradientBoostingClassifier()
histgbc = HistGradientBoostingClassifier()
xgboost = XGBClassifier()
lightgbm = LGBMClassifier()
catboost = CatBoostClassifier()
CLASSIFICATION_MODELS = {
'decision_tree' : dtree,
'logistic_regression' : lr,
'support vector machines' : svm_,
'sgd' : sgd,
'knn' : knn,
'gaussian_naive_bayes' : naive_bayes,
'hist_gradient_boosting' : histgbc,
'xgboost' : xgboost,
'light_greadient_boosting' : lightgbm,
'catboost' :catboost
}
return CLASSIFICATION_MODELS
def forward_model_selection_classification(X,y,k):
models = get_classification_models()
for key in models.keys():
print("Classification with --> ",key,"\n")
print(evaluate_model_kfold_classification(X,y,k,models.get(key)))
print('\n')
forward_model_selection_classification(df[NUMS],df[TARGET],5)
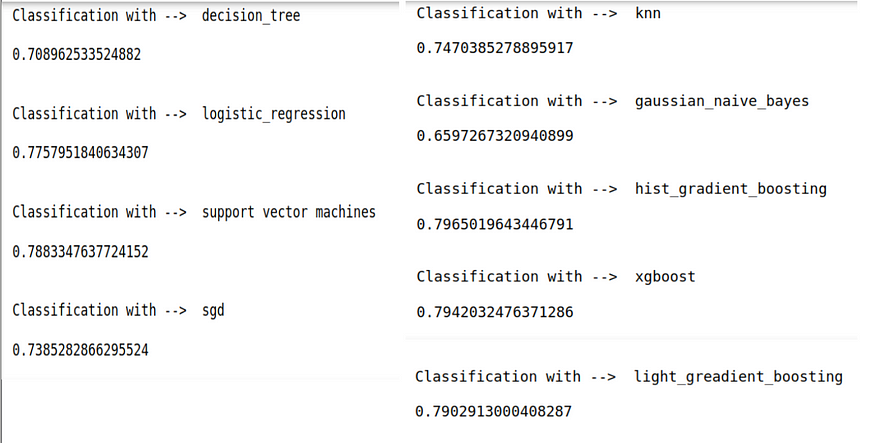
So as we can see here, best-performing models are gradient boosting, LR & svm. Note that we are just using only numeric features, and we have already achieved ~0.79 cross-validation scores for one of the models.
The same function we will also run for only categorical features and see what output we can achieve. But before that, we need to encode categorical features to some numeric values, as some of them contain a string value.
forward_model_selection_classification(df[CATS],df[TARGET],5)

Okay!! This is interesting because categorical features alone are not performing well for most of the models, the most we were able to get was ~0.75.
Lastly, let us try to combine both features and see if we can beat 0.79.
forward_model_selection_classification(df[NUMS+CATS],df[TARGET],5)

WOW !!!! We certainly improved, so the new best score we were able to achieve is ~0.81 for hist gradient boosting.
Can we still improve further ?? YES, we can,
How ??
- we can try fine-tuning best-performing models
- we can try more feature engineering.
- we can choose only good features which can be derived from the forward feature selection method we discussed earlier.
This is it for this article; it all boils down to how much we can experiment patiently and consistently.
The full code for this article can be found here.
ArticleNotebooks/Spaceshi-titanic Article.ipynb at main · devang007/ArticleNotebooks
You can't perform that action at this time. You signed in with another tab or window. You signed out in another tab or…
github.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

