



Billions of Rows, Milliseconds of Time- PySpark Starter Guide
Last Updated on July 25, 2023 by Editorial Team
Author(s): Ravi Shankar
Originally published on Towards AI.
Programming
Intended Audience: Data Scientists with a working knowledge of Python, SQL, and Linux
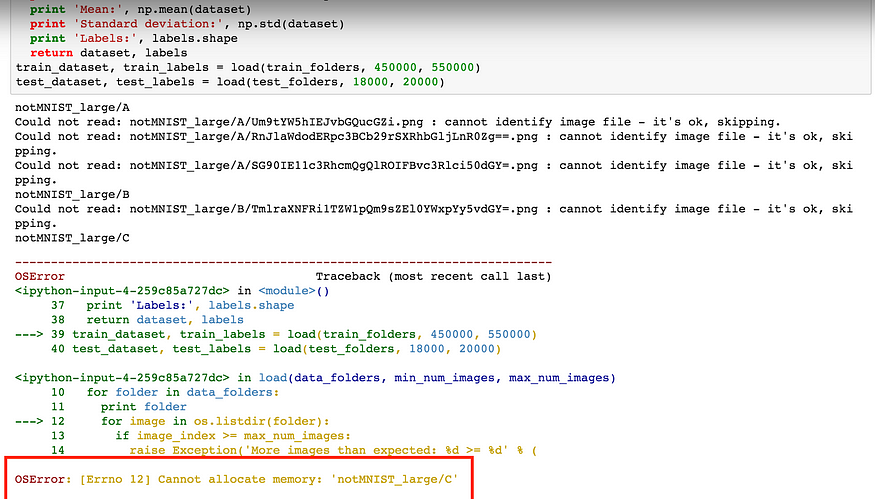
How often we see the below error followed by a terminal shutdown followed by despair over lost work:
Data is the new Oil with a major difference that unlike Oil, data is increasing day-by-day. The increase of the data size is outpacing the speed/cost of RAM upgrades which necessitates the need for smart data handling using multiple cores, parallel processing, chunking, etc.
Follow along and by the end of this article you will:
- Have a running Spark environment on your machine
- Have a basic Pandas to Pyspark data manipulation experience
- Have experience of blazing data manipulation speed at scale in a robust environment
PySpark is a Python API for using Spark, which is a parallel and distributed engine for running big data applications. This article is an attempt to help you get up and running on PySpark in no time!
Comparative performance of varying techniques to read and aggregate from a CSV file(33 Mn Row,5.7GB size):
1. Reading in Chunks(Pandas)mylist = []
for chunk in pd.read_csv('train.csv', chunksize=10000000):
mylist.append(chunk)
train = pd.concat(mylist, axis= 0)
del mylistprint(train.shape)
train.groupby(['passenger_count'])['fare_amount'].mean().reset_index().head(5)Time Taken(2 Mins,25 secs)2. Dasktrain = dd.read_csv('train.csv')
train = client2.persist(train)
progress(train)
print("No of rows is ",len(train))
train.groupby(['passenger_count'])['fare_amount'].mean().reset_index().compute().head(5)Time Taken(18 secs)3. PySparktrain = spark.read.csv('train.csv',header=True)
print("No of rows is ",train.count())
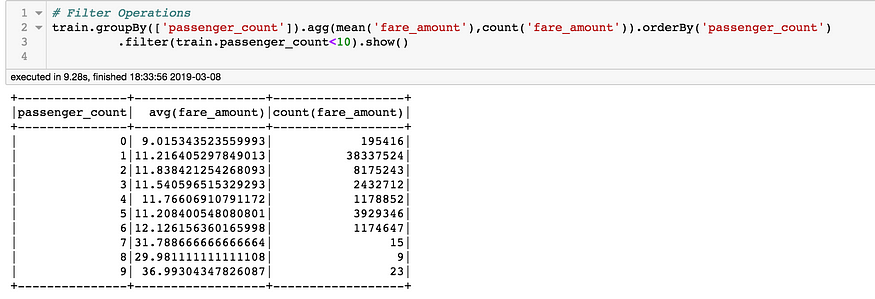
train.groupBy(['passenger_count']).agg(mean('fare_amount'),count('fare_amount')).orderBy('passenger_count').filter(train.passenger_count<10).show()Time Taken(12 Secs)
The major speed advantage of Dask and PySpark is due to the utilization of all the cores of the machine in a Master-Worker Node setup. I will dedicate this post to Pyspark and cover DASK during my future posts and in the meantime, you can read more about Dask at https://docs.dask.org/en/latest/.
Key Advantages of PySpark:
- Implementation of Processes on Multiple cores and thus faster
- Availability of Machine learning and Neural Net Library
- The option of seamless switching between Pandas, SQL, and RDD. SQL operations on Spark Dataframe make it easy for Data Engineers to learn ML, Neural nets, etc without changing their base language.
Let’s install PySpark now (tested on my Mac and EC2(Linux Machine):
a. Install JAVA from https://www.oracle.com/technetwork/java/javase/downloads/jdk11-downloads-5066655.htmlb.Install PySpark from http://spark.apache.org/downloads.html
/pip install pysparkc. Create a symbolic link: ln -s /opt/spark-2.4.0 /opt/spark̀d. Tell your bash where to find Spark:
export SPARK_HOME=/opt/spark
export PATH=$SPARK_HOME/bin:$PATHe. Restart your terminal and type pyspark for a spark environment.

#PySpark on Jupyter Notebookimport pyspark
from pyspark.context import SparkContext
from pyspark.sql.session import SparkSessionsc = SparkContext(('local[30]'))
spark = SparkSession(sc)
spark = SparkSession \
.builder \
.appName("PySpark Sample") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
Now that the stage is set for distributed computing, let's do some data wrangling exercise. I would be using New York Taxi Fare dataset for further analysis: https://www.kaggle.com/c/new-york-city-taxi-fare-prediction
Since it's a big dataset, it doesn’t seem prudent to download it on our home internet/PC. Kaggle has released an API which can be used directly to get the datasets on our Virtual Machines: https://github.com/Kaggle/kaggle-api
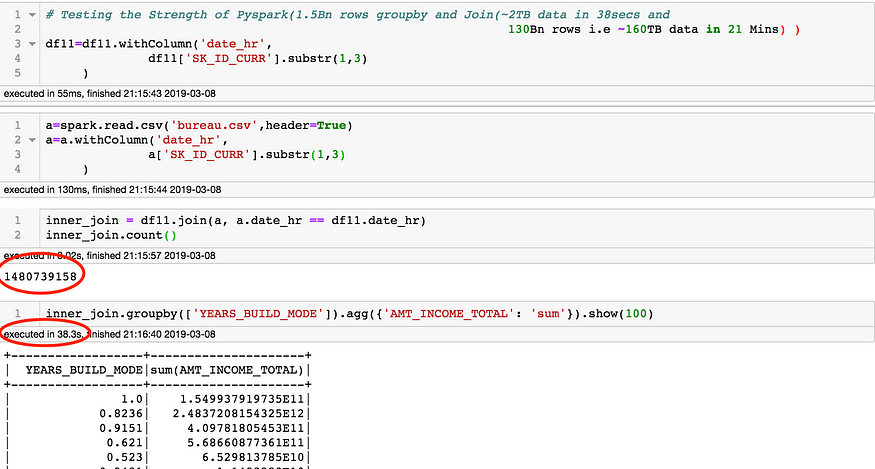
Let's do a quick strength testing of PySpark before moving forward so as not to face issues with increasing data size, On first testing, PySpark can perform joins and aggregation of 1.5Bn rows i.e ~1TB data in 38secs and 130Bn rows i.e ~60 TB data in 21 Mins.
Enough of 30,000 feet Gyaan, let's start with our data manipulations while keeping an eye on the execution time for speed benchmarks:
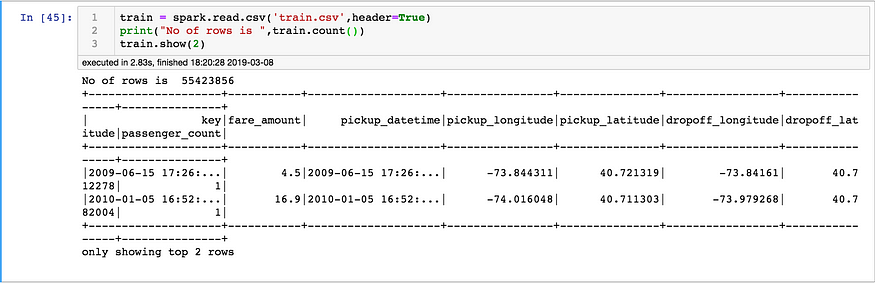
Reading the CSV file:
# Read CSV, length of file and headertrain = spark.read.csv('train.csv',header=True)
print("No of rows is ",train.count())
train.show(2)
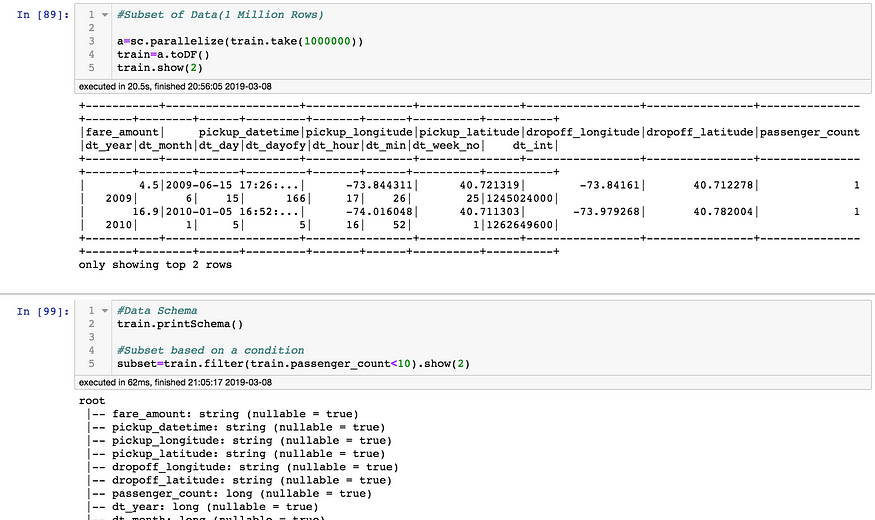
Show Schema, Subset, and Filter:
#Subset of Data(1 Million Rows)a=sc.parallelize(train.take(1000000))
train=a.toDF()
train.show(2)#Data Schema
train.printSchema()#Subset based on a condition
subset=train.filter(train.passenger_count<10).show(2)
Groupby, Sort, and Filter :
# Data Type change
train = train.withColumn("passenger_count",train.passenger_count.cast("integer"))#GroupBy, Rename and Sorttrain.groupBy(['dt_year']).agg(mean('fare_amount'),count('fare_amount')).alias('mean_fare').orderBy('dt_year').show()train.groupBy(['passenger_count']).agg(mean('fare_amount'),count('fare_amount')).orderBy('passenger_count').show()

Create New Columns and change Data Types(Default is a string):
train =train.withColumn("fare",train.fare_amount.cast("float"))
train = train.withColumn("date",train.pickup_datetime.cast("date"))
Custom Functions:
#Custom Function- Haversine Distance between 2 latitudes-Longitudesdf=traindef dist(long_x, lat_x, long_y, lat_y):
return acos(
sin(toRadians(lat_x)) * sin(toRadians(lat_y)) +
cos(toRadians(lat_x)) * cos(toRadians(lat_y)) *
cos(toRadians(long_x) - toRadians(long_y))
) * lit(6371.0)#df=df.head(10)
df2=df.withColumn("distance", dist(
"pickup_longitude","pickup_latitude","dropoff_longitude","dropoff_latitude"
).alias("distance"))df2.select('pickup_datetime','pickup_longitude',
'pickup_latitude','dropoff_longitude','dropoff_latitude','distance').show(5)

Binning:
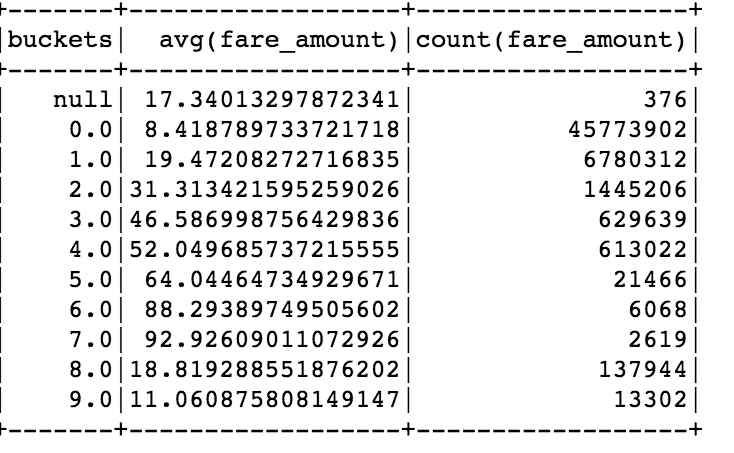
# Binning in Pysparkfrom pyspark.ml.feature import Bucketizerbucketizer = Bucketizer(splits=[ 0, 5, 10,15,20,25,30,35,40,float('Inf') ],inputCol="distance", outputCol="buckets")df2 = bucketizer.setHandleInvalid("keep").transform(df2)df2.groupBy(['buckets']).agg(mean('fare_amount'),count('fare_amount')).orderBy('buckets',asc=False).show(5)
Convert to Pandas and write to CSV:
df2.groupBy(['buckets']).agg(mean('fare_amount'),count('fare_amount')).toPandas().to_csv('Spark_To_Pandas.csv')
SQL operations:
One of the ways of performing operations on Spark data frames is via Spark SQL, which enables data frames to be queried as if they were tables.
#SQL Operations#Convert Spark Data Frame to SQL Tabledf2.createOrReplaceTempView("sql_table")#SQL Query
sql_output = spark.sql("""
select dt_month,pickup_latitude,round(mean(fare_amount),2) as avg_fare
from sql_table
group by 1
order by 1 asc
""")
sql_output.show()
The above post is intended to shed our initial resistance and get started with a technology of the future. I have just managed to scrape the surface and there is a huge potential lying beneath the layers of Distributed Computing. In my next posts, I would write about Text Processing, Machine Learning(MLLib), Graph operations(Graphx), and Neural Nets using Pyspark.
Let me know in the comments if you are facing any issues in setting up the Spark environment or unable to perform any PySpark Operations or even for general chit-chat. Happy Learning!!!
Sources:
- https://medium.com/dunder-data/minimally-sufficient-pandas-a8e67f2a2428
- https://blog.sicara.com/get-started-pyspark-jupyter-guide-tutorial-ae2fe84f594f
- https://towardsdatascience.com/a-brief-introduction-to-pyspark-ff4284701873
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

