



Automating Zero-Shot Classification Generating Model Labels with GPT-3
Last Updated on April 6, 2023 by Editorial Team
Author(s): Carlo Borella
Originally published on Towards AI.
Zero-shot learning is a machine learning method that allows using a pre-trained model to classify data according to a set of classes or labels that have not been used to train the model. Zero-shot can be useful for various applications including:
- labeling data without spending time training or fine-tuning a model
- labeling data because we don’t have a training set to train or fine-tune a model
Traditionally, creating labels for a Zero-shot Classification task involves manually defining a set of potential classes or labels that the model can use to make predictions on the unseen data. This process can be time-consuming and error-prone, particularly for large datasets or complex domains.
By using OpenAI’s GPT-3 to generate labels for Zero-shot Classification models, we can significantly reduce the time and effort required to create this set of labels!
In this article, I will show how to build a zero-shot text classification model, integrating OpenAI’s GPT-3 for label creation (i.e., coming up with a set of labels relevant to the data we want to categorize) and HuggingFace zero-shot models for the actual text classification (i.e., classifying the data according to this set of labels).
To get started, we will need to install transformers and openai and import all the necessary modules:
!pip install transformers
!pip install openai
from transformers import pipeline
import torch
from tqdm import tqdm
import pandas as pd
import openai
import requests
We will also need to initialize the OpenAI API client with our API key:
openai.api_key = ("your key") #replace with your key
Now that we have the necessary packages and API key, let’s define (1) a function to generate labels relevant to the corpus of texts we want to classify and (2) a function to classify the corpus based on the set of labels previously defined.
(1) First, define a function to generate the labels we will feed to our zero-shot classification model:
def get_zero_shot_labels(domain, n_labels = None):
if n_labels is None:
prompt = 'You are picking the labels for a zero shot classification model, Generate a list of themes for the domain: {}'.format(domain)
else:
prompt = 'You are picking the labels for a zero shot classification model, Generate a list with a minimum of {} themes for the domain: {}'.format(n_labels, domain)
response = openai.Completion.create(
engine="text-davinci-002",
prompt=prompt,
max_tokens=40,
n=1,
stop=None,
temperature=0.5,
)
text = response["choices"][0]["text"]
labels = [label.strip('-') for label in text.split('\n')]
return(labels)
This function uses GPT-3 (alternatively, you can use GPT-4) to generate a set of labels relevant to the specified domain we are interested in.
get_zero_shot_labels has two inputs:
domainis a string containing the description of the relevant domain for the data we will feed to the zero-shot classification model (e.g., restaurant reviews, football news, etc.)n_labelsis the minimum number of labels that we want to generate. Ifn_labelsis not specified, the function will generate an unspecified number of labels for the specifieddomain.
(2) Next, we will define a function to classify our input data based on the list of possible labels we previously created with get_zero_shot_labels:
def zero_shot_classification(text_lst, labels ,model, multi_label = False):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
classifier_pipeline = pipeline("zero-shot-classification", model = model, multi_label = multi_label, device=device)
preds = []
#loop for each text in text_list
for input_sequence in tqdm(text_lst, total=len(text_lst)):
pred = classifier_pipeline(input_sequence, labels)
label_scores = dict(zip(pred['labels'], pred['scores']))
preds.append(label_scores)
#store the labels probabilities in a df
preds_df = pd.DataFrame(preds)
return(preds_df)
The function has 4 inputs:
text_lst: A list of strings representing the data to be classified.labels: the set of labels to classify the data accordingly.model: A string that represents the zero-shot classification model to use.multi_label: A boolean flag indicating whether the model should output multiple labels per input sequence.
Once we have our label generator function and the function to classify texts, we can combine the two into an end-to-end zero-shot classifier with little human input.
So now it is time to put them together: end_to_end_zero_shot combines the label generation code with the text classifier to provide an end-to-end solution for Zero-shot text classification:
def end_to_end_zero_shot(domain, text_lst , n_labels =None , model = "valhalla/distilbart-mnli-12-3", multi_label = False):
labels = get_zero_shot_labels(domain, n_labels = n_labels)
print(labels)
user_input = input("proceed with these labels (yes/no)").lower()
if user_input == "yes":
preds_df = zero_shot_classification(text_lst, labels ,model, multi_label = multi_label)
return(preds_df)
else:
print('modify your prompt and/or retry.')
return(labels)
I am using “valhalla/distilbart-mnli-12–3”, which is a distilled version of bart-large-mnli (it runs faster), as my default model, but you can try it with others.
In the function, I also included user_input prompting the user to examine the labels proposed by GPT before proceeding with labeling the corpus.
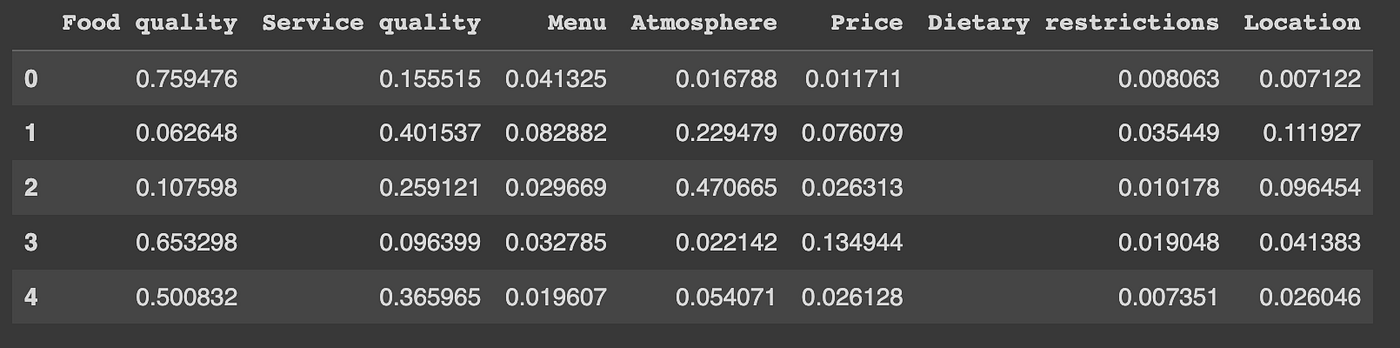
Finally, here is an example:
domain = 'restaurants reviews'
text_lst = [ "The food was amazing!",
"The service was slow and the staff was unfriendly.",
"The ambiance was perfect for a romantic dinner.",
"The prices were too high for the quality of the food.",
"I highly recommend this restaurant!"]
results = end_to_end_zero_shot(domain, text_lst , n_labels =None , model = "valhalla/distilbart-mnli-12-3", multi_label = False)
['Food quality', 'Service quality', 'Price', 'Atmosphere', 'Location', 'Menu', 'Dietary restrictions']
proceed with these labels (yes/no)yes
100%|██████████| 5/5 [00:09<00:00, 1.85s/it]
End Note
In this article, we discussed how to implement a Zero-shot text classification algorithm automating the label generation process using GPT-3 (or GPT4, even better!). For this implementation, I am assuming that the corpus we are labeling belongs to a given domain (therefore, the labels produced by GPT-3 will be relevant)
I appreciate any feedback and constructive criticism! My email is carbor100@gmail.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


