



Biased Machines and Where to Find Them
Last Updated on July 24, 2023 by Editorial Team
Author(s): Davor Petreski
Originally published on Towards AI.
Fairness, Ethics
Algorithmic Oppression: Biased Machines and Where to Find Them
Recent events of racial discrimination in law enforcement and the healthcare industry have shown us how biased and racist humans are. The systemic racism that rules over these institutions is evident from police brutality on black people to the denial of hospital treatment of black patients during the pandemic. We all know the countless stories of innocent black people being targeted and killed by the police. In the healthcare industry, for example, the pain of black patients is commonly taken less seriously than that of white patients. All of these failures of the system are due to human racial bias, either conscious or unconscious.
Computers are often perceived as far less biased compared to human decision-making processes. With this in mind, AI algorithms present an appealing opportunity for more equal institutions and less bias. In other words, AI may allow institutions to include the accurate processing of data in their decision making. The application of AI can range anywhere from facial recognition for law enforcement agencies to predicting which patients should get extra medical care in health institutions.
But… are our algorithms fair?
Let’s see.
The idea that algorithms are objective or unbiased is a dangerous one. It is a dangerous one because it can mask systemic discrimination (racism, sexism, you name it…) behind a veil of objectivity. That way, making it more difficult to uncover and oppose discrimination. Secondly, AI-based decisions take the responsibility of decision making away from humans. Holding individual persons accountable for their discriminatory behavior based on algorithmic decision-making processes would be nearly impossible. Lastly, these algorithms are usually the intellectual property of corporations that have profit, rather than the well-being of marginalized citizens as a priority on their agenda.
What is an algorithm?
Let’s cover some of the basics of how some AI algorithms work. This will make it easier for you to follow the rest of the article.
Think of algorithms as cooking recipes for computers. They are specific steps that need to be taken by computers to complete a task. These steps are usually sets of operations that need to be performed by a computer. Because computers are quite ‘narrow-minded’ and don’t like to have broad, open instructions given to them, algorithms have to be comprised of very simple, straight-forward steps. The computer will read and take these steps quite literally. In short, algorithms are the building blocks of any computer program. For example, let’s take your regular maps program, and let’s say you want your phone to get you to an ATM. When you type in “ATM” in the search bar, the map program (app) on your phone uses an algorithm to access your location and find all nearby ATMs. When you select which ATM you want to get to, the app uses an algorithm to calculate possible routes to your destination. Then, in order to choose a specific route, it uses other algorithms to check traffic, estimate times of arrival, see previous routes taken by people like you, etc. Once these steps are done, the app uses a final algorithm that decides which route is best for you given the information provided by the previous algorithms.
OK… Then what is AI?
In recent years, we have improved some algorithms so much, that they do a better job then most (if not all) humans. Take AlphaGo as an example, a computer program that has defeated the Go world champion, and is arguably the best Go player ever. There are many different algorithms that fall under the umbrella of AI (Artificial Intelligence), but generally, any program that can perform tasks normally performed by humans, and self-improve over time can be considered AI. Machine and Deep Learning (ML & DL)algorithms take AI a step further, where algorithms are able to process and learn from massive datasets. These algorithms are powerful tools that can provide insights and make accurate decisions based on the huge amounts of information. Something that no human brain can do. There are several notable applications of AI. Some of them you have probably come across:
- Computer Vision — Algorithms used in self-driving cars, facial recognition programs, image recognition, etc.
- Text AI — Speech and Text recognition, Speech-to-Text conversion, etc.
- Analytic AI — Risk or needs assessment algorithms, sentiment analysis (interpretation and classification of emotions based on behavioral and text data), etc.
- Interactive AI — Chatbots, Personal Assistants (Siri, Alexa…), etc.
As you can see, AI-based algorithms are all around us. Some, one could argue, are the building blocks of our modern world. As such, they hold a great amount of power over our everyday lives.
So, which decisions are AI-based algorithms making for us? How are these decisions biased?

Law Enforcement
AI has many implications in Law Enforcement. Computer vision algorithms can be used for facial recognition of criminals, monitoring public areas, and predicting/detecting suspicious behavior, or identifying persons with firearms or cold weapons in a crowded place. Analytic AI can help assess the risk of re-offense by a convict or analyze evidence.
These applications all seem ambitious and noble pursuits, at first sight, however, recent cases have shown that they are just an extension of the systemic racism that goes on in law enforcement agencies.
Analytic AI
COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) is a decision support tool that is used by U.S. Courts. COMPAS uses algorithms to assess the risk of a defendant re-offending. These algorithms use a questionnaire and multiple other data entries about the defendant to calculate the risk of recidivism. On a large scale, the predictions made by the algorithm proved to be quite accurate. Well… except for one part. The algorithm turned out to be racially biased.
ProPublica, an investigative journalism newsroom, has thoroughly researched COMPAS. When data from white and black defendants were compared in their research, it turned out that black defendants were twice as likely to be misclassified as re-offenders. On the other hand, white re-offenders were mistakenly classified as ‘safe’ (not likely to re-offend), twice as often as their black counterparts.
Here’s one example of their findings:
The violent recidivism analysis also showed that even when controlling for prior crimes, future recidivism, age, and gender, black defendants were 77 percent more likely to be assigned higher risk scores than white defendants.
The results of the COMPAS analysis show something that has been a grim tradition in the US justice system and law enforcement. If you’re black, you’re much more likely to be ‘mistakenly’ convicted, classified as a potential re-offender, or killed by the police. Systemic racism runs deep into our institutions. And COMPAS has shown that it’s so deep, that even machines have a racist bias creeping within them.
Computer vision
Facial Recognition, and Image labeling and recognition algorithms can be used to keep property and the public safe. For example, using facial recognition, a law enforcement agency can use public cameras to recognize and track the movement of a specific person of interest (e.g. suspected terrorist, criminal, etc.). With image labeling and recognition, they can further track their actions. For example, an image recognition algorithm may detect a possible weapon or a bomb-building material in the hands of the person of interest.
That being said, these technologies exponentially increase the power of surveillance. It’s worrisome that these same technologies that might be used for keeping us safe, can be also used to control us.
Nonetheless, let’s focus on the positive application of these technologies — keeping us safe. Will they keep us all safe equally? Or will racial minorities suffer cruel consequences for the comfort and safety of all?
Facial Recognition
There are two common applications of facial recognition. One-to-one matching, which is matching a person’s face with a photo of the same person in a database. And one-to-many matching, which determines whether a face has a match in a database. The former can be used as a tool for checking passports on borders, and the latter can be used to identify suspects in an investigation, to single out a criminal or a suspect from a crowd using cameras in public spaces, etc.
The US National Institute of Standards and Technology (NIST), tested multiple (almost 200) facial recognition algorithms based on both one-to-one and one-to-many matching. The study concluded that most facial recognition systems proved to have worse performance on nonwhite faces. Here are some of the main findings:
- For one-to-one matching, most systems had a higher rate of mistakes for African American faces, compared to Caucasian faces (ranging from a factor of 10 to 100). Meaning that some facial recognition systems were 100 times more likely to mistakenly find a match of an African American face when there isn’t one.
- US-developed one-to-one algorithms all had consistently high rates of false positives (mistakes) for African American, Asian, and Native American faces. The algorithms performed worst on Native American faces.
- For one-to-many matching, the highest rates of false positives were for African American females.
Why is this important?
Well… the studies, basically suggest that these computer vision algorithms contain a racial bias. In the first case, this may cause discrimination on border patrols. For example, increased false positives on passport control systems in the case of African and Native Americans may cause individuals of these groups to be a subject of frequent “random checks”, just like people of Middle Eastern background are post 9/11. This sort of racial bias may also cause businesses and devices owned by individuals of these groups to be less secure and more easily accessible.
The more concerning case is that of errors one-to-many matching algorithms. The results here suggest false positives for people of African American heritage, especially African American females. This puts this population at the highest risk of false criminal accusations and false arrests. These discriminatory algorithms, mixed with the already anti-black behavior of law enforcement agencies only will lead to more unfairness and bloodshed.
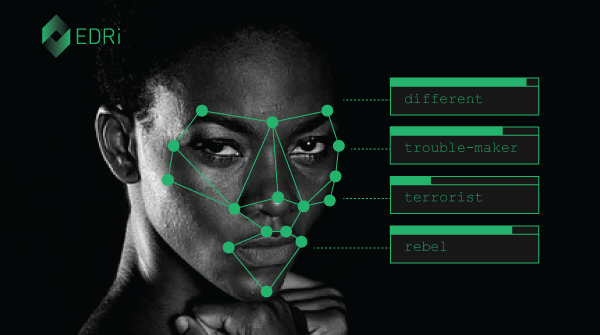
Just a side note:
The racial bias in computer vision algorithms is concerning. However, it is just half of the work. These algorithms are powerful tools that can lead to a 1984-esque surveillance police state. So we should be even more careful and skeptical towards the application of these technologies.
Image Recognition and Labeling
Image recognition and Labeling algorithms look at a photo and recognize and label objects in that picture. One of the most commonly used Image Labeling programs is Google’s Cloud Vision AI. This tool is amazing. For example, here’s the output of Google’s vision API when presented with a random picture.
Input (the image):

Output:
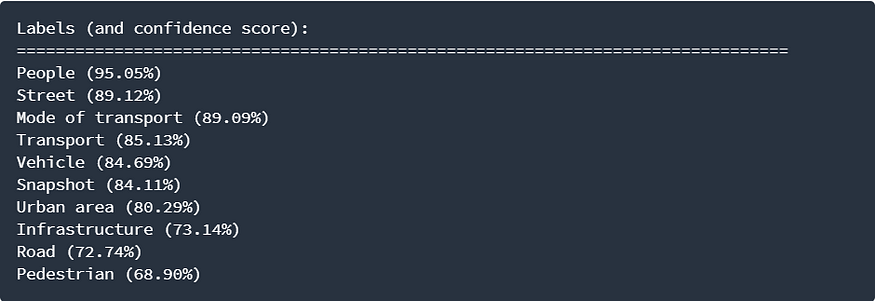
Pretty cool stuff!
Well… not so fast. It turns out, this algorithm is racist too. In a quite well-known experiment by AlgorithmWatch, more specifically by Nicolas Kayser-Bril, Google Vision mislabeled a thermometer in a dark-skin hand as a gun. The same image, and the same object, just with a light-skin hand was labeled as ‘tool’ or as a ‘monocular’.
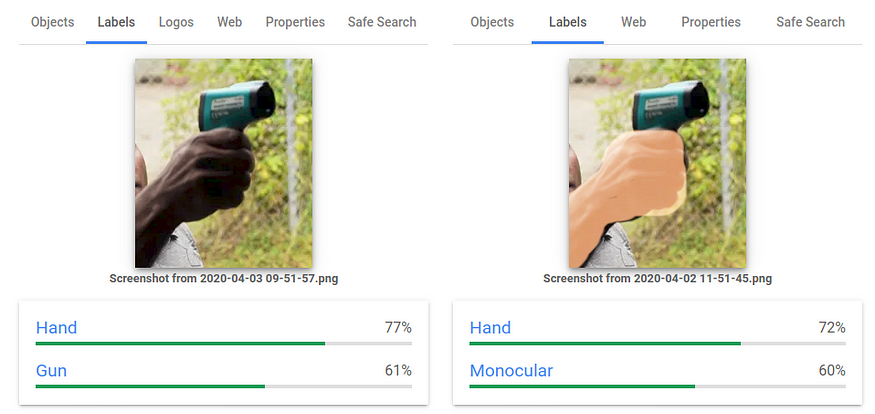
Google fixed the issue and apologized, but one can only wonder how many of these cases of racial bias are there.
Why is this case important?
Imagine these computer vision algorithms being used in the case of law enforcement. Using a camera put in a public space (like a mall), an algorithm matches an innocent black individual with someone from the criminal database. Another algorithm misidentifies the hair drier they just bought in their hand as a gun. You can finish the rest of the story yourself. More often than not, coupled with the racial biases already existing in humans, this story ends with another innocent black person killed or brutally injured by the police.
Healthcare
AI has many revolutionary applications in medicine such as bioinformatics, but for now, let’s focus on the management and social side of healthcare. In healthcare, Analytic AI is often used to calculate certain health risks of a patient or to determine whether a patient needs extra attention paid by healthcare staff. This way, the algorithm allows to divert resources and staff where needed and successfully manage time and resources to improve care for patients and reduce costs.
I am guessing you won’t be surprised by this point, but it turns out some of these algorithms are racially biased too. In 2019, a study published in Science analyzed one of the popular decision-making software used in US hospitals. The analysis showed that this software has been discriminating against black patients systematically. In fact, the software assigned black patients lower risk scores compared to equally sick white patients. Thus, black patients were less likely to receive personalized care. Using this algorithm, the care provided to black people cost $1800 less than that of white people who had similar health problems. Another interesting finding is that only 18% of the patients that were assigned ‘extra-care’ by the algorithm were black. If the algorithm was unbiased, this number would’ve been around 47%.
The manufacturer of the algorithm remains anonymous. However, Obermeyer and his team are working with them to improve the program and reduce bias.
Public life and Media
Twitter, Facebook, Youtube, and I guess the internet in general, is full of offensive hate speech. Thankfully, many of these social media companies are actively working on developing AI models that can effectively detect and flag hate speech, so it’s dealt with quickly. The technology that these companies used are algorithms that use natural language processing.

The irony here is that these algorithms that are intended to eliminate hate speech and racial discrimination online end up amplifying racial bias. For example, Maarteen Sap and his colleagues studied PerspectiveAPI. A machine learning program developed by Google to detect and flag hate speech online. Sap ran this program on a database of thousands of tweets and looked for racial bias in the detection of hate speech. Unsurprisingly, he found that tweets by black people were two times more likely to be labeled as offensive. This is due to the fact that these algorithms don’t have the specific context in mind and don’t take the dialect and the race of the writer as deciding factors. In other words, these algorithms are trained based on standard English, and often dialects, such as African-American English (AAE)are discriminated against.
This is just one of many examples of AAE being flagged and black social media users being banned for expressing themselves in their dialect. For example, see the case of Mary Canty Merrill, who discussed racism in some of her Facebook posts, just to see her profile banned and her posts deleted the next day. She then sent the same text that she was banned for some of her white friends. When they posted the text, Facebook allowed the content on their platform.
These cases are important to pay attention to because they can play a role in the systemic silencing of black voices online. Further, treating African-American English as offensive and restricting it, may lead to unwanted cultural assimilation and domination of standard (read: white, middle class) English on platforms for public discussion.
These are just some examples of algorithmic racial discrimination. This also happens in algorithms used for school admissions, employment, bank loans, etc. Usually, biases in algorithms have many layers: gender, sexual orientation, ethnicity, socio-economic status…
Why is this happening?
The developers of these algorithms are not mean spirited people that intentionally install racial bias in these algorithms. Obviously, humans are prone to errors and they are part of the algorithmic bias problem, but there are a couple of other reasons. Let’s see how racial bias creeps into algorithms.
You are what you eat — Data
AI algorithms that use Machine and Deep learning are trained on data. In other words, the algorithms learn how to complete a certain task by using data that is given to them as a ‘training set’. A simple way to explain why some algorithms are racially biased is to look at the data. For example, it wouldn’t be a surprise that an algorithm has racial bias if it used data from the U.S. criminal justice system.
This resembles a saying we often use for people: “You are what you eat”. Machine Learning algorithms are the same. If you train them with racially biased data, they will turn out racist.
Bias can creep into data in two ways: if the training data doesn’t represent the real situation or if the data has already existing prejudices. In the first example, a certain group may be misrepresented or completely neglected in the data. For example, if a face recognition algorithm is given predominantly white, male faces in the training data set, of course it will struggle with faces of black women. In the second case, the data itself may be corrupted. For example, if an algorithm is given datasets of incarceration through the U.S. justice system, the algorithm will reflect the systemic racism that leads to mass incarceration of black males. A similar example can be present in algorithms used for hiring and auditing job applicants. If the algorithm uses previous hiring data by humans where mostly white men were favored, it might unjustifiably dismiss women or black men.
Data seems to be a big chunk of the problem, however, it’s just the beginning. Some issues arise even before the data is collected.
It’s not all in the Data, there’s some design to it
It’s not only the data that is biased, but there’s racial bias at the beginning of the process of constructing these algorithms. In the design. The first thing developers do when creating an algorithm is decide on what the goal of the algorithm is. The goal and the task of an algorithm are different. For example, a navigation algorithm (like Google Maps) has the goal to find the ‘best’ route from point A to point B. What is ‘the best route’, is what defines the task. So the goal might be to find you the quickest way to get to a place, or the shortest one in distance, or maybe the most economic one. Obviously, in this case, deciding on what’s the best route can be easily left up to users’ preferences. However, often, developers can’t shift this decision to the users. The goal has to be converted into something that can be computed. In private for-profit companies, this goal is usually to maximize profit or to maximize what essentially is customer satisfaction. For example, if a resource management software for a healthcare company is designed to maximize profit, and if it figures out that undermining the seriousness of an illness in black patients and providing black patients with fewer resources is a way to maximize profit, it will end up systematically discriminating against black patients.
One quite famous instance is the ‘creditworthiness’ example proposed by Selbst and Barocas. Where if an algorithm was designed to calculate ‘creditworthiness’ in order to maximize profits, it would end up getting into some sketchy, illegal loaning practices (predatory and subprime loans).
So… even in the hypothetical (impossible) case where our data is free of bias, the design of the goal/the problem that the algorithm is trying to solve may be formulated in a way that is problematic and perpetuates discrimination or unethical practices.
Well… If the problem is data and design, why don’t we improve that?
The Black Box — Transparency
How I (most of us) find out about these biases in algorithms is through the work of researchers or just people exposing unfair algorithmic results through simple comparisons. Both cases are extremely rare. They are rare because there is a lack of transparency in the field.
Algorithms are usually the property of private companies. As such, how they work and what data was used, is usually kept secret. Often, they are essentially black-box machines where we can’t see the inner-workings but we can only see the result it yields. Because researchers only have access to the results, they have a really hard time studying these algorithms, identifying where does the bias lie, and improving their biases. This is because the creators of these algorithms do not want to allow outsiders to have access to them. Mainly because that would be a threat to their profit (e.g. the algorithm could be compromised or copied by competitors, harsh public critiques, etc.). But if we don’t have access to these algorithms that affect us, how can we test them and improve their biases?
Accountability
To identify biases and improve algorithms, seeking transparency from companies is an important step.
However, if we want a true anti-bias change in the AI landscape, we are ought to seek accountability from those who develop and apply racially biased algorithms.
Since we already know that the ‘perfectly unbiased’ algorithm doesn’t exist, we shouldn’t be punishing companies for creating biased algorithms. Instead, we should be demanding from them proof of consistent testing for biases, the use of ‘unbiased’ data(as much as this is possible), and responsibility for constant improvement of the algorithms. By improvement of the algorithms, I don’t mean improvements in the speed or functionality of the algorithm, but a constant pursuit of the quest to make them less biased.
In other words, we have to push for policy that holds companies accountable for their algorithms. We have to push for checks for bias, third-party auditors and evaluators, tests on how the algorithm works with different demographics, and sharing and questioning the data used for training and testing the algorithms.
What can you/we do?
By now, you must be a bit overwhelmed, maybe frustrated even, hopefully asking yourself: What can I do to change this?
Just like any form of discrimination, algorithmic discrimination, especially when it’s systemic is difficult to dismantle and ‘fix’. It’s a process that needs to be approached from multiple angles simultaneously. The good news is, there are already many smart AI researchers, developers, and activists already working on the problem. The fight for algorithmic fairness can take multiple angles: through research and improvement, legislature and policy, inclusion, and discussion.
Research and Improvement
At the forefront of the fight against algorithmic bias are our researchers. They are the ones picking out algorithms, checking for bias, recommending improvements, and pushing the issue forward. How can you help in this domain?
Well… if you are a researcher, keep on doing what you’re doing. You rock!
If you’re not a researcher, but you’re interested, you can take an online course to get yourself acquainted with the topic. Then, you can start playing around with the results of some interesting algorithms you identified, see if there’s a suspicion of bias. If there is, dig a bit deeper, ask other researchers for help, contact the creators and share your findings. Often, algorithms are exposed by their users doing experiments on them.
For example, Joy Buolamwini exposed racist facial recognition algorithms that are biased towards black women. She also made a touching video on the topic.
If you want to help researchers, you can also support them by participating in their studies or donating to support their efforts. For example, a research non-profit organization that you can donate to, support and follow is AlgorithmWatch.
Legislature and Policy
To hold companies and institutions accountable, and seek transparency we need proper legislature on AI. We need legislatures and policies to have the people’s best interest in mind, to minimize bias and to promote fairer outcomes and the social responsibility aspect of AI. The good news is that some policymakers and representatives have already worked and proposed bills, policies and laws that we can support and influence.
If you are a U.S. citizen then you can contact your representatives regarding these laws:
- H.R.2231 — Algorithmic Accountability Act of 2019 — This bill would require companies to check their AI systems for bias
Facial recognition:
- S. 2878: Facial Recognition Technology Warrant Act of 2019
- H.R. 3875: To prohibit Federal funding from being used for the purchase or use of facial recognition technology, and for other purposes.
- S. 847: Commercial Facial Recognition Privacy Act of 2019
You can also contact your congressmen to raise awareness about these issues. Here’s a ‘guide’ on contacting your representatives by the New Yorker. There are probably other laws in the loop that I am not aware of, if you know of some, please let me know and I will add them on here.
If you are a citizen of the European Union, you can contribute and give your opinion on the European Artificial Intelligence Whitepaper. Do it, by going to this link.
These are just a few examples, that I am aware of. Feel free to contact me if you have more of these and I can add them here. Make sure you do your own research related to your community and country.
Inclusion
An issue in the AI industry is that the majority of the people in the field are white males. The under-representation of women and people of color in the industry leads to an under-representation of their concerns. Which then leaves AI algorithms to disproportionately, negatively affect these demographics. There are two types of inclusion or rather representation we should be fighting for in AI.
- The representation of women and people of color (preferably both) in the processes of design, development, and governance of AI.
e.g. less than 2% of employees in big tech companies like Google and Facebook are black - The representation of these groups in the data.
e.g. in a sample data set found by Buolamwini, only 25% of the individuals in the data sets were man, and over 80% were light-skinned.
It’s also not only about including marginalized people as developers or engineers. Tech companies should hire individuals with degrees in Liberal Arts (Social Sciences and Humanities). These individuals should then partner with engineers. It is unfair of us to expect engineers to know about society, racial and gender-based biases as much as someone that has studied critical theories.
You can support programs and projects that promote the engagement of marginalized groups in tech. Specifically, for the field of AI, you can support:
Discussion and awareness
Educating each other, storytelling, sharing our opinions and emotions through constructive dialogue is one of our most powerful tools for change. Technical and policy changes can improve AI and make it more biased, but art and conversations tell us why this matters, they show that experiences of marginalized people matter. Through dialogue, we can challenge existing systemic oppression, share each other’s stories and emotions, motivate each other, and foster change. Education here is extremely important, and it’s a two-way street. On one hand, developers and people with a background in AI are ought to educate themselves about the moral and societal implications of their work. On the other, people in the Social Sciences and Humanities, critical theorists, and activists should educate themselves on the basics of algorithms, how they work, how are they built, and applied. Only through education we can understand each other and lead to constructive, change inspiring conversations.
Short list of resources to educate yourself and others, people to follow, and organizations to support
This list is of resources, organizations, and people I am well acquainted with. There are a lot more out there. Explore!
Things to read/watch:
- Race After Technology Abolitionist Tools for the New Jim Code by Ruha Benjamin
- Joy Buolamwini Masters’s thesis: Gender Shades: Intersectional Phenotypic and Demographic Evaluation of Face Datasets and Gender Classifiers
- Algorithms of Oppression How Search Engines Reinforce Racism by Safiya Umoja Noble
- Getting Specific About Algorithmic Bias, a talk by Rachel Thomas
- Diversity Crisis in AI, 2017 edition by Rachel Thomas for fast.ai
- Data racism: a new frontier by Sarah Chander — This is a more Europe focused article
- “Uncovering Bias in Machine Learning” by Ayodele Odubela — this book is yet to be released next fall, you can sign-up for pre-order notifications here.
Organizations to support:
- Algorithmic Justice League — They have displayed a couple of ways that you can help them out, so make sure you check out their website
- Black in AI — Black in AI on twitter — Inclusion focused
- AlgorithmWatch — Research focused
- AI for People — Policy focused
- AI4ALL — Inclusion focused
- Digital Freedom Fund — a general digital rights organization based in Europe
People to follow:
- Joy Buolamwini
- Ruha Benjamin
- Safiya Umoja Noble
- Fei-Fei Li
- Nani Jansen Reventlow
- Frank Pasquale
- Meredith Broussard
- Ayodele Odubela
Published via Towards AI
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

